
Assessing the security posture of a widely used vision model: YOLOv7
TL;DR: We identified 11 security vulnerabilities in YOLOv7, a popular computer vision framework, that could enable attacks including remote code execution (RCE), denial of service, and model differentials (where an attacker can trigger a model to perform differently in different contexts).
Open-source software provides the foundation of many widely used ML systems. However, these frameworks have been developed rapidly, often at the cost of secure and robust practices. Furthermore, these open-source models and frameworks are not specifically intended for critical applications, yet they are being adopted for such applications at scale, through momentum or popularity. Few of these software projects have been rigorously reviewed, leading to latent risks and a rise of unidentified supply chain attack surfaces that impact the confidentiality, integrity, and availability of the model and its associated assets. For example, pickle files, used widely in the ML ecosystem, can be exploited to achieve arbitrary code execution.
Given these risks, we decided to assess the security of a popular and well-established vision model: YOLOv7. This blog post shares and discusses the results of our review, which comprised a lightweight threat model and secure code review, including our conclusion that the YOLOv7 codebase is not suitable for mission-critical applications or applications that require high availability. A link to the full public report is available.
Disclaimer: YOLOv7 is a product of academic work. Academic prototypes are not intended to be production-ready nor have appropriate security hygiene, and our review is not intended as a criticism of the authors or their development choices. However, as with many ML prototypes, they have been adopted within production systems (e.g., as YOLOv7 is promoted by Roboflow, with 3.5k forks). Our review is only intended to bring to light the risks of using such prototypes without further security scrutiny.
As part of our responsible disclosure policy, we contacted the authors of the YOLOv7 repository to make them aware of the issues we identified. We did not receive a response, but we propose concrete solutions and changes that would mitigate the identified security gaps.
What is YOLOv7?
You Only Look Once (YOLO) is a state-of-the-art, real-time object detection system whose combination of high accuracy and good performance has made it a popular choice for vision systems embedded in mission-critical applications such as robotics, autonomous vehicles, and manufacturing. YOLOv1 was initially developed in 2015; its latest version, YOLOv7, is the open-source codebase revision of YOLO developed by Academia Sinica that implements their corresponding academic paper, which outlines how YOLOv7 outperforms both transformer-based object detectors and convolutional-based object detectors (including YOLOv5).
The codebase has over 3k forks and allows users to provide their own pre-trained files, model architecture, and dataset to train custom models. Even though YOLOv7 is an academic project, YOLO is the de facto algorithm in object detection, and is often used commercially and in mission-critical applications (e.g., by Roboflow).
What we found
Our review identified five high-severity and three medium-severity findings, which we attribute to the following insecure practices:
- The codebase is not written defensively; it has no unit tests or testing framework, and inputs are poorly validated and sanitized.
- Complete trust is placed in model and configuration files that can be pulled from external sources.
- The codebase dangerously and unnecessarily relies on permissive functions in ways that introduce vectors for RCE.
