
Destroying x86_64 instruction decoders with differential fuzzing
TL;DR: x86_64 decoding is hard, and the number and variety of implementations available for it makes it uniquely suited to differential fuzzing. We’re open sourcing mishegos, a differential fuzzer for instruction decoders. You can use it to discover discrepancies in your own decoders and analysis tools!
In the beginning, there was instruction decoding
Decompilation and reverse engineering tools are massive, complicated beasts that deal with some of the hardest problems in binary analysis: variable type and layout recovery, control flow graph inference, and sound lifting to higher-order representations for both manual and automated inspection.
At the heart of each of these tasks is accurate instruction decoding. Automated tools require faithful extraction of instruction semantics to automate their analyses, and reverse engineers expect accurate disassembly listings (or well-defined failure modes) when attempting manual comprehension.
Instruction decoding is implicitly treated as a solved problem. Analysis platforms give analysts a false sense of confidence by encouraging them to treat disassembled output as ground truth, without regarding potential errors in the decoder or adversarial instruction sequences in the input.
Mishegos challenges this assumption.
(x86_64) Instruction decoding is hard
Like, really hard:
- Unlike RISC ISAs such as ARM and MIPS, x86_64 has variable-length instructions, meaning that decoder implementations must incrementally parse the input to know how many bytes to fetch. An instruction can be anywhere between 1 byte (e.g., 0x90,
nop) and 15 bytes long. Longer instructions may be semantically valid (i.e., they may describe valid combinations of prefixes, operations, and literals), but actual silicon implementations will only fetch and decode 15 bytes at most (see the Intel x64 Developer’s Manual, §2.3.11). - x86_64 is the 64-bit extension of a 32-bit extension of a 40-year-old 16-bit ISA designed to be source-compatible with a 50-year-old 8-bit ISA. In short, it’s a mess, with each generation adding and removing functionality, reusing or overloading instructions and instruction prefixes, and introducing increasingly complicated switching mechanisms between supported modes and privilege boundaries.
