
Secure your machine learning with Semgrep
tl;dr: Our publicly available Semgrep ruleset now has 11 rules dedicated to the misuse of machine learning libraries. Try it out now!
Picture this: You’ve spent months curating images, trying out different architectures, downloading pretrained models, messing with Kubernetes, and you’re finally ready to ship your sparkling new machine learning (ML) product. And then you get the (hopefully not dreaded) question: What security measures have you put into place?
Maybe you’ve already applied tools like Counterfit and PrivacyRaven to test your model against model extraction and model inversion, but that shouldn’t be the end. You’re not just building a model; you’re building a pipeline. And the crux of your pipeline is the source code. ML models cannot be treated as standalone objects. Their creators must account for every element of the pipeline, from preprocessing procedures to the underlying hardware.
Semgrep is a powerful static analysis tool that enables users to search for potentially problematic code patterns at scale. Previously, we released several Semgrep rules to find goroutine leaks that are included in our public set of Semgrep rules. To strengthen the ML ecosystem, we’ve analyzed the source code of many ML libraries and identified some common problematic patterns. Instead of relying on developers to thoroughly examine the source code or documentation of each library they use, we decided to turn these patterns into Semgrep rules to make it easy to find and fix potential vulnerabilities.
Finding Wild, Distributed Pickles in the Land of a Thousand Pickles
Unfortunately, the ML ecosystem is the land of a thousand pickles. Pickling, a particularly popular practice for saving ML models, pops up in a plethora of tools and libraries. However, pickling is incredibly insecure and can easily lead to arbitrary code execution. To address this problem, we released Fickling, a tool to reverse engineer and create malicious pickle files, last year. But plenty of libraries still use pickling under the hood, and even security-savvy developers can end up using them. Let’s take a look at one subtle instance of pickling in a prominent ML library: PyTorch Distributed.
The high computational demand of deep learning pushes developers to use distributed systems where computations can be parallelized across many machines and devices. In these systems, a number of processes form a group, and communication occurs within this group. Some groups require developers to leverage point-to-point communication in order to transfer data between processes, while others require collective communication. Many libraries focus on distributed ML, and each of these libraries enables objects to broadcast from one process to others in the group.
PyTorch Distributed provides users with broadcast_object_list, a function that shares a list of objects to other nodes in a group. Its usage is demonstrated in the following code snippet obtained from the PyTorch Distributed documentation:

To share the aforementioned list of objects, the list is first pickled. This allows an attacker to craft a malicious pickle file that can execute arbitrary code throughout the system.
The documentation also shows a warning about implicit usage of pickle in this function, as shown below:

Despite the warning, it’s not immediately clear to a developer that this is an insecure application of pickling. We found multiple functions with the same problem in this package, so we created the following Semgrep rule to help users avoid the call of the wild pickle.
rules:
- id: pickles-in-torch-distributed
patterns:
- pattern-either:
- pattern: torch.distributed.broadcast_object_list(...)
- pattern: torch.distributed.all_gather_object(...)
- pattern: torch.distributed.gather_object(...)
- pattern: torch.distributed.scatter_object_list(...)
message: |
Functions reliant on pickle can result in arbitrary code execution.