The table below summarizes our high-severity findings:
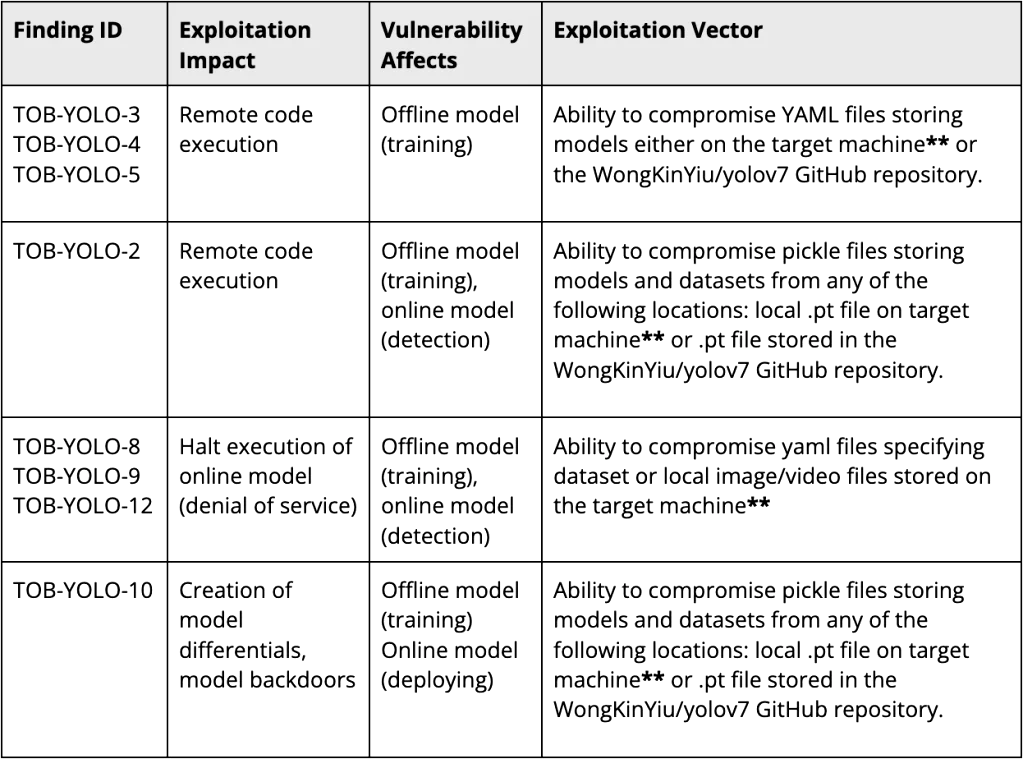
**It is common practice to download datasets, model pickle files, and YAML configuration files from external sources, such as PyTorch Hub. To compromise these files on a target machine, an attacker could upload a malicious file to one of these public sources.
Building the threat model
For our review, we first carried out a lightweight threat model to identify threat scenarios and the most critical components that would in turn inform our code review. Our approach draws from Mozilla’s “Rapid Risk Assessment” methodology and NIST’s guidance on data-centric threat modeling (NIST 800-154). We reviewed YOLO academic papers, the YOLOv7 codebase, and user documentation to identify all data types, data flow, trust zones (and their connections), and threat actors. These artifacts were then used to develop a comprehensive list of threat scenarios that document each of the possible threats and risks present in the system.
The threat model accounts for the ML pipeline’s unique architecture (relative to traditional software systems), which introduces novel threats and risks due to new attack surfaces within the ML lifecycle and pipeline such as data collection, model training, and model inference and deployment. Corresponding threats and failures can lead to the degradation of model performance, exploitation of the collection and processing of data, and manipulation of the resulting outputs. For example, downloading a dataset from an untrusted or insecure source can lead to dataset poisoning and model degradation.
Our threat model thus aims to examine ML-specific areas of entry as well as outline significant sub-components of the YOLOv7 codebase. Based on our assessment of YOLOv7 artifacts, we constructed the following data flow diagram.
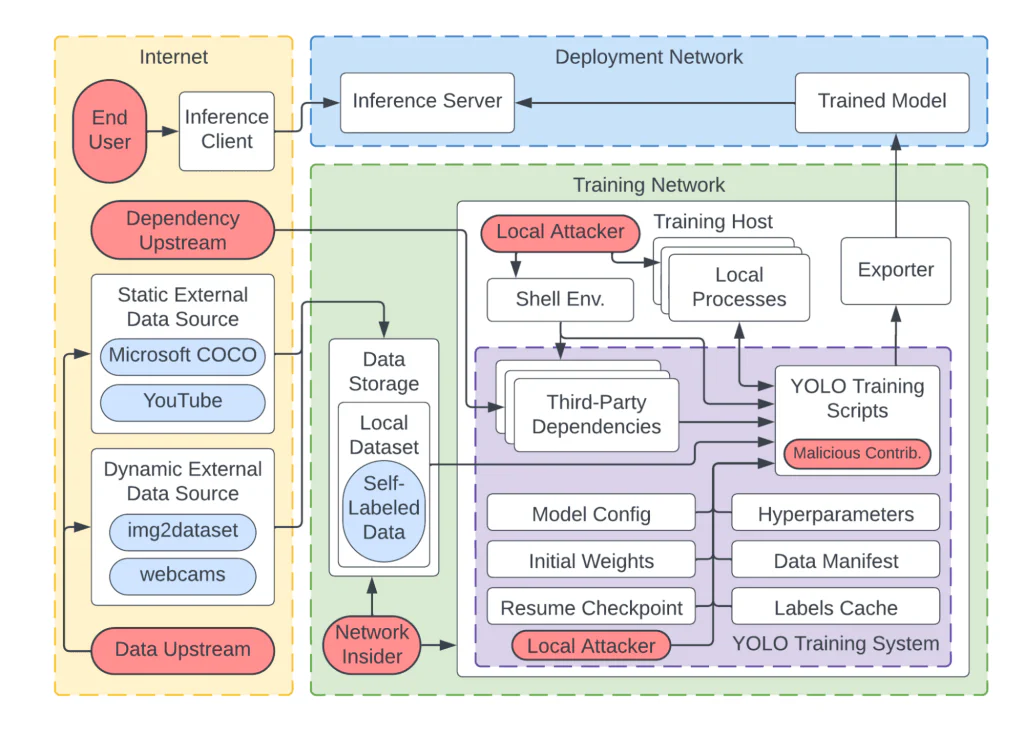
Note that this diagram and our threat model do not target a specific application or deployment environment. Our identified scenarios were tailored to bring focus to general ML threats that developers should consider before deploying YOLOv7 within their ecosystem. We identified a total of twelve threat scenarios pertaining to three primary threats: dataset compromise, host compromise, and YOLO process compromise (such as injecting malicious code into the YOLO system or one of its dependencies).
Code review results
Next, we performed a secure code review of the YOLOv7 codebase, focusing on the most critical components identified in the threat model’s threat scenarios. We used both manual and automated testing methods; our automated testing tools included Trail of Bits’ repository of custom Semgrep rules, which target the misuse of ML frameworks such as PyTorch and which identified one security issue and several code quality issues in the YoloV7 codebase. We also used the TorchScript automatic trace checking tool to automatically detect potential errors in traced models. Finally, we used the public Python CodeQL queries across the codebase and identified multiple code quality issues.
