
Optimizing a smart contract fuzzer
During my winternship, I applied code analysis tools, such as GHC’s Haskell profiler, to improve the efficiency of the Echidna smart contract fuzzer. As a result, Echidna is now over six times faster!
Echidna overview
To use Echidna, users provide smart contracts and a list of conditions that should be satisfied no matter what happens (e.g., “a user can never have a negative number of coins”). Then, Echidna generates a large number of random transaction sequences, calls the contracts with these transaction sequences, and checks that the conditions are still satisfied after the contracts execute.
Echidna uses coverage-guided fuzzing; this means it not only uses randomization to generate transaction sequences, but it also considers how much of the contract code was reached by previous random sequences. Coverage allows bugs to be found more quickly since it favors sequences that go deeper into the program and that touch more of its code; however, many users have noted that Echidna runs far slower when coverage is on (over six times slower on my computer). My task for the internship was to track down the sources of slow execution time and to speed up Echidna’s runtime.
Optimizing Haskell programs
Optimizing Haskell programs is very different from optimizing imperative programs since the order of execution is often very different from the order in which the code is written. One issue that often occurs in Haskell is very high memory usage due to lazy evaluation: computations represented as “thunks” are stored to be evaluated later, so the heap keeps expanding until it runs out of space. Another simpler issue is that a slow function might be called repeatedly when it needs to be called only once and have its result saved for later (this is a general problem in programming, not specific to Haskell). I had to deal with both of these issues when debugging Echidna.
Haskell profiler
One feature of Haskell that I made extensive use of was profiling. Profiling lets the programmer see which functions are taking up the most memory and CPU time and look at a flame graph showing which functions call which other functions. Using the profiler is as simple as adding a flag at compile time (-prof) and another pair of flags at runtime (+RTS -p). Then, given the plaintext profile file that is generated (which is very useful in its own right), a flame graph can be made using the ghc-prof-flamegraph tool; here’s an example:
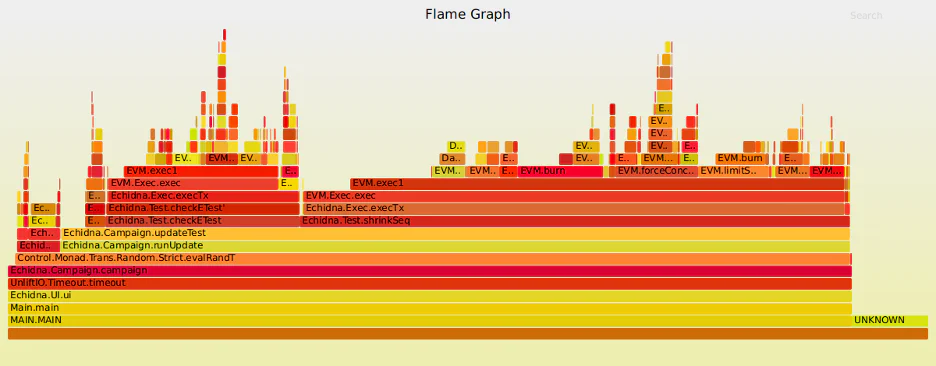
This flame graph shows how much computing time each function took up. Each bar represents a function, and its length represents how much time it took up. A bar stacked on another bar represents one function calling another. (The colors of the bars are picked at random, for aesthetic reasons and readability.)
The profiles generated from running Echidna on sample inputs showed mostly the usual expected functions: functions that run the smart contracts, functions that generate inputs, and so on. One that caught my eye, though, is a function called getBytecodeMetadata, which scans through contract bytecodes and looks for the section containing the contract’s metadata (name, source file, license, etc.). This function needed to be called only a few times at the start of the fuzzer, but it was taking up a large portion of the CPU and memory usage.
A memoization fix
Searching through the codebase, I found a problem slowing down the runtime: the getBytecodeMetadata function is called repeatedly on the same small set of contracts in every execution cycle. By storing the return value from getBytecodeMetadata and then looking it up later instead of recalculating, we could significantly improve the runtime of the codebase. This technique is called memoization.
Adding in the change and testing it on some example contracts, I found that the runtime went down to under 30% of its original time.
A state fix
Another issue I found was with Ethereum transactions that run for a long time (e.g., a for loop with a counter going up to one million). These transactions were not able to be computed because Echidna ran out of memory. The cause of this problem was Haskell’s lazy evaluation filling the heap with unevaluated thunks.
