
Towards Practical Security Optimizations for Binaries
To be thus is nothing, but to be safely thus. (Macbeth: 3.1)
It’s not enough that compilers generate efficient code, they must also generate safe code. Despite the extensive testing and correctness certification that goes into developing compilers and their optimization passes, they may inadvertently introduce information leaks into programs or eliminate security-critical operations the programmer wrote in source code. Let’s take a look at an example.
Figure 1 shows an example of CWE-733, a weakness in which a compiler optimization removes or modifies security-critical code. In this case, the source code written by the programmer sanitizes a variable that previously held a cryptographic key by setting it to zero. This is an important step! If the programmer doesn’t sanitize the variable, the key may be recoverable by an attacker later. However, when this code is compiled the sanitization operation is likely to be removed by a compiler optimization pass called dead store elimination.
This pass optimizes programs by eliminating what it thinks are unnecessary variable assignment operations. It assumes that values assigned to a variable are unnecessary if they are not used later in the program, which unfortunately includes our sanitization code.

This example is one of several well-documented instances of a compiler optimization inadvertently introducing a security weakness into a program. Recently, my colleagues at Georgia Tech and I published an extensive study of how compiler design choices impact another security property of binaries: malicious code reusability. We discovered that compiler code generation and optimization behaviors generally do not consider malicious reusability. As a result, they produce binaries that are generally more reusable by an attacker than is necessary.
Building powerful code reuse exploits
Attackers use code reuse exploit techniques such as return- and jump-oriented programming (ROP and JOP) to evade malicious code injection defenses. Instead of injecting malicious code, attackers using these techniques reuse snippets of a vulnerable program’s executable code, called gadgets, to write their exploit payloads.
Gadgets consist of one or more binary instructions that perform a useful computational task followed by an indirect branch instruction (return, indirect jump, indirect call) that terminates the gadget. The final control-flow instruction is used to chain one or more gadgets together. Gadgets can be thought of as individual instructions that can be used to write an exploit program.
Since the gadgets are part of the vulnerable program, defenses that prevent injected code from being executed won’t stop the exploit. The downside from the attacker’s perspective is that they are potentially limited in their exploit programming by the gadgets that are available. Ultimately, the gadgets available to the attacker (and how useful they are) are a function of the compiler’s code generation and optimization behaviors, because it is the compiler that produces the program’s binary code.
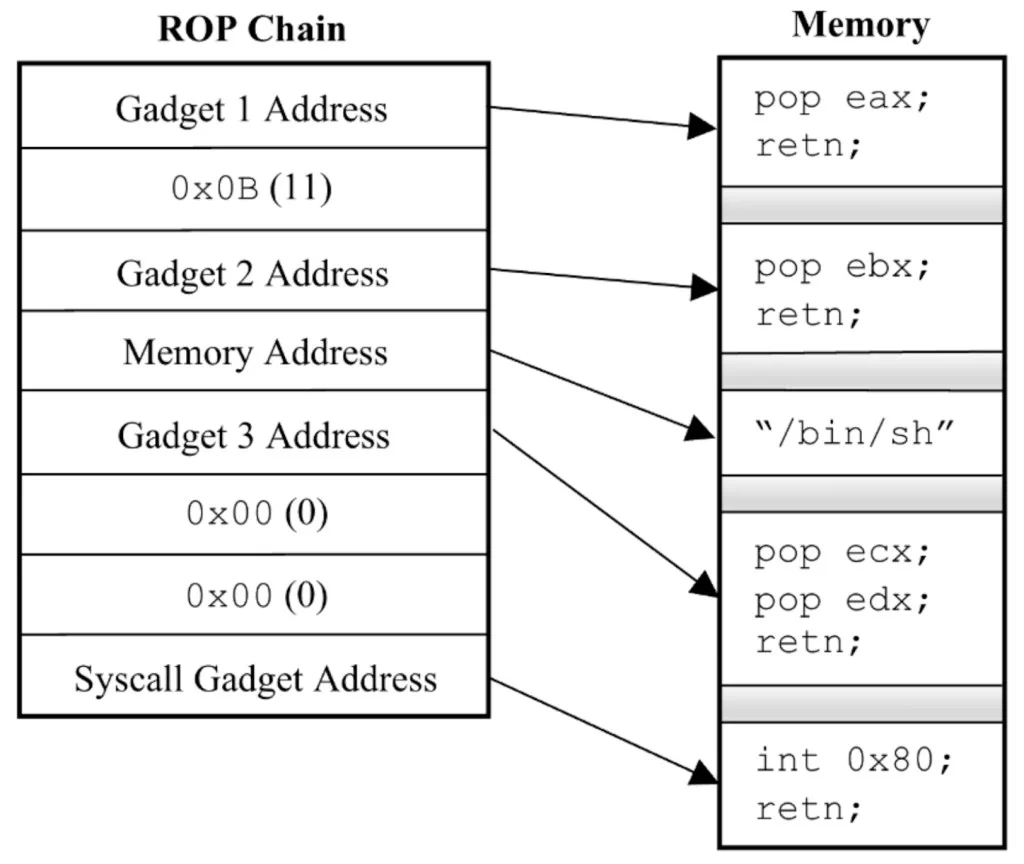
A simple example of a ROP payload is depicted in Figure 2. The payload consists of a chain of gadget addresses (i.e. the exploit) with some necessary data interspersed (i.e. the exploit’s inputs). The attacker first exploits a memory corruption vulnerability like a stack-based buffer overflow (CWE-121) to place the payload on the stack in such a way that the return address on the stack is overwritten with the address of the first gadget in the chain. This redirects program execution to the first gadget in the chain.
