
Emerging Talent: Winternship 2020 Highlights
The Trail of Bits Winternship is our winter internship program where we invite 10-15 students to join us over the winter break for a short project that has a meaningful impact on information security. They work remotely with a mentor to create or improve tools that solve a single impactful problem. These paid internships give student InfoSec engineers real industry experience, plus a publication for their resumé—and sometimes even lead to a job with us (congrats, Samuel Caccavale!).
Check out the project highlights from some of our 2020 Winternship interns below.
Aaron Yoo—Anvill Decompiler
UCLA
This winter break I added a tool to the Anvill decompiler that produces “JSON specifications” for LLVM bitcode functions. These bitcode-derived specifications tell Anvill about the physical location (register or memory) of important values such as function arguments and return values. Anvill depends on this location information to intelligently lift machine code into high-quality, easy-to-analyze LLVM bitcode.
A typical specification looks something like this:
{
"arch": "amd64",
"functions": [
{
"demangled_name": "test(long, long)",
"name": "_Z4testll",
"parameters": [
{
"name": "param1",
"register": "RDI",
"type": "l"
},
...Overall, I had fun learning so much about ABIs and using the LLVM compiler infrastructure. I got to see my tool operate in some sample full “machine code to C” decompilations, and overcame tricky obstacles, such as how a single high-level parameter or return value can be split across many machine-level registers. My final assessment: Decompilers are pretty cool!
Paweł Płatek—DeepState and Python
AGH University of Science and Technology
The main goal of my winternship project was to find and fix bugs in the Python part of the DeepState source code. Most of the bugs I found were making it nearly impossible to build DeepState for fuzzing or to use the fuzzer’s executors. Now, the build process and executors work correctly, and have been tested and better documented. I’ve also identified and described places where more work is needed (in GitHub issues). Here are the details of my DeepState project:
Cmake—Corrected build options; added the option to build only examples; added checks for compilers and support for Honggfuzz and Angora; improved cmake for examples (so the examples are automatically found).
Docker—Split docker build into two parts—deepstate-base and deepstate—to make it easier to update the environment; added multi-stage docker builds (so fuzzers can be updated separately, without rebuilding everything from scratch); added –jobs support and Angora.
CI—Rewrote a job that builds and pushes docker images to use GitHub action that supports caching; added fuzzer tests.
Fuzzer executors (frontends)—Unified arguments and input/output directory handling, reviewed each fuzzer documentation, so executors set appropriate runtime flags, reimplemented pre- and post-execution methods, added methods for fuzzers’ executables discovery (based on FUZZERNAME_HOME environment variables and CLI flag), reimplemented logging, fixed compilation functions, rewritten methods related to fuzzer’s runtime statistics, reimplemented run method (so that the management routine that retrieves statistics & synchronize stuff is called from time to time and that exceptions are handled properly; also added cleanup function and possibility to restart process), examined each fuzzer directory structure and seed synchronization possibilities and, based on that, implemented fuzzers resuming and fixed ensembling methods.
Fuzzer testing—Created a basic test that checks whether executors can compile correctly and whether fuzzers can find a simple bug; created test for seed synchronization.
Documentation—Split documentation into several files, and added chapters on fuzzer executor usage and harness writing.
Philip Zhengyuan Wang—Manticore
University of Maryland
During my winternship, I helped improve Manticore’s versatility and functionality. Specifically, I combined it with Ansible (an automated provisioning framework) and Protobuf (a serialization library) to allow users to run Manticore in the cloud and better understand what occurs during a Manticore run.
As it stands, Manticore is very CPU-intensive; it competes for CPU time with other user processes when running locally. Running a job on a remotely provisioned VM in which more resources could be diverted to a Manticore run would make this much less of an issue.
To address this, I created “mcorepv” (short for Manticore Provisioner), a Python wrapper for Manticore’s CLI and Ansible/DigitalOcean that allows users to select a run destination (local machine/remote droplet) and supply a target Manticore Python script or executable along with all necessary runtime flags. If the user decides to run a job locally, mcorepv executes Manticore analysis in the user’s current working directory and logs the results.
Things get more interesting if the user decides to run a job remotely—in this case, mcorepv will call Ansible and execute a playbook to provision a new DigitalOcean droplet, copy the user’s current working directory to the droplet, and execute Manticore analysis on the target script/executable. While the analysis is running, mcorepv streams logs and Manticore’s stdout back in near real time via Ansible so a user may frequently check on the analysis’ progress.
