
Reinventing Vulnerability Disclosure using Zero-knowledge Proofs
We, along with our partner Matthew Green at Johns Hopkins University, are using zero-knowledge (ZK) proofs to establish a trusted landscape in which tech companies and vulnerability researchers can communicate reasonably with one another without fear of being sabotaged or scorned. Over the next four years, we will push the state of the art in ZK proofs beyond theory, and supply vulnerability researchers with software that produces ZK proofs of exploitability. This research is part of a larger effort funded by the DARPA program Securing Information for Encrypted Verification and Evaluation (SIEVE).
Much recent ZK work has focused on blockchain applications, where participants must demonstrate to the network that their transactions follow the underlying consensus rules. Our work will substantially broaden the types of statements provable in ZK. By the end of the program, users will be able to prove statements about programs that run on an x86 processor.
Why ZK proofs of exploitability?
Software makers and vulnerability researchers have a contentious relationship when it comes to finding and reporting bugs. Disclosing too much information about a vulnerability could ruin the reward for a third-party researcher while premature disclosure of a vulnerability could permanently damage the reputation of a software company. Communication between these parties commonly breaks down, and the technology industry suffers because of it.
Furthermore, in many instances companies are unwilling to engage with security teams and shrug off potential hazards to user privacy. In these situations, vulnerability researchers are put in a difficult position: stay silent despite knowing users are at risk, or publicly disclose the vulnerability in an attempt to force the company into action. In the latter scenario, researchers may themselves put users in harm’s way by informing attackers of a potential path to exploitability.
ZK proofs of exploitability will radically shift how vulnerabilities are disclosed, allowing companies to precisely define bug bounty scope and researchers to unambiguously demonstrate they possess valid exploits, all without risking public disclosure.
Designing ZK proofs
In ZK proofs, a prover convinces a verifier that they possess a piece of information without revealing the information itself. For example, Alice might want to convince Bob that she knows the SHA256 preimage, X, of some value, Y, without actually telling Bob what X is. (Maybe X is Alice’s password). Perhaps the most well-known industrial application of ZK proofs is found in privacy-preserving blockchains like Zcash, where users want to submit transactions without revealing their identity, the recipient’s identity, or the amount sent. To do this, they submit a ZK proof showing that the transaction follows the blockchain’s rules and that the sender has sufficient funds. (Check out Matt Green’s blog post for a good introduction to ZK proofs with examples.)
Now you know why ZK proofs are useful, but how are these algorithms developed, and what tradeoffs need to be evaluated? There are three metrics to consider for developing an efficient system: prover time, verifier time, and bandwidth, which is the amount of data each party must send to the other throughout the protocol. Some ZK proofs don’t require interaction between the prover and verifier, in which case the bandwidth is just the size of the proof.
And now for the hard part, and the main barrier that has prevented ZK proofs from being used in practice. Many classical ZK protocols require that the underlying statement be first represented as a Boolean or arithmetic circuit with no loops (i.e., a combinatorial circuit). For Boolean circuits, we can use AND, NOT, and XOR gates, whereas arithmetic circuits use ADD and MULT gates. As you might imagine, it can be challenging to translate a statement you wish to prove into such a circuit, and it’s particularly challenging if that problem doesn’t have a clean mathematical formulation. For example, any program with looping behavior must be unrolled prior to circuit generation, which is often impossible when the program contains data-dependent loops.