- Many instruction sequences have overloaded interpretations or plausible disassemblies, depending on the active processor’s state or compatibility mode. Disassemblers are required to make educated guesses, even when given relatively precise information about the compilation target or the expected execution mode.
The complexity of the x86_64 instruction format is especially apparent when visualized:
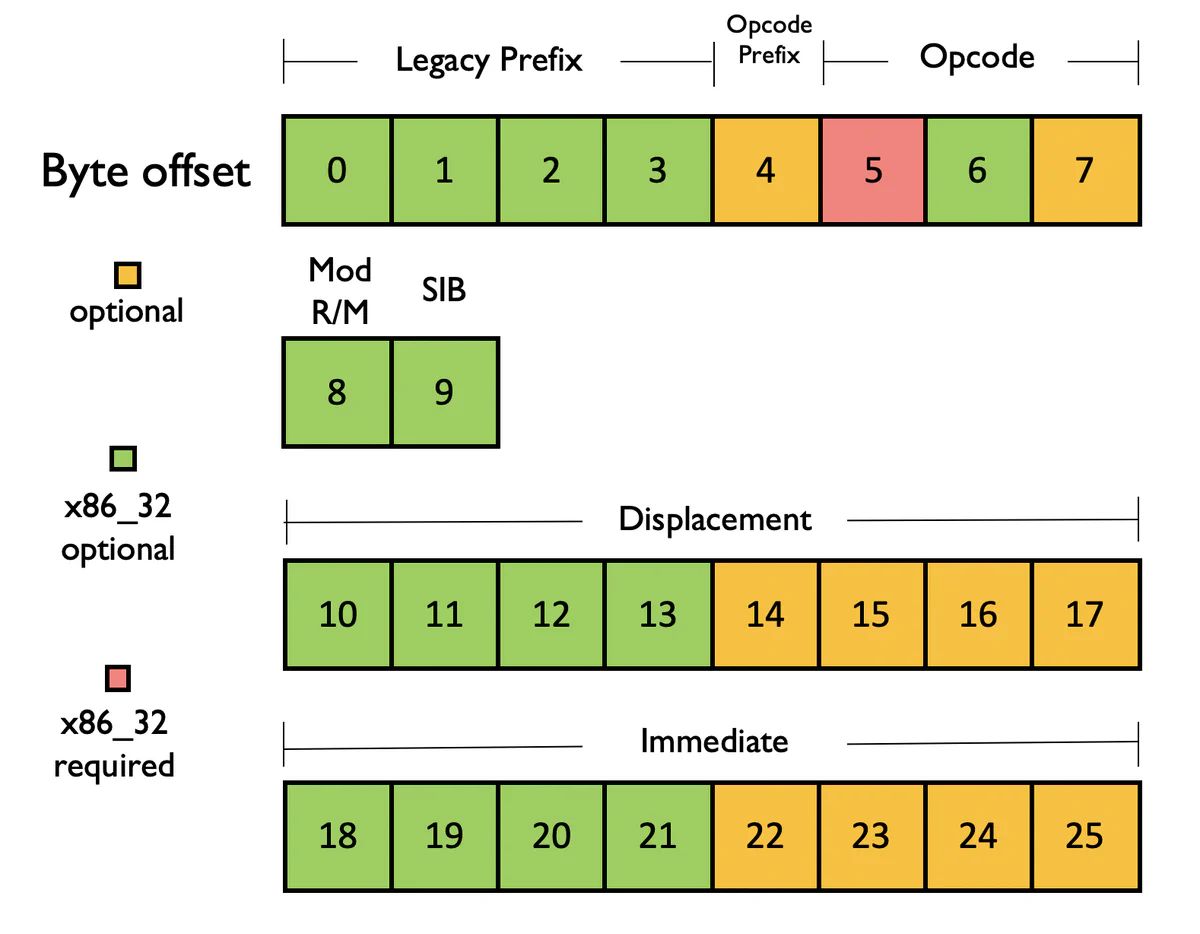
Even the graphic above doesn’t fully capture x86_64’s nuances—it ignores the internal complexity of the ModR/M and scale-index-base (SIB) bytes, as well as the opcode extension bit and various escaping formats for extended opcodes (legacy escape prefixes, VEX escape, and XOP escape).
All told, these complexities make x86_64 decoder implementations uniquely amenable to testing via differential fuzzing—by hooking a mutation engine up to several different implementations at once and comparing each collection of outputs, we can quickly suss out bugs and missing functionality.
Building a “sliding” mutation engine for x86_64 instructions
Given this layout and our knowledge about minimum and maximum instruction lengths on x86_64, we can construct a mutation engine that probes large parts of the decoding pipeline with a “sliding” strategy:
- Generate an initial instruction candidate of up to 26 bytes, including structurally valid prefixes and groomed ModR/M and SIB fields.
- Extract each “window” of the candidate, where each window is up to 15 bytes beginning at index 0 and moving to the right.
- Once all windows are exhausted, generate a new instruction candidate and repeat.
Why up to 26 bytes? See above! x86_64 decoders will only accept up to 15 bytes, but generating long, (potentially) semantically valid x86_64 instruction candidates that we “slide” through means we can test likely edge cases in decoding:
- Failing to handle multiple, duplicate instruction prefixes.
- Emitting nonsense prefixes or disassembly attributes (e.g., accepting and emitting a repeat prefix on a non-string operation, or the lock prefix on something that isn’t atomizable).
- Failing to parse the ModR/M or SIB bytes correctly, causing incorrect opcode decoding or bad displacement/immediate scaling/indexing.
so, a maximal instruction candidate, shown in purple (with dummy displacement and immediate values, shown in grey) like…
f0 f2 2e 67 46 0f 3a 7a 22 8e 00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f
… yields 12 “window” candidates for actual fuzzing.