Manticore should also simultaneously stream its list of internal states and their statuses (ready, busy, killed, terminated) to the user via a protobuf protocol over a socket in order to better describe the analysis’ status and resource consumption (this is currently a work in progress). To make this possible, I developed a protobuf protocol to represent Manticore’s internal state objects and allow for serialization, along with a terminal user interface (TUI). Once started on the droplet, Manticore spins up a TCP server that provides a real-time view of the internal state lists. The client can then run the TUI locally, which will connect to the Manticore server and display the state lists. Once the job has finished, the Manticore server is terminated, and the results of the Manticore run along with all logs are copied back to the user’s local machine where they may be further inspected.
There’s still some work to be done to ensure Manticore runs bug-free in the cloud. For example:
- Port forwarding must be set up on the droplet and local machine to ensure Manticore’s server and client TUI can communicate over SSH.
- The TUI needs additional optimization and improvement to ensure the user gets the right amount of information they need.
- Mcorepv and its Ansible backend need to be more rigorously tested to ensure they work properly.
I’m glad that in my short time at Trail of Bits, I was able to help move Manticore one step closer to running anywhere, anytime.
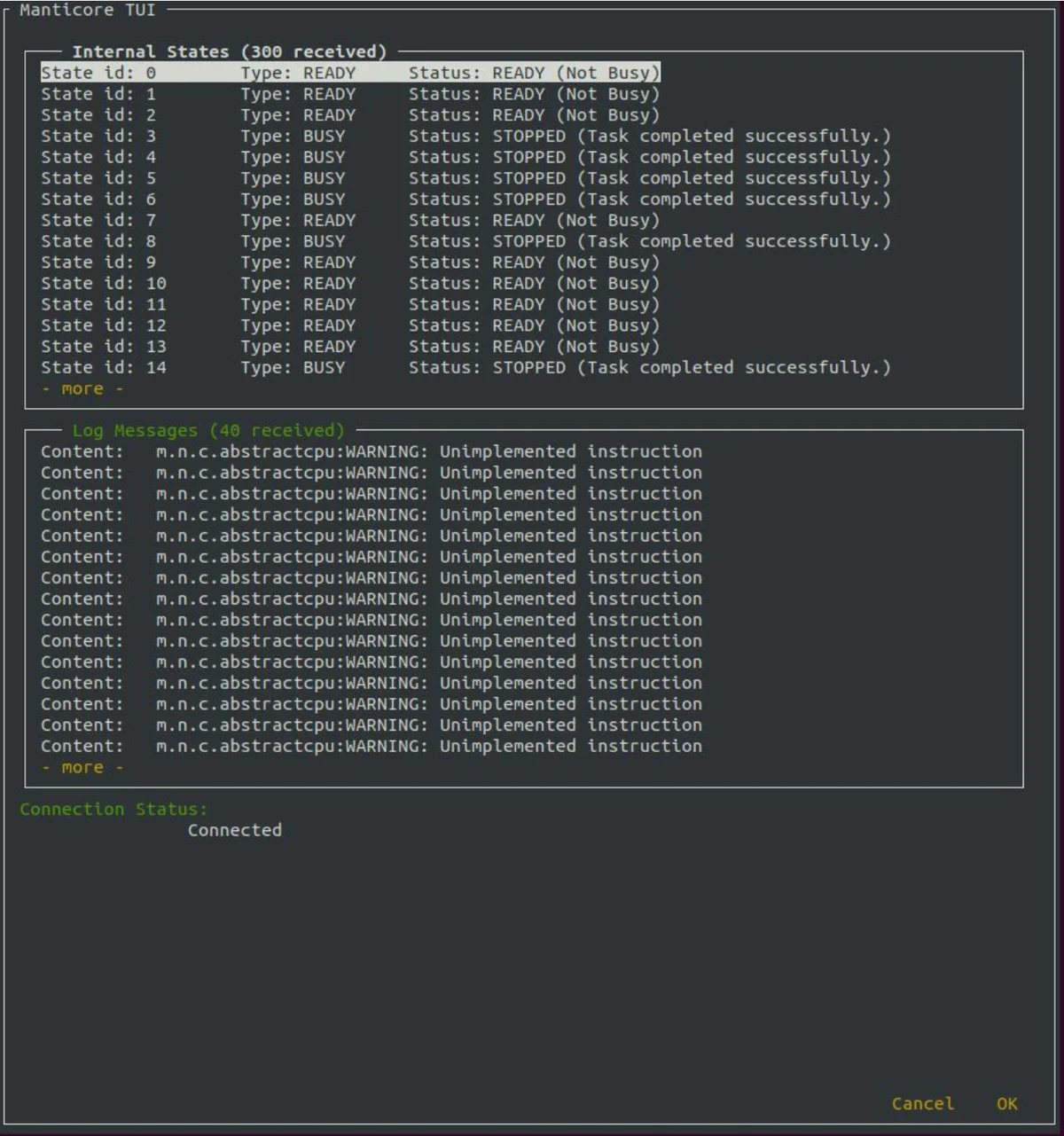
Samuel Caccavale—Go
Northeastern University
During my winternship, I developed AST- and SSA-based scanners to find bugs in Go code that were previously overlooked by tools like GoSec and errcheck. One unsafe code pattern targeted was usage of a type assertion value before checking whether the type assertion was ok in value, ok := foo.(). While errcheck will detect type assertions that do not bind the ok value (and therefore cause a panic if the type assertion fails), it can’t exhaustively check whether the usage of value is within a context where ok is true. The example reproduces the most trivial example where errcheck and the SSA approach diverge; the SSA approach will correctly detect the usage of safe as safe, and the usage of unsafe as unsafe:
package main
import ("fmt")
func main() {
var i interface{} = "foo"
safe, ok := i.(string)
if ok {
fmt.Println(safe)
}
unsafe, ok := i.(string)
fmt.Println(ok)
if true {
fmt.Println(unsafe)
}
}Taylor Pothast—Mishegos
Vanderbilt University
During my winternship, I worked on improving the performance of mishegos, Trail of Bits’ differential fuzzer for x86_64 decoders, by switching the cohort collection and output components from their original proof-of-concept JSON format to a compact binary format.