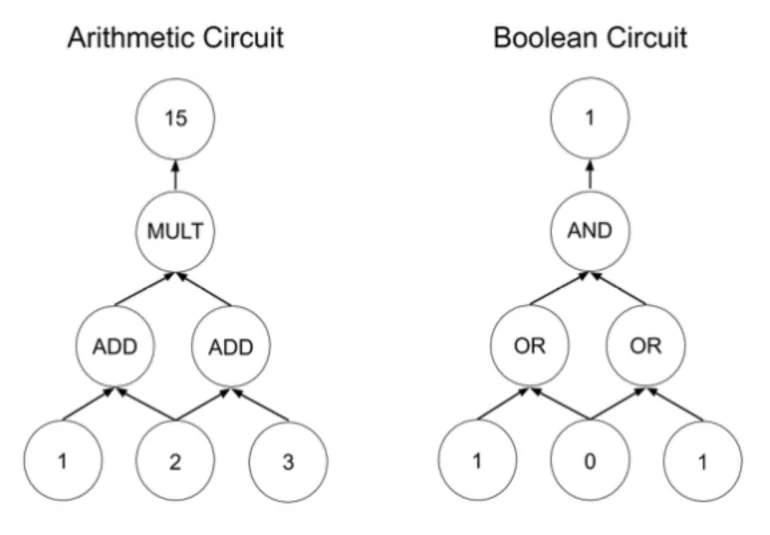
Furthermore, circuit size has an impact on the efficiency of ZK protocols. Prover time usually has at least a linear relationship with circuit size (often with large constant overhead per gate). Therefore, ZK proofs in vulnerability disclosure require the underlying exploit to be captured by a reasonably sized circuit.
Proving Exploitability
Since ZK proofs generally accept statements written as Boolean circuits, the challenge is to prove the existence of an exploit by representing it as a Boolean circuit that returns “true” only if the exploit succeeds.
We want a circuit that accepts if the prover has some input to a program that leads to an exploit, like a buffer overflow that leads to the attacker gaining control of program execution. Since most binary exploits are both binary- and processor-specific, our circuit will have to accurately model whatever architecture the program was compiled to. Ultimately, we need a circuit that accepts when successful runs of the program occur and when an exploit is triggered during execution.
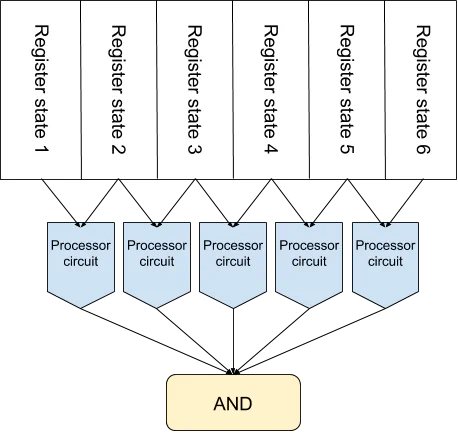
Taking a naive approach, we would develop a circuit that represents “one step” of whatever processor we want to model. Then, we’d initialize memory to contain the program we want to execute, set the program counter to wherever we want program execution to start, and have the prover run the program on their malicious input—i.e., just repeat the processor circuit until the program finishes, and check whether an exploit condition was met at each step. This could mean checking whether the program counter was set to a known “bad” value, or a privileged memory address was written to. An important caveat about this strategy: The entire processor circuit will need to run at each step (even though only one instruction is being actually executed), because singling out one piece of functionality would leak information about the trace.
Unfortunately, this approach will produce unreasonably large circuits, since each step of program execution will require a circuit that models both the core processor logic and the entirety of RAM. Even if we restrict ourselves to machines with 50 MB of RAM, producing a ZK statement about an exploit whose trace uses 100 instructions will cause the circuit to be at least 5 GB. This approach is simply too inefficient to work for meaningful programs. The key problem is that circuit size scales linearly with both trace length and RAM size. To get around this, we follow the approach of SNARKs for C, which divides the program execution proof into two pieces, one for core logic and the other for memory correctness.
To prove logic validity, the processor circuit must be applied to every sequential pair of instructions in the program trace. The circuit can verify whether one register state can legitimately follow the other. If every pair of states is valid, then the circuit accepts. Note, however, that memory operations are assumed to be correct. If the transition function circuit were to include a memory checker, it would incur an overhead proportional to the size of the RAM being used.
Memory can be validated by having the prover also input a memory-sorted execution trace. This trace places one trace entry before the other if the first accesses a lower-numbered memory address than the second (with timestamps breaking ties). This trace lets us do a linear sweep of memory-sorted instructions and ensure consistent memory access. This approach avoids creating a circuit whose size is proportional to the amount of RAM being used. Rather, this circuit is linear in the trace size and only performs basic equality checks instead of explicitly writing down the entirety of RAM at each step.