For more information, see https://blog.trailofbits.com/2021/03/15/never-a-dill-moment-exploiting-machine-learning-pickle-files/
languages: [python]
severity: WARNINGBig Pickle Strikes Again
NumPy, another important library used by ML developers, converts external data into NumPy arrays and performs different operations. Pickles also pop up in NumPy, namely in numpy.load(), as shown below:
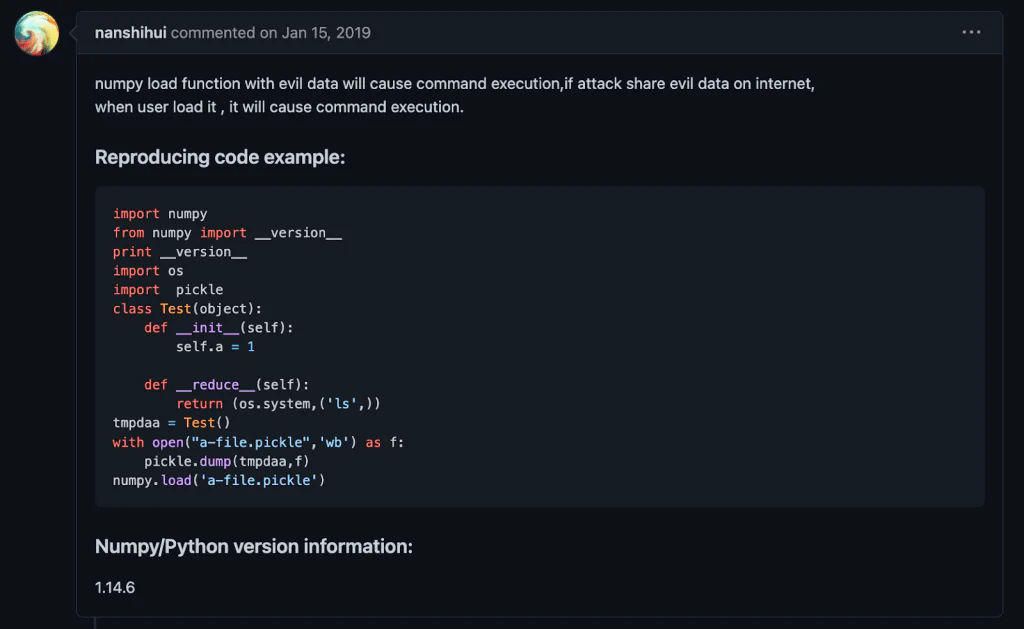
In NumPy versions 1.16.0 and earlier, np.load() allowed pickles by default, thereby enabling arbitrary code execution. After CVE-2019-6446, newer versions of NumPy set allow_pickle to False by default. You can check out the reporting of this vulnerability and the response of the NumPy maintainers on GitHub (see the image above).
As shown below, the code sets the allow_pickle flag to True and updates the earlier PoC for newer versions of NumPy:
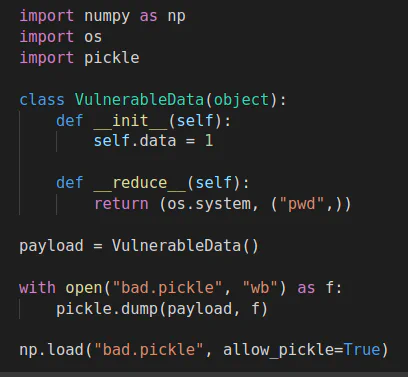
More specifically, we created a class, pickled it, and then loaded it in NumPy. Because the class’s __reduce__ method contains the pwd command, NumPy will run ls when it tries to load the file, thereby demonstrating arbitrary code execution. A similar proof of concept can be found in the fickling repository. To find bug patterns like this one, we developed the following Semgrep rule:
rules:
- id: pickles-in-numpy
patterns:
- pattern: numpy.load(..., allow_pickle=$VALUE)
- metavariable-regex:
metavariable: $VALUE
regex: (True|^\d*[1-9]\d*$)
message: |
Functions reliant on pickle can result in arbitrary code execution.
Consider using fickling or switching to a safer serialization method.
For more information, see https://blog.trailofbits.com/2021/03/15/never-a-dill-moment-exploiting-machine-learning-pickle-files/
languages:
- python
severity: ERRORTypically, developers will set an argument to True only when they want to use it. However, this argument will also be valid when you set it equal to any positive number. Therefore, to make our rule robust to variations, we used Semgrep’s metavariable-regex feature to write a regular expression that searches for the different values that enable pickling. Otherwise, this rule would result in a false negative for the aforementioned situation or a false positive for allow_pickle=False.
