
How safe browsing fails to protect user privacy
Recently, security researchers discovered that Apple was sending safe browsing data to Tencent for all Chinese users. This revelation has brought the underlying security and privacy guarantees of the safe browsing protocol under increased scrutiny. In particular, safe browsing claims to protect users by providing them with something called k-anonymity. In this post we’ll show that this definition of privacy is somewhat meaningless in the context of safe browsing. Before jumping into why k-anonymity is insufficient, let’s take a look at how the safe browsing protocol works.
How does safe browsing work?
A while back, Google thought it would be useful to leverage their knowledge of the web to provide a database of malicious sites to web clients. Initially, users would submit their IP address and the URL in question to Google, which would subsequently be checked against a malware database. This scheme was called the Lookup API and is still available today. However, people quickly became uneasy about surrendering so much of their privacy. This reasonable concern led to the development of the current safe browsing scheme, called the Update API, which is used by both Google and Tencent.
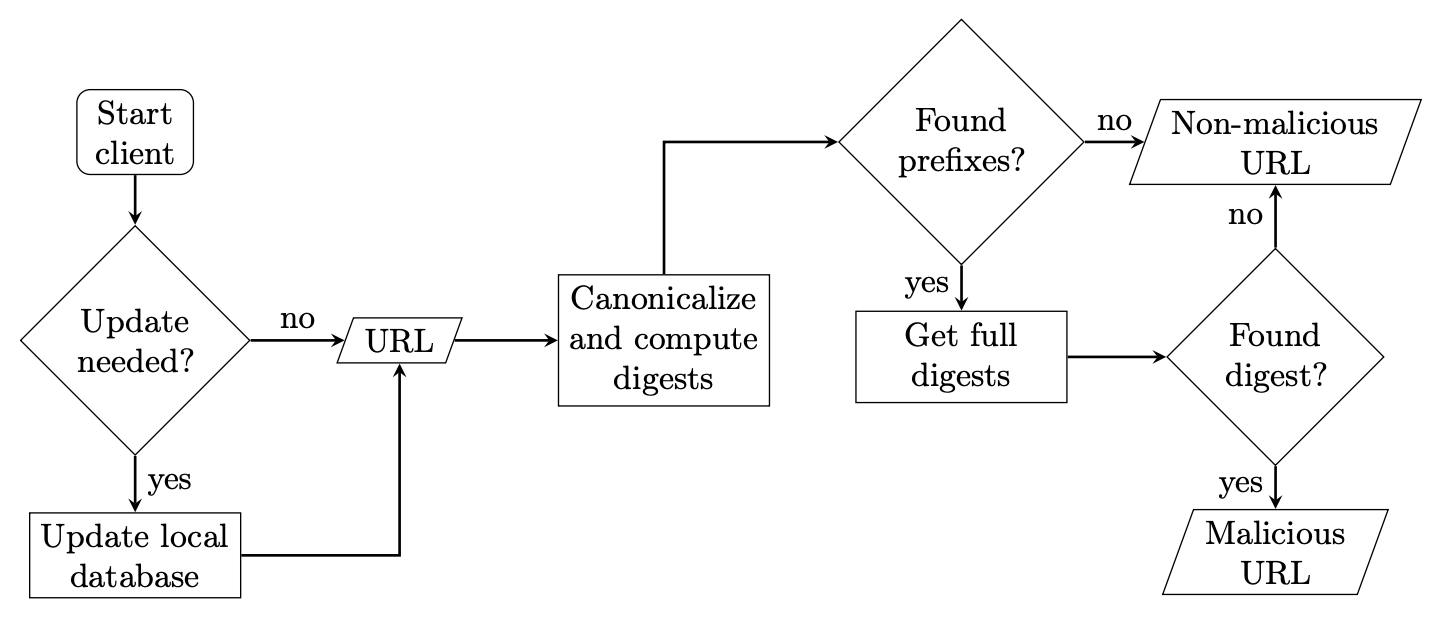
At a high level, Google maintains a list of malicious URLs and their 256-bit hashes. To save on bandwidth when distributing this list to browsers, they only send out a 32-bit prefix of each hash. This means that when the user’s browser checks whether or not a site is malicious, they might get a false positive, since many 256-bit URL hashes will contain the same 32-bit prefix. To remedy this, if a match occurs, the browser will send the 32-bit prefix in question to Google and get a full list of URLs whose 256-bit hash contains that prefix. To recap, the safe browsing Update API goes through the following steps every time a user tries to visit a new URL:
- Browser hashes the URL and checks it against the (local) list of 32-bit prefixes.
- If there is a match, the browser sends Google the 32-bit prefix.
- Google then sends back all blacklisted URLs whose 256-bit hash contains the prefix.
- If there is a match in the updated list, the browser issues a warning to the user.
Intuitively, this safe browsing scheme is more private than the original, since Google only learns the 32-bit prefix of each potentially malicious site the user visits. Indeed, Google has argued that it provides users with something called k-anonymity—a metric used by privacy analysts to determine how unique a piece of identifying information is. Let’s take a look at what exactly k-anonymity is, and to what extent safe browsing satisfies this definition.