In total, our code review resulted in the discovery of twelve security issues, five of which are high severity. The review also uncovered twelve code quality findings that serve as recommendations for enhancing the quality and readability of the codebase and preventing the introduction of future vulnerabilities.
All of these findings are indicative of a system that was not written or designed with a defensive lens:
- Five security issues could individually lead to RCE, most of which are caused by the unnecessary and dangerous use of permissive functions such as
subprocess.check_output,eval, andos.system. See the highlight below for an example. - User and external data inputs are poorly validated and sanitized. Multiple issues enable a denial-of-service attack if an end user can control certain inputs, such as model files, dataset files, or configuration files (TOB-YOLO-9, TOB-YOLO-8, TOB-YOLO-12). For example, the codebase allows engineers to provide their own configuration files, whether they represent a different model architecture or are pre-trained files (given the different applications of the YOLO model architecture). These files and datasets are loaded into the training network where PyTorch is used to train the model. For a more secure design, the amount of trust placed into external inputs needs to be drastically reduced, and these values need to be carefully sanitized and validated.
- There are currently no unit tests or any testing framework in the codebase (TOB-YOLO-11). A proper testing framework would have prevented some of the issues we uncovered, and without this framework it is likely that other implementation flaws and bugs exist in the codebase. Moreover, as the system continues to evolve, without any testing, code regressions are likely to occur.
Below, we highlight some of the details of our high severity findings and discuss their repercussions on ML-based systems.
Secure code review highlight #1: How YAML parsing leads to RCE
Our most notable finding regards the insecure parsing of YAML files that could result in RCE. Like many ML systems, YOLO uses YAML files to specify the architecture of models. Unfortunately, the YAML parsing function, parse_model, parses the contents of the file by calling eval on unvalidated contents of the file, as shown in this code snippet:

If an attacker is able to manipulate one of these YAML files used by a target user, they could inject malicious code that would be executed during this parsing. This is particularly concerning since these YAML files are often obtained from third-party websites that host these files along with other model files and datasets. A sophisticated attacker could compromise one of these third-party services or hosted assets. However, this issue can be detected through proper inspection of these YAML files, if done closely and often.