To do this, I learned about mishegos’ internal workings, its in-memory result representations, binary parsing, and how to write Kaitai Struct definitions. My work was merged on the final day of my internship, and is now the default output format for mishegos runs.
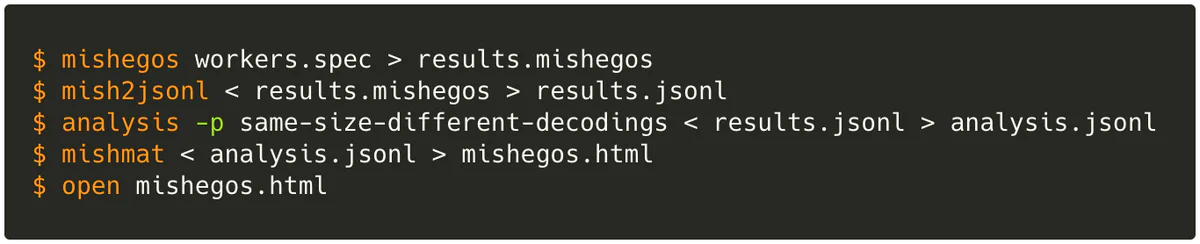
To make my work compatible with mishegos’s preexisting analysis tools, I also added a helper utility, mish2jsonl, for converting the new binary output into a JSON form mostly compatible with the original output format. Finally, I updated the analysis tools to handle the changes I made in the JSON-ified output format, including new symbolic fields for each fuzzed decoder’s state.
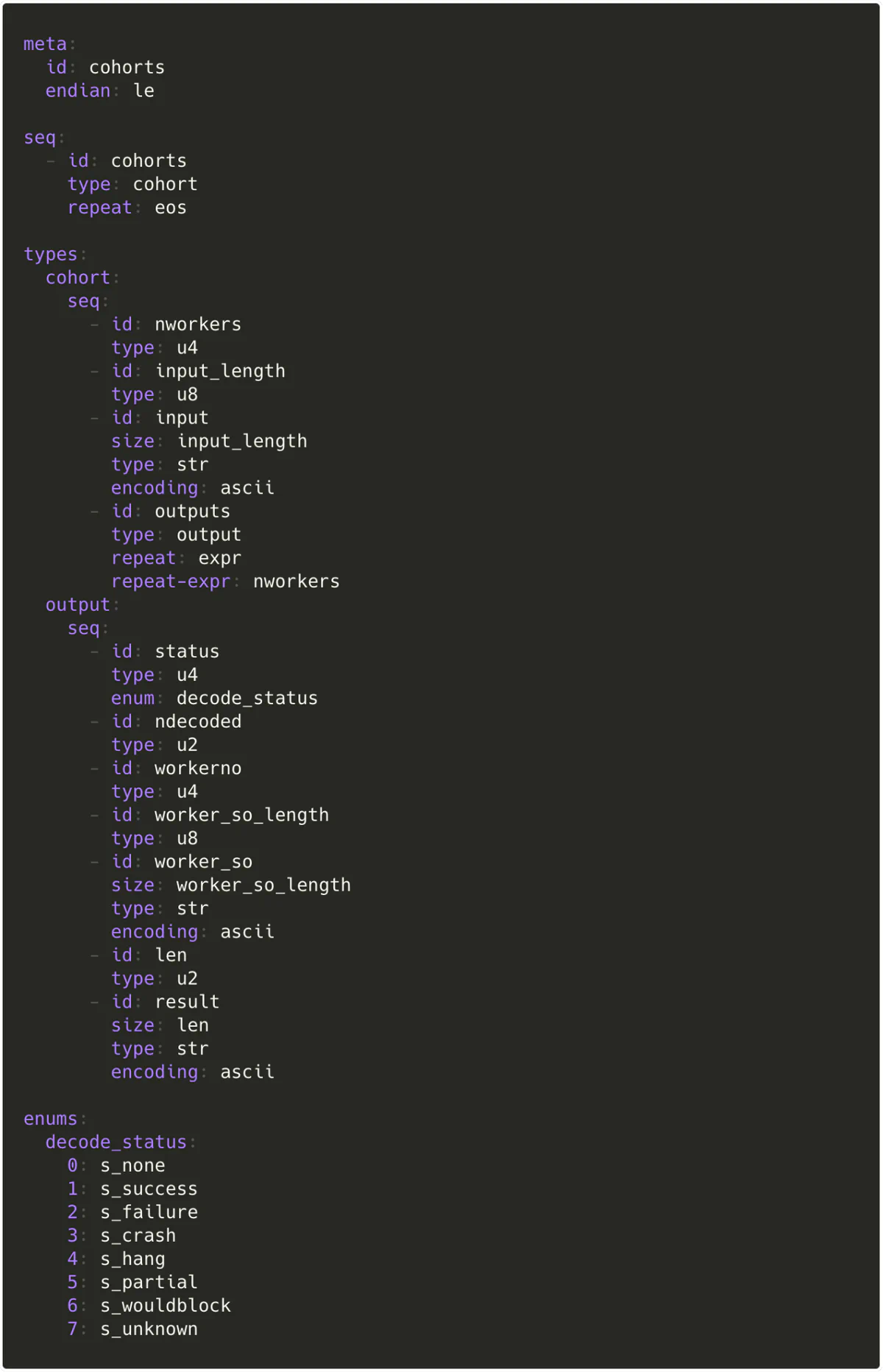
Thomas Quig—Crytic and Slither
University of Illinois Urbana-Champaign
While at Trail of Bits, I integrated Slither’s smart contract upgradeability checks into Crytic, Trail of Bits’ CI service for Ethereum security. Because smart contracts are immutable upon upload, users need to be able to upgrade their contracts if they ever need to be uploaded. To resolve this issue, the user can have the old contract, a new contract, and a proxy contract. The proxy contract contains what are essentially function pointers that can be modified to point towards the new contract. Risks arise if the aforementioned process is done incorrectly (e.g., incorrect global variable alignment). With Slither, the user can check to make sure those risks are mitigated.
The integration process was much more complicated than I thought it would be, but I was still able to successfully implement the checks. Learning the codebase and the multiple languages required to work with it simultaneously was quite difficult, but manageable. Crytic now grabs the list of all smart contracts and displays them within settings so they can be chosen. The user can pick which contract is the old contract, the new contract, and the proxy contract. Upgradeability checks are then run on those contracts, and the output is displayed to a new findings page in an easily analyzable JSON format.