Luckily, the fix for this problem had already been found by someone else and suggested on GitHub. The fix had to do with Haskell’s State data type, which is used to make it more convenient (and less verbose) to write functions that pass around state variables. The fix essentially consisted of avoiding the use of the State data type in a certain function and passing state variables around manually instead. The fix hadn’t been added to the codebase because it produced different results than the current code, even though it was supposed to be a simple performance fix that didn’t affect the behavior. After dealing with this problem and cleaning up the code, I found that it not only fixed the memory issue, but it also improved Echidna’s speed. Testing the fix on example contracts, I found that the runtime typically went down to 50% of its original time.
For an explanation of why this fix worked, let’s look at a simpler example. Let’s say we have the following code that uses the State data type to make a simple change on the state for all numbers from 50 million down to 1:
import Control.Monad.State.Strict
-- if the state is even, divide it by 2 and add num, otherwise just add num
stateChange :: Int -> Int -> Int
stateChange num state
| even state = (state `div` 2) + num
| otherwise = state + num
stateExample :: Int -> State Int Int
stateExample 0 = get
stateExample n = modify (stateChange n) >> stateExample (n - 1)
main :: IO ()
main = print (execState (stateExample 50000000) 0)This program runs fine, but it uses up a lot of memory. Let’s write the same piece of code without the State data type:
stateChange :: Int -> Int -> Int
stateChange num state
| even state = (state `div` 2) + num
| otherwise = state + num
stateExample' :: Int -> Int -> Int
stateExample' state 0 = state
stateExample' state n = stateExample' (stateChange n state) (n - 1)
main :: IO ()
main = print (stateExample' 0 50000000)This code uses far less memory than the original (46 KB versus 3 GB on my computer). This is because of Haskell compiler optimizations. I compiled with the -O2 flag ghc -O2 file.hs; ./file, or ghc -O2 -prof file.hs; ./file +RTS -s for memory allocation stats.
Unoptimized, the call chain for the second example should be stateExample' 0 50000000 = stateExample' (stateChange 50000000 0) 49999999 = stateExample' (stateChange 49999999 $ stateChange 50000000 0) 49999998 = stateExample' (stateChange 49999998 $ stateChange 49999999 $ stateChange 50000000 0) 49999997 = …. Note the ever-growing (... $ stateChange 49999999 $ stateChange 50000000 0) term, which expands to fill up more and more memory until it is finally forced to be evaluated once n reaches 0.
However, the Haskell compiler is clever. It realizes that the final state will eventually be needed anyway and makes that term strict, so it doesn’t end up taking up tons of memory. On the other hand, when Haskell compiles the first example, which uses the State data type, there are too many layers of abstraction in the way, and it isn’t able to realize that it can make the (... $ stateChange 50000000 0) term strict. By not using the State data type, we are making our code simpler to read for the Haskell compiler and thus making it easier to implement the necessary optimizations.
The same thing was happening in the Echidna memory issue that I helped to solve: minimizing the use of the State data type helped the Haskell compiler to realize that a term could be made strict, so it resulted in a massive decrease in memory usage and an increase in performance.
An alternate fix
Another way to fix the memory issue with our above example is to replace the line defining stateExample n with the following:
stateExample n = do
s <- get
put $! stateChange n s
stateExample (n-1)Note the use of $! in the third line. This forces the evaluation of the new state to be strict, eliminating the need for optimizations to make it strict for us. While this also fixes the problem in our simple example, things get more complicated with Haskell’s Lens library, so we chose not to use put $! in Echidna; instead we chose to eliminate the use of State.
Conclusion
The performance improvements that we introduced are already available in the 2.0.0 release. While we’ve achieved great success this round, this does not mean our work on Echidna’s fuzzing speed is done. Haskell is a language compiled to native code and it can be very fast with enough profiling effort. We’ll continue to benchmark Echidna and keep an eye on slow examples. If you believe you’ve encountered one, please open an issue.
I thoroughly enjoyed working on Echidna’s codebase for my winternship. I learned a lot about Haskell, Solidity, and Echidna, and I gained experience in dealing with performance issues and working with relatively large codebases. I’d specifically like to thank Artur Cygan for setting aside the time to give valuable feedback and advice.