f0 f2 2e 67 46 0f 3a 7a 22 8e 00 01 02 03 04
f2 2e 67 46 0f 3a 7a 22 8e 00 01 02 03 04 05
2e 67 46 0f 3a 7a 22 8e 00 01 02 03 04 05 06
67 46 0f 3a 7a 22 8e 00 01 02 03 04 05 06 07
46 0f 3a 7a 22 8e 00 01 02 03 04 05 06 07 08
0f 3a 7a 22 8e 00 01 02 03 04 05 06 07 08 09
3a 7a 22 8e 00 01 02 03 04 05 06 07 08 09 0a
7a 22 8e 00 01 02 03 04 05 06 07 08 09 0a 0b
22 8e 00 01 02 03 04 05 06 07 08 09 0a 0b 0c
8e 00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d
00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e
01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f
Consequently, our mutation engine spends a lot of time trying out different sequences of prefixes and flags, and relatively little time interacting with the (mostly irrelevant) displacement and immediate fields.
Mishegos: Differential fuzzing of x86_64 decoders
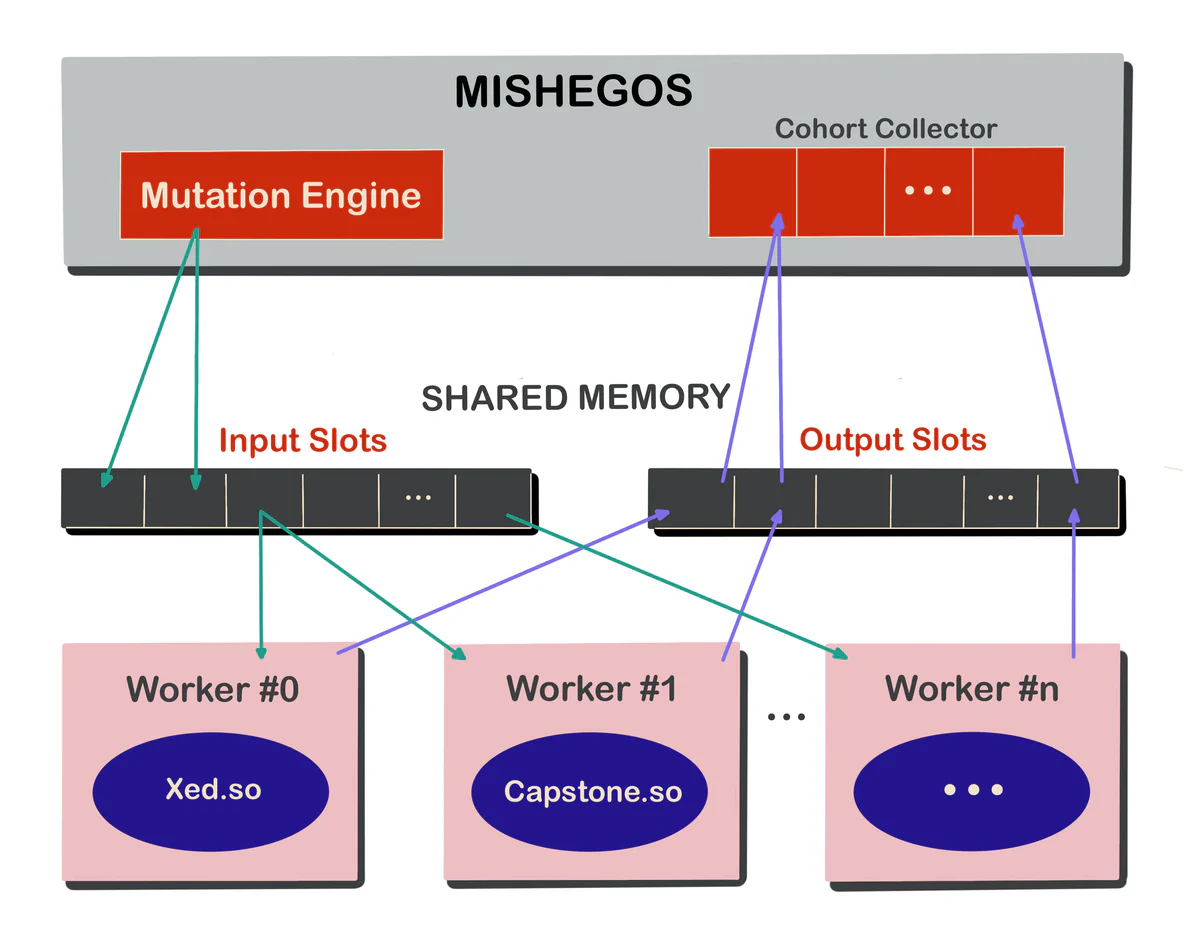
Mishegos takes the “sliding” approach above and integrates it into a pretty typical differential fuzzing scheme. Each fuzzing target is wrapped into a “worker” process with a well-defined ABI:
worker_ctorandworker_dtor: Worker setup and teardown functions, respectively.try_decode: Called for each input sample, returns the decoder’s results along with some metadata (e.g., how many bytes of input were consumed, the status of the decoder).worker_name: A constant string used to uniquely identify the type of worker.