Given the potential severity of this finding, we proposed an alternative implementation as a mitigation: remove the need for the parse_model function altogether by rewriting the given architectures defined in config files as different block classes that call standard PyTorch modules. This rewrite serves a few different purposes:
- It removes the inherent vulnerability present in calling
evalon unsanitized input. - The block class structure more effectively replicates the architecture proposed in the implemented paper, allowing for easier replication of the given architecture and definition of subsequent iterations of similar structures.
- It presents a more extensible base to continue defining configurations, as the classes are easily modifiable based on different parameters set by the user.
Our proposed fix can be tracked in this GitHub issue.
Secure code review highlight #2: ML-specific vulnerabilities and improvements
As previously noted, ML frameworks are leading to a rise of novel attack avenues targeting confidentiality, integrity, and availability of the model and its associated assets. Highlights from the ML-specific issues that we uncovered during our security assessment include the following:
- The YOLOv7 codebase uses pickle files to store models and datasets; these files have not been verified and may have been obtained from third-party sources. We previously found that the widespread use of pickle files in the ML ecosystem is a security risk, as pickle files enable arbitrary code execution. To deserialize a pickle file, a virtual machine known as the Pickle Machine (PM) interprets the file as a sequence of opcodes. Two opcodes contained in the PM,
GLOBALandREDUCE, can execute arbitrary Python code outside of the PM, thereby enabling arbitrary code execution. We built and released fickling, a tool to reverse engineer and analyze pickle files; however, we further recommend that ML implementations use safer file formats instead such as safetensors. - The way YOLOv7 traces its models could lead to model differentials—that is, the traced model that is being deployed behaves differently from the original, untraced model. In particular, YOLO uses PyTorch’s torch.jit.trace to convert its models into the TorchScript format for deployment. However, the YOLOv7 models contain many tracer edge cases: elements of the model that are not accurately captured by tracing. The most notable occurrence was the inclusion of input-dependent control flow. We used TorchScript’s automatic trace checker to confirm this divergence by generating an input that had different outputs depending on whether or not the model was traced, which could lead to backdoors. An attacker could release a model that exhibits a specific malicious behavior only when it is traced, making it harder to catch.
Specific recommendations and mitigations are outlined in our report.
Enhancing YOLOv7’s security
Beyond the identified code review issues, a series of design and operational changes are needed to ensure sufficient security posture. Highlights from the list of strategic recommendations provided in our report include:
- Implementing an adequate testing framework with comprehensive unit tests and integration tests
- Removing the use of highly permissive functions, such as
subprocess.check_output,eval, andos.system - Improving development process of the codebase
- Enforcing the usage of secure protocols, such as HTTPS and RMTPS, when available
- Continuously updating dependencies to ensure upstream security fixes are applied
- Providing documentation to users about the potential threats when using data from untrusted training data or webcam streams
Although the identified security gaps may be acceptable for academic prototypes, we do not recommend using YOLOv7 within mission-critical applications or domains, despite existing use cases. For affected end users who are already using and deploying YOLOv7, we strongly recommend disallowing end users from providing datasets, model files, configuration files, and any other type of external inputs until the recommended changes are made to the design and maintenance of YOLOv7.
Coordinated disclosure timeline
As part of the disclosure process, we reported the vulnerabilities to the YOLOv7 maintainers first. Despite multiple attempts, we were not able to establish contact with the maintainers in order to coordinate fixes for these vulnerabilities. As a result, at the time of this blog post being released, the identified issues remain unfixed. As mentioned, we have proposed a fix to one of the issues that is being tracked in this GitHub issue. The timeline of disclosure is provided below:
- May 24, 2023: We notified the YOLOv7 maintainers that we intend to review the YOLOv7 codebase for internal purposes and invited them to participate and engage in our audit.
- June 9, 2023: We notified the maintainers that we have begun the audit, and again invited them to participate and engage with our efforts.
- July 10, 2023: We notified the maintainers that we had several security findings and requested engagement to discuss them.
- July 26, 2023: We informed the maintainers of our official security disclosure notice with a release date of August 21, 2023.
- November 15, 2023: The disclosure blog post was released and issues were filed with the original project repository.