Summary of study findings
In our study, we analyzed over 1,000 variants of 20 different programs compiled with GCC and clang to determine how optimization behaviors affect the set of gadgets available in the output binaries. We used a static analysis tool, GSA, to measure changes in gadget set size, utility, and composability before and after applying optimization options. Starting at a high level, we first discovered that optimizations increased gadget set size, utility, and/or composability in approximately 85% of cases.
Diving deeper, we performed differential binary analysis on several program variants to identify the root causes of these effects. We identified several compiler behaviors that both directly and indirectly contribute to this problem. Two behaviors stood out as the most impactful: duplicating indirect branch instructions and code layout changes.
Duplicating indirect branch instructions
Chaining gadgets together to create exploit programs relies on the control-flow instructions at the end of each gadget. Since each gadget must end with one of these instructions, the more indirect branch transfers a program has the more likely it is to have a large number of unique and useful gadgets. Many compiler optimizations improve performance by selectively duplicating these instructions, resulting in increases to gadget set size and utility.
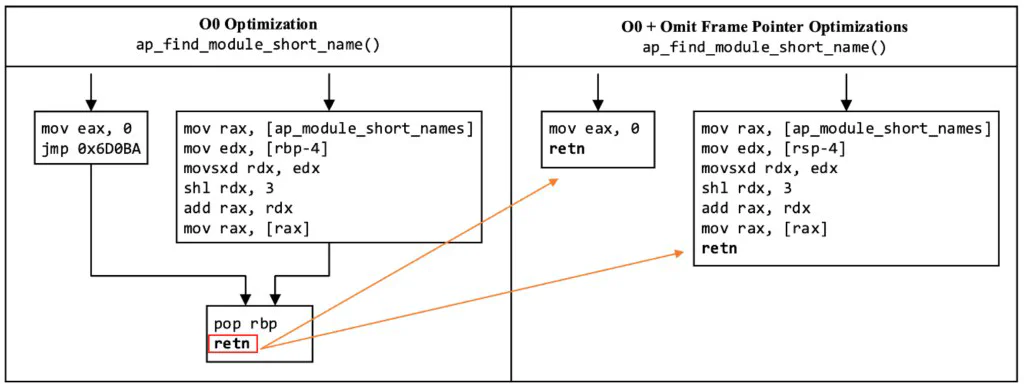
This behavior is most apparent with GCC‘s omit frame pointer optimization, which eliminates frame pointer setup and restore instructions at the beginning and end of functions that do not need them. In many cases, such as the one shown in Figure 3, eliminating the pointer restore instruction at the end of a function creates an opportunity to optimize further by duplicating the indirect control flow instruction (retn)at the end of the function. While this secondary optimization slightly reduces code size and execution time, it creates one or more copies of the retn instruction. In turn, this introduces several more gadgets into the program, including ones that may be useful to an attacker.
Binary layout changes
In general, optimization behaviors insert, remove, or alter instructions in such a way that changes the size of code blocks and functions. This causes changes in how blocks and functions are eventually laid out in binary format, which in turn requires changes to displacements used in control-flow instructions throughout the program.