The codebase currently implements five workers:
- Capstone—A popular disassembly framework originally based on the LLVM project’s disassemblers.
libbfd/libopcodes—The backing libraries used by the popular GNU binutils.- udis86—An older, potentially unmaintained decoder (last commit 2014).
- XED—Intel’s reference decoder.
- Zydis—Another popular open source disassembly library, with an emphasis on speed and feature-completeness.
Because of the barebones ABI, Mishegos workers tend to be extremely simple. The worker for Capstone, for example, is just 32 lines:
#include <capstone/capstone.h>
#include "../worker.h"
static csh cs_hnd;
char *worker_name = "capstone";
void worker_ctor() {
if (cs_open(CS_ARCH_X86, CS_MODE_64, &cs_hnd) != CS_ERR_OK) {
errx(1, "cs_open");
}
}
void worker_dtor() {
cs_close(&cs_hnd);
}
void try_decode(decode_result *result, uint8_t *raw_insn, uint8_t length) {
cs_insn *insn;
size_t count = cs_disasm(cs_hnd, raw_insn, length, 0, 1, &insn);
if (count > 0) {
result->status = S_SUCCESS;
result->len =
snprintf(result->result, MISHEGOS_DEC_MAXLEN, "%s %s\n", insn[0].mnemonic, insn[0].op_str);
result->ndecoded = insn[0].size;
cs_free(insn, count);
} else {
result->status = S_FAILURE;
}
}Behind the scenes, workers receive inputs and send outputs in parallel via slots, which are accessed through a shared memory region managed by the fuzzing engine. Input slots are polled via semaphores to ensure that each worker has retrieved a candidate for decoding; output slots are tagged with the worker’s name and instruction candidate to allow for later collection into cohorts. The result is a relatively fast differential engine that doesn’t require each worker to complete a particular sample before continuing: Each worker can consume inputs at its own rate, with only the number of output slots and cohort collection limiting overall performance.
The bird’s-eye view:
Making sense of the noise
Mishegos produces a lot of output: A single 60-second run on a not particularly fast Linux server (inside of Docker!) produces about 1 million cohorts, or 4 million bundled outputs (1 output per input per fuzzing worker with 4 workers configured):

Each output cohort is structured as a JSON blob, and looks something like this:
{
"input": "3626f3f3fc0f587c22",
"outputs": [
{
"ndecoded": 5,
"len": 21,
"result": "ss es repz repz cld \n",
"workerno": 0,
"status": 1,
"status_name": "success",
"worker_so": "./src/worker/bfd/bfd.so"
},
{
"ndecoded": 5,
"len": 5,
"result": "cld \n",
"workerno": 1,
"status": 1,
"status_name": "success",
"worker_so": "./src/worker/capstone/capstone.so"
},
{
"ndecoded": 5,
"len": 4,
"result": "cld ",
"workerno": 2,
"status": 1,
"status_name": "success",
"worker_so": "./src/worker/xed/xed.so"
},
{
"ndecoded": 5,
"len": 3,
"result": "cld",
"workerno": 3,
"status": 1,
"status_name": "success",
"worker_so": "./src/worker/zydis/zydis.so"
}
]
}In this case, all of the decoders agree: The first five bytes of the input decode to a valid cld instruction. libbfd is extra eager and reports the (nonsense) prefixes, while the others silently drop them as irrelevant.