Not-so-random Randomness
Can you spot the bug in the following code?

This code will result in identical augmentations because of faulty random number generation! Last year, Tanel Pärnamaa wrote a blog post on a subtle bug that occurs when using PyTorch and NumPy. More concretely, multiple workers are used to load data in parallel, and each worker inherits the same initial state of the NumPy random number generator. According to Pärnamaa, this bug has been fixed in newer versions of PyTorch, but it still exists in Keras. I encourage you to explore other frameworks and try to replicate this issue.
Clearly, many issues can arise in ML from discrepancies with parallel and distributed computing and randomness. We at Trail of Bits are no strangers to random number generation issues. They are well known as the spectre of cryptographic implementations. To attack ML models, Ilia Shumailov et al. developed data ordering attacks wherein an attacker controls the order in which data is supplied to the model in order to prevent the model from learning or to inject backdoors. Furthermore, multiple studies have examined non-determinism and numerical instability in ML tooling, which we must remove from these tools and avoid in our own ML code.
We wrote the following rule to avoid this bug:
rules:
- id: numpy-in-torch-datasets
patterns:
- pattern-either:
- pattern: |
class $X(Dataset):
...
def __getitem__(...):
...
np.random.randint(...)
...
- pattern: |
class $X(Dataset):
...
def __getitem__(...):
...
$Y = np.random.randint(...)
...
message: |
Using the NumPy RNG inside of a Torch dataset can lead to a number of issues with loading data, including identical augmentations.
Instead, use the random number generators built into Python and PyTorch.
See https://tanelp.github.io/posts/a-bug-that-plagues-thousands-of-open-source-ml-projects/ for more details
languages: [python]
severity: WARNINGThis bug is not the only reason to avoid using NumPy operations in Torch datasets and models. The Open Neural Network eXchange (ONNX) is a file format for storing ML models based on Protobufs. However, using NumPy operations inside a model can result in improper tracing and a malformed ONNX file. In addition, PyTorch provides FX, which includes a symbolic tracer for PyTorch models; using NumPy and other non-Torch functions inside the model can prohibit symbolic tracing. This can also limit the efficiency of the ML model and prevent you from using TorchScript. Therefore, we created a rule to catch instances of NumPy operations in Torch models.
Fermenting a secure future
The effort to develop Semgrep rules to find and fix vulnerabilities is ongoing. As these ML libraries, and the community as a whole, continue to mature, it’s our hope that tools like Semgrep can help protect against misuse.
Given that machine learning is a big priority for Trail of Bits, we fully expect to find more bugs in ML libraries and release tools that will allow others to discover and correct them. But we need your help. Please let us know if you have any suggestions for other potential issues that can be prevented using tools like Semgrep. Feel free to raise an issue on our repository or contact me at [email protected].
Appendix 1: Rules
Here are the rules for ML libraries we’ve added to our repository so far:
| Rule ID | Language | Finding |
|---|---|---|
| automatic-memory-pinning | Python | Memory is not automatically pinned |
| lxml-in-pandas | Python | Potential XXE attacks from loading lxml in pandas |
| numpy-in-pytorch-modules | Python | Uses NumPy functions inside PyTorch modules |
| numpy-in-torch-datasets | Python | Calls to the Number RNG inside of a Torch dataset |
| pickles-in-numpy | Python | Potential arbitrary code execution from NumPy functions reliant on pickling |
| pickles-in-pandas | Python | Potential arbitrary code execution from Pandas functions reliant on pickling |
| pickles-in-pytorch | Python | Potential arbitrary code execution from PyTorch functions reliant on pickling |
| pickles-in-torch-distributed | Python | Potential arbitrary code execution from PyTorch Distributed functions reliant on pickling |
| torch-package | Python | Potential arbitrary code execution from torch.package |
| torch-tensor | Python | Possible parsing issues and inefficiency from improper tensor creation |
| waiting-with-torch-distributed | Python | Possible undefined behavior when not waiting for requests |