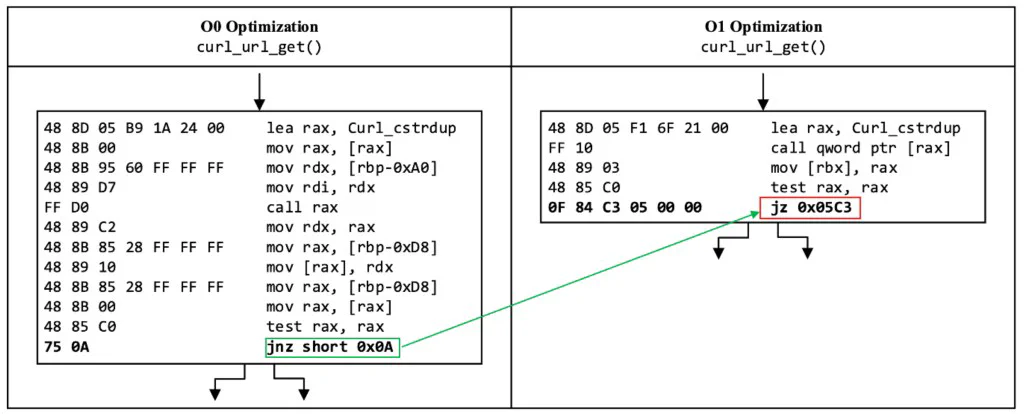
In some cases, the new displacements contain the binary encoding of an indirect branch instruction, like the example shown in Figure 4. Here, a conditional jump instruction with a short 1-byte displacement in unoptimized code changes to equivalent conditional jump instruction with a near 4-byte displacement as a byproduct of a layout change caused by optimization. This new displacement encodes the retn (i.e., 0xC3) indirect branch instruction. Even though the displacement is not intended to be an instruction, it can be decoded as one during an exploit because x86_64 uses unaligned, variable-length instructions. The sequence of bytes preceding indirect branch instruction encoding can be decoded as a gadget if they happen to encode valid instructions (which is quite likely given the density of the x86_64 ISA). These gadgets are called “unintended” or “unaligned” gadgets.
What can we do to address this?
The various behaviors we discovered all have a common property: they are secondary to or independent of the desired optimization. This means we can undo gadget-introducing behaviors without completely sacrificing performance.
Ideally, compilers would patch their optimizations to remove these behaviors. Unfortunately, instruction duplication behaviors are common to many different optimization passes and gadget encodings introduced through displacement changes can’t be detected during optimization as binary layout happens much later.
Fortunately, binary recompilers such as Egalito are well-suited to address this problem. Egalito allows us to transform program binaries in a layout-agnostic manner regardless of the compiler used to generate the binary. This provides many advantages to the problem at hand. First, we can implement recompiler passes to undo negative behaviors once for Egalito instead of for each problematic optimization in each compiler. Additionally, we can undo negative behaviors in programs without access to source code or special compilers!
Practical binary security optimizations
We built an initial set of five binary optimization passes for Egalito that eliminate gadgets in binaries that are introduced carelessly by compilers:
- Return Merging: Merge all return instructions in a function to a single instance.
- Indirect Jump Merging: Merge all indirect jump instructions targeting the same register in a function to a single instance.
- Instruction barrier widening: Eliminate unintended special-purpose gadgets that span consecutive intended instructions.
- Offset/Displacement Sledding: Eliminate gadgets rooted in jump displacements.
- Function Reordering: Eliminate gadgets rooted in call offsets.
Next, we evaluated the impact of these optimization passes on gadget sets and performance by applying them to several of our study binaries. We found that our passes:
- Eliminated 31.8% of useful gadgets on average
- Reduced the overall utility of gadget sets in 78% of variants
- Eliminated one or more special purpose gadget types (e.g., syscall gadgets) in 75% of variants
- Had no effect on execution speed
- Increased code size by only 6.1 kB on average
Conclusion
Compiler code generation and optimization behaviors have a massive impact on a binary gadget set. But due to a lack of attention to latent security properties, these behaviors generally create binaries with gadget sets that are easier for attackers to reuse in exploits. There are many root causes for this, however, it is possible to mitigate and undo negative behaviors with simple code transformations that do not sacrifice performance.
While our initial research on this problem has yielded some promising results, it is not exhaustive in dealing with problematic compiler behaviors. Over the coming year, I will be working on additional transformations to address other issues such as problematic register allocations. Additionally, I will be examining how these optimizations may have secondary benefits, such as reducing the performance costs of employing other code reuse defenses such as Control-Flow Integrity (CFI).
Acknowledgements
This research was conducted with my co-authors at Georgia Tech and Georgia Tech Research Institute: Matthew Pruett, Robert Bigelow, Girish Mururu, and Santosh Pande.