But consistent successes aren’t what we’re interested in—we want discrepancies, dammit!
Discrepancies can occur along a few dimensions:
- One or more decoders disagree about how many bytes to consume during decoding, despite all reporting success.
- One or more decoders report failure (or success), in contrast to others.
- All decoders report success and consume the same number of input bytes, but one or more disagree about a significant component of the decoding (e.g., the actual opcode or immediate/displacement values).
Each of these has adversarial applications:
- Decoding length discrepancies can cause a cascade of incorrect disassemblies, preventing an automated tool from continuing or leaving a manual analyst responsible for realigning the disassembler.
- Outright decoding failures can be used to prevent usage of a susceptible tool or platform entirely, or to smuggle malicious code past an analyst.
- Component discrepancies can be used to mislead an analysis or human analyst into incorrectly interpreting the program’s behavior. Severe enough discrepancies could even be used to mask the recovered control flow graph!
Mishegos discovers each of these discrepancy classes via its analysis tool and presents them with mishmat, a hacky HTML visualization. The analysis tool collects language-agnostic “filters” into “passes” (think LLVM), which can then order their internal filters either via a dependency graph or based on perceived performance requirements (i.e., largest filters first). Passes are defined in ./src/analysis/passes.yml, e.g.:
# Find inputs that all workers agree are one size, but one or more
# decodes differently.
same-size-different-decodings:
- filter-any-failure
- filter-ndecoded-different
- filter-same-effects
- minimize-input
- normalizeIndividual filters are written as small scripts that take cohorts on stdin and conditionally emit them on stdout. For example, filter-ndecoded-different:
require "json"
STDERR.puts "[+] pass: filter-ndecoded-different"
count = 0
STDIN.each_line do |line|
result = JSON.parse line, symbolize_names: true