I enjoyed my time at Trail of Bits. My mentors helped me learn the infrastructure while giving me opportunities to work independently. I gained significant experience in a short period of time and learned about many topics I didn’t expect to like.
William Wang—OpenSSL and Anselm
UCLA
This winter I worked on Anselm. OpenSSL is one of the most popular cryptography libraries for developers, but it’s also shockingly easy to misuse. Still, many instances of improper use fall into specific patterns, which is where Anselm comes in. My main goal was to prototype a system for detecting these behaviors.
I spent most of my time writing an LLVM pass to detect OpenSSL API calls and form a simplified graph of nodes representing possible execution paths. In larger codebases, traversing through each individual IR block can be time consuming. By “compressing” the graph to its relevant nodes (API calls) first, Anselm enables more complex analyses on it.
I also explored and began implementing heuristics for bad behaviors of varying complexity. For example, mandating that a cipher context be initialized only involves searching the children of nodes where one is created. Similarly, other ordering requirements can be enforced through the call graph alone. However, a bug like repeated IVs/nonces likely requires argument/return value analysis, which I’d like to research more in the future.
While I’m happy with what I accomplished over the winternship, there’s a lot more to be done. In addition to fleshing out the ideas mentioned above, I’d like to polish up the final interface so other developers can easily write their own heuristics. Working with LLVM IR also means that Anselm can theoretically operate on other languages that use OpenSSL bindings. I’m excited to tackle these and other challenges in the future!
See you in the fall?
We’ve selected our summer 2020 interns, but if you’d like to apply (or suggest an intern) for fall, contact us!