What is k-anonymity
Traditionally, k-anonymity has been used to remove personal identifying information from a database. At a high level, it involves removing pieces of sensitive data until everyone in the dataset “looks like” at least k other people with respect to certain traits. For example, if we had the table of medical records in Figure 1, we could modify the Name and Age fields to make patients 2-anonymous with respect to Name, Age, Gender, and State, as shown in Figure 2.
| Name | Age | Gender | State | Disease |
|---|---|---|---|---|
| Candace | 26 | Female | NY | Flu |
| Richard | 23 | Male | CA | Flu |
| Robin | 15 | Nonbinary | NY | None |
| Alyssa | 52 | Female | CA | Cancer |
| Omar | 29 | Male | CA | None |
| Kristine | 17 | Nonbinary | NY | Cancer |
| Emily | 58 | Female | CA | Heart-disease |
| Jasmine | 20 | Female | NY | None |
Figure 1
Anyone trying to use this data will get all the info they need to perform some kind of statistical analysis (ostensibly your name won’t really affect your likelihood of getting TB), but anyone represented in the database will “look like” at least two other people. That way, an attacker trying to de-anonymize people will fail because they won’t be able to distinguish between the three entries that look alike. Obviously the bigger the k, the better; if the attacker is an insurance provider trying to use medical data as a way to justify hiking up your premiums, a database providing 2-anonymity might not be enough. In Figure 2, if the insurance company knows you are represented in the database and a 52 year old woman from California, they will be able to deduce that you have either cancer or heart disease and start charging you more money.
| Name | Age | Gender | State | Disease |
|---|---|---|---|---|
| * | 20-30 | Female | NY | Flu |
| * | 20-30 | Male | CA | Flu |
| * | 10-20 | Nonbinary | NY | None |
| * | 50-60 | Female | CA | Cancer |
| * | 20-30 | Male | CA | None |
| * | 10-20 | Nonbinary | NY | Cancer |
| * | 50-60 | Female | CA | Heart-disease |
| * | 20-30 | Female | NY | None |
Figure 2
Back to safe browsing: We can see how restricting the URLs viewable by Google or Tencent to a 32-bit hash prefix renders both providers unable to distinguish your request from any other URL with that same hash prefix. The question is, how many such collisions can we expect to occur? In 2015 Gerbet et al concluded that each prefix occurred roughly 14757 times across the web, implying that users of safe browsing can expect their browsing data to be roughly 14757-anonymous. In other words, Google/Tencent only knows that the website you attempted to go to is contained in a set of size approximately 14757, which is likely big enough to contain plenty of generic websites that would not be politically (or commercially) very revealing.
Why k-anonymity fails to protect users
Despite the fact that safe browsing satisfies the definition of k-anonymity, it actually isn’t very hard for Google to recover your browsing data from these queries. This insecurity is due to the fact that the privacy guarantees of k-anonymity don’t account for Google’s ability to cross-reference multiple safe browsing queries and narrow down which specific website corresponds with a given 32-bit prefix.
As a first example of such an attack, recall that Google uses cookies for safe browsing and can therefore see when multiple queries come from the same IP address. Now, suppose both www.amazon.com and https://www.amazon.com/gp/cart/view.html?ref_=nav_cart share a 32-bit hash prefix with two different malicious websites. If a user visits both Amazon and their shopping cart in rapid succession, Google will receive both 32-bit hash prefixes. Since it is unlikely the user visited two unrelated malicious websites back to back, Google can be reasonably sure that they were shopping on Amazon. This attack only works when two related websites both share a 32-bit hash prefix with malicious websites and the user visits them within a small window of time. However, this example already shows that k-anonymity isn’t so useful when faced with an adversary capable of correlating multiple queries.
The situation is actually much worse, though, because the safe browsing protocol often forces users to submit several highly correlated URLs at the same time. These multiple queries occur because many URLs are in some sense “too specific” for Google to keep track of, since malicious websites can create new URLs faster than Google can report each specific one. To account for this, users submit a set of “URL decompositions” for each query, which is constructed by progressively stripping pieces of the URL off.
For example, when visiting the URL http://a.b.c/1/2 the browser would simultaneously check the following URLs against the safe browsing database:
a.b.c/1/2a.b.c/1/a.b.c/b.c/b.c/1/
Using the full URL decomposition allows Google to provide users with a high degree of confidence that the website they are visiting isn’t malicious. However, submitting many highly correlated 32-bit hash prefixes all at once ruins much of the privacy originally provided by the safe browsing protocol. If Google receives the 32-bit hash prefix corresponding to both a.b.c/ and a.b.c/1 in the same query, it can easily de-anonymize the user’s browsing data. Even in circumstances where submitting multiple prefixes doesn’t lead to full URL recovery, there may be sufficient information to learn sensitive details about the user’s browsing history.
To bring things down to earth, Gerbet et al. showed that this URL decomposition attack can be used to identify a user’s taste in pornography—something an oppressive government would certainly be interested in monitoring. Even worse, since these malware databases aren’t made public, it’s difficult to determine if hash prefixes haven’t been adversarially included to track users. While we may trust Google not to rig the database so they can determine when users visit pro-Hong Kong websites, it’s easy to imagine Tencent taking advantage of this vulnerability.
Looking forward
While safe browsing undoubtedly provides real security benefits to users, it fails to protect them from companies or governments that want to monitor their browsing habits. Unfortunately, this lack of privacy is obscured by the fact that the protocol provides users with a weak, but technically precise, notion of anonymity. As both the technology and legal communities rally around tools like k-anonymity and differential privacy, we need to keep in mind that they are not one-size-fits-all techniques, and systems that theoretically satisfy such definitions might provide no real meaningful privacy when actually deployed.
If you’re considering using tools like differential privacy or k-anonymity in your application, our cryptographic services team can help you navigate the inherent subtleties of these systems. Whether you need help with protocol design or auditing an existing codebase, our team can help you build something your users will be able to trust.