outputs_ndecoded = result[:outputs].map { |o| o[:ndecoded] }
if outputs_ndecoded.uniq.size > 1
count += 1
next
end
STDOUT.puts result.to_json
end
STDERR.puts "[+] pass: filter-ndecoded-different done: #{count} filtered"Filters can also modify individual results or entire cohorts. The minimize-input filter chops the instruction candidate down to the longest indicated ndecoded field, and the normalize filter removes extra whitespace in preparation for additional analysis of individual assemblies.
Finally, passes can be run as a whole via the analysis command-line:
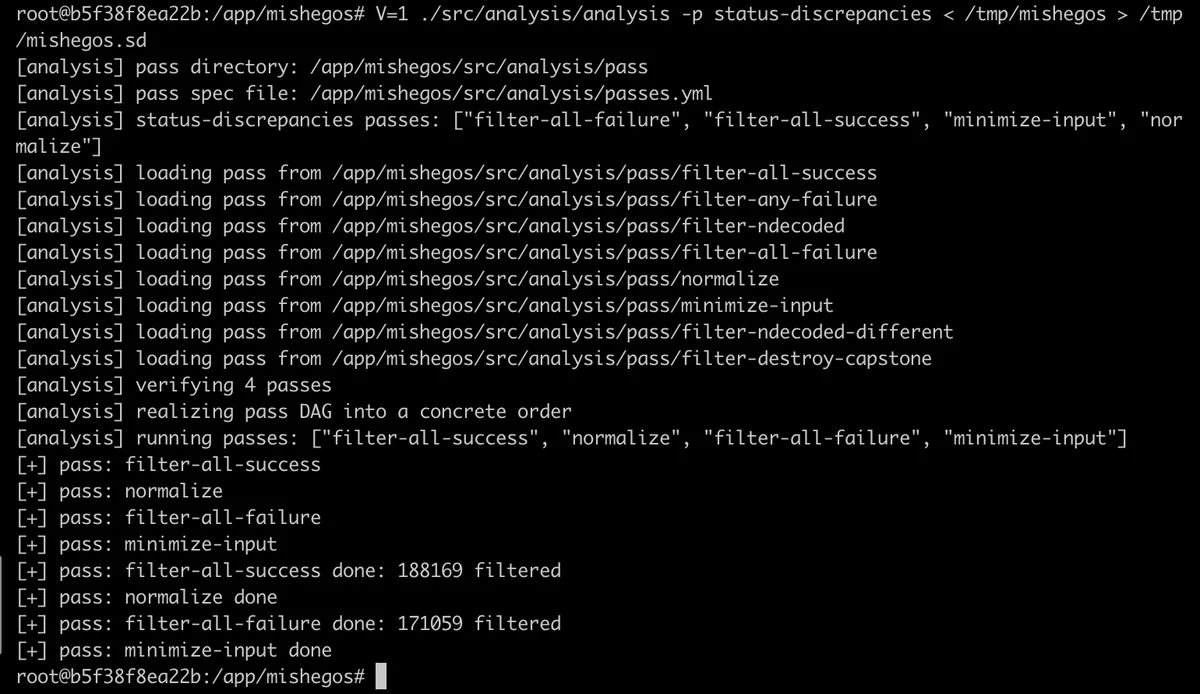
The analysis output can be visualized with mishmat, with an optional cap on the size of the HTML table:
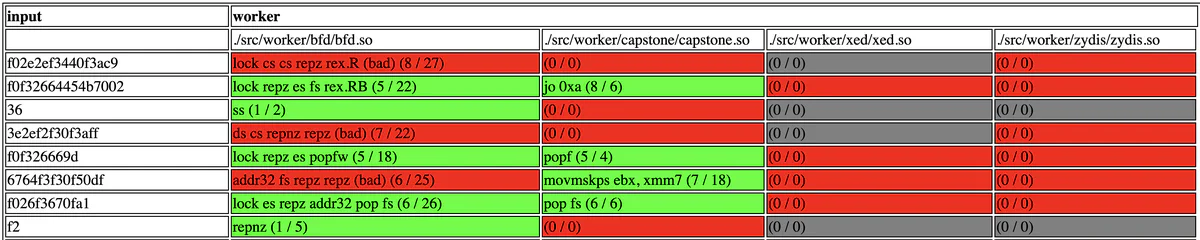
mishmat -l 10000 < /tmp/mishegos.sd > /tmp/mishegos.sd.htmlUltimately, this yields fun results like the ones below (slightly reformatted for readability). Instruction candidates are on the left, individual decoder results are labeled by column. (bad) in libbfd‘s column indicates a decoding failure. The (N/M) syntax represents the number of bytes decoded (N) and the total length of the assembled string (M):
| libbfd | capstone | zydis | xed | |
|---|---|---|---|---|
| f3f326264e0f3806cc | repz repz es es rex.WRX (bad) (8 / 29) | phsubd mm1, mm4 (9 / 15) | (0 / 0) | (0 / 0) |
| 26f366364f0f38c94035 | es data16 ss rex.WRXB (bad) (8 / 27) | sha1msg1 xmm8, xmmword ptr ss:[r8 + 0x35] (10 / 41) | (0 / 0) | (0 / 0) |
| f366364f0f38c94035 | data16 ss rex.WRXB (bad) (7 / 24) | sha1msg1 xmm8, xmmword ptr ss:[r8 + 0x35] (9 / 41) | (0 / 0) | (0 / 0) |
| 66364f0f38c94035 | ss rex.WRXB (bad) (6 / 17) | sha1msg1 xmm8, xmmword ptr ss:[r8 + 0x35] (8 / 41) | (0 / 0) | (0 / 0) |
Figure 12: Capstone thinking that nonsense decodes to valid SSE instructions.
| libbfd | capstone | zydis | xed | |
|---|---|---|---|---|
| f36766360f921d32fa9c83 | repz data16 setb BYTE PTR ss:[eip+0xffffffff839cfa32] # 0xffffffff839cfa3d (11 / 74) | (0 / 0) | setb byte ptr [eip-0x7c6305ce] (11 / 30) | setb byte ptr ss:[0x00000000839CFA3D] (11 / 37) |
Figure 13: Capstone missing an instruction entirely.