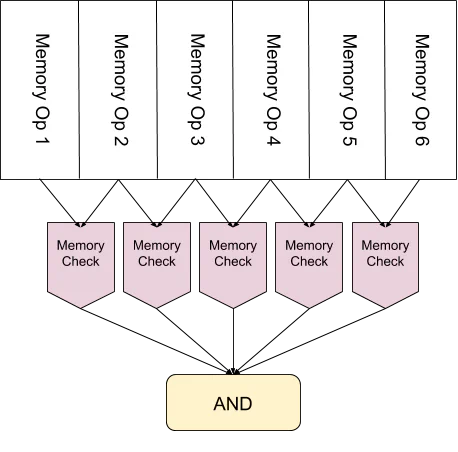
The final issue we need to address is that nothing stops the prover from using a memory-sorted trace that doesn’t correspond to the original and create a bogus proof. To fix this, we have to add a “permutation checker” circuit that verifies we’ve actually sorted the program trace by memory location. More discussion on this can be found in the SNARKs for C paper.
Modeling x86
Now that we know how to prove exploits in ZK, we need to model relevant processor architectures as Boolean circuits. Prior work has done this for a RISC architecture called TinyRAM, which was designed to run efficiently in a ZK context. Unfortunately, TinyRAM is not used in commercial applications and is therefore not realistic for providing ZK proofs of exploitability in real-world programs, since many exploits rely on architecture-specific behavior.
We will begin our development of ZK proofs of exploitability by modeling a relatively simple microprocessor that is in widespread use: the MSP430, a simple chip found in a variety of embedded systems. As an added bonus, the MSP430 is also the system the Microcorruption CTF runs on. Our first major goal is to produce ZK proofs for each Microcorruption challenge. With this “feasibility demonstration” complete, we will set our sights on x86.
Moving from a simple RISC architecture to an infamously complex CISC machine comes with many complications. Circuit models of RISC processors clock in between 1–10k gates per cycle. On the other hand, if our x86 processor turned out to contain somewhere on the order of 100k gates, a ZK proof for an exploit that takes 10,000 instructions to complete would produce a proof of size 48 gigabytes. Since x86 is orders of magnitude more complex than MSP430, naively implementing its functionality as a Boolean circuit would be impractical, even after separating the proof of logic and memory correctness.
Our solution is to take advantage of the somewhat obvious fact that no program uses all of x86. It may be theoretically possible for a program to use all 3,000 or so instructions supported by x86, but in reality, most only use a few hundred. We will use techniques from program analysis to determine the minimal subset of x86 needed by a given binary and dynamically generate a processor model capable of verifying its proper execution.
Of course, there are some x86 instructions that we cannot support, since some x86 instructions implement data-dependent loops. For example, repz repeats the subsequent instruction until rcx is 0. The actual behavior of such an instruction cannot be determined until runtime, so we cannot support it in our processor circuit, which must be a combinatorial circuit. To handle such instructions, we will produce a static binary translator from normal x86 to our program-specific x86 subset. This way, we can handle the most complex x86 instructions without hard-coding them into our processor circuit.
A new bug disclosure paradigm
We are very excited to start this work with Johns Hopkins University and our colleagues participating in the DARPA SIEVE Program. We want to produce tools that radically shift how vulnerabilities are disclosed, so companies can precisely specify the scope of their bug bounties and vulnerability researchers can securely submit proofs that unambiguously demonstrate they possess a valid exploit. We also anticipate that the ZK disclosure of vulnerabilities can serve as a consumer protection mechanism. Researchers can warn users about the potential dangers of a given device without making that vulnerability publicly available, which puts pressure on companies to fix issues they may not have been inclined to otherwise.
More broadly, we want to transition ZK proofs from academia to industry, making them more accessible and practical for today’s software. If you have a specific use for this technology that we haven’t mentioned here, we’d like to hear from you. We’ve built up expertise navigating the complex ecosystem of ZK proof schemes and circuit compilers, and can help!