| libbfd | capstone | zydis | xed | |
|---|---|---|---|---|
| 3665f0f241687aa82c8d | ss gs lock repnz rex.B push 0xffffffff8d2ca87a (10 / 46) | push -0x72d35786 (10 / 16) | (0 / 0) | (0 / 0) |
| 65f0f241687aa82c8d | gs lock repnz rex.B push 0xffffffff8d2ca87a (9 / 43) | push -0x72d35786 (9 / 16) | (0 / 0) | (0 / 0) |
| f0f241687aa82c8d | lock repnz rex.B push 0xffffffff8d2ca87a (8 / 40) | push -0x72d35786 (8 / 16) | (0 / 0) | (0 / 0) |
Figure 14: Amusing signed representations.
| libbfd | capstone | zydis | xed | |
|---|---|---|---|---|
| 3e26f0f2f1 | ds es lock repnz icebp (5 / 22) | int1 (5 / 4) | (0 / 0) | (0 / 0) |
Figure 15: Undocumented opcode discrepancies!
| libbfd | capstone | zydis | xed | |
|---|---|---|---|---|
| f3430f38f890d20aec2c | repz rex.XB (bad) (5 / 17) | (0 / 0) | enqcmds rdx, zmmword ptr [r8+0x2cec0ad2] (10 / 40) | enqcmds rdx, zmmword ptr [r8+0x2CEC0AD2] (10 / 40) |
| 2e363e65440f0dd8 | cs ss ds gs rex.R prefetch (bad) (6 / 32) | (0 / 0) | nop eax, r11d (8 / 13) | nop eax, r11d (8 / 13) |
| f2f266260fbdee | repnz data16 es (bad) (6 / 21) | (0 / 0) | bsr bp, si (7 / 10) | bsr bp, si (7 / 10) |
Figure 16: XED and Zydis only.
| libbfd | capstone | zydis | xed | |
|---|---|---|---|---|
| 64f064675c | fs lock fs addr32 pop rsp (5 / 25) | (0 / 0) | (0 / 0) | (0 / 0) |
| 2e | cs (1 / 2) | (0 / 0) | (0 / 0) | (0 / 0) |
| f06636f00f3802c7 | lock ss lock phaddd xmm0,xmm7 (8 / 29) | (0 / 0) | (0 / 0) | (0 / 0) |
| f03e4efd | lock ds rex.WRX std (4 / 19) | (0 / 0) | (0 / 0) | (0 / 0) |
| 36f03e4efd | ss lock ds rex.WRX std (5 / 22) | (0 / 0) | (0 / 0) | (0 / 0) |
Figure 17: And, of course, libbfd being utterly and repeatedly wrong.
The results above were captured with revision 88878dc on the repository. You can reproduce them by running the fuzzer in manual mode:
M=1 mishegos ./workers.spec <<< “36f03e4efd” > /tmp/mishegosThe big takeaways
For reverse engineers and program analysts: x86_64 instruction decoding is hard. The collection of tools that you rely on to do it are not, in fact, reliable. It is possible (and even trivial), given Mishegos’s output, to construct adversarial binaries that confuse your tools and waste your time. We’ve reported some of these issues upstream, but make no mistake: Trusting your decoder to perfectly report the machine behavior of a byte sequence will burn you.
Not everything is doom and gloom. If you need accurate instruction decoding (and you do!), you should use XED or Zydis. libopcodes is frequently close to Zydis and XED in terms of instruction support but consistently records false positives and decodes just prefixes as valid instructions. Capstone reports both false positives and false negatives with some regularity. udis86 (not shown above) behaves similarly to libopcodes and, given its spotty maintenance, should not be used.
This post is one of many from our team on the vagaries of parsing. Watch this space for a post by Evan Sultanik on polyglots and schizophrenic parsing.