
DeepState Now Supports Ensemble Fuzzing
We are proud to announce the integration of ensemble fuzzing into DeepState, our unit-testing framework powered by fuzzing and symbolic execution. Ensemble fuzzing allows testers to execute multiple fuzzers with varying heuristics in a single campaign, while maintaining an architecture for synchronizing generated input seeds across fuzzer queues.
This new ensemble fuzzer includes a new deepstate-ensembler tool and several notable fuzzer engines powered by a new and open-sourced DeepState front-end API/SDK. This SDK enables developers to integrate front-end executors for DeepState and provides seed synchronization support for our ensembler tool.
The Fallacy of Smart Fuzzers
Fuzzers are one of the most effective tools in a security researcher’s toolbox. In recent years, they have been widely studied to build better heuristics, or strategies that fuzzers use to explore programs. However, one thing remains clear: fuzzer heuristics rarely live up to their hype. When scaling up so-called smart fuzzers for real-world programs, their performance often falters, and we end up defaulting back to our “dumb” standard tooling, like AFL and LibFuzzer.
Since we have explored the topic of evaluating fuzzing research in the past, let’s take a tangent and instead explore the possibility of combining various fuzzer heuristics to maximize fuzzer performance, without giving up time in our testing workflow. This led to my summer internship project of integrating ensemble fuzzing into DeepState.
What is Ensemble Fuzzing?
The insight from ensemble fuzzing is that, while certain heuristics work well in certain contexts, combining them should produce greater results than just a single fuzzer with a single strategy. This idea was first introduced in Chen et al.’s EnFuzz paper, however, there are no available open-source or commercial implementations.
Our implementation of an ensemble fuzzer follows the architecture implemented in EnFuzz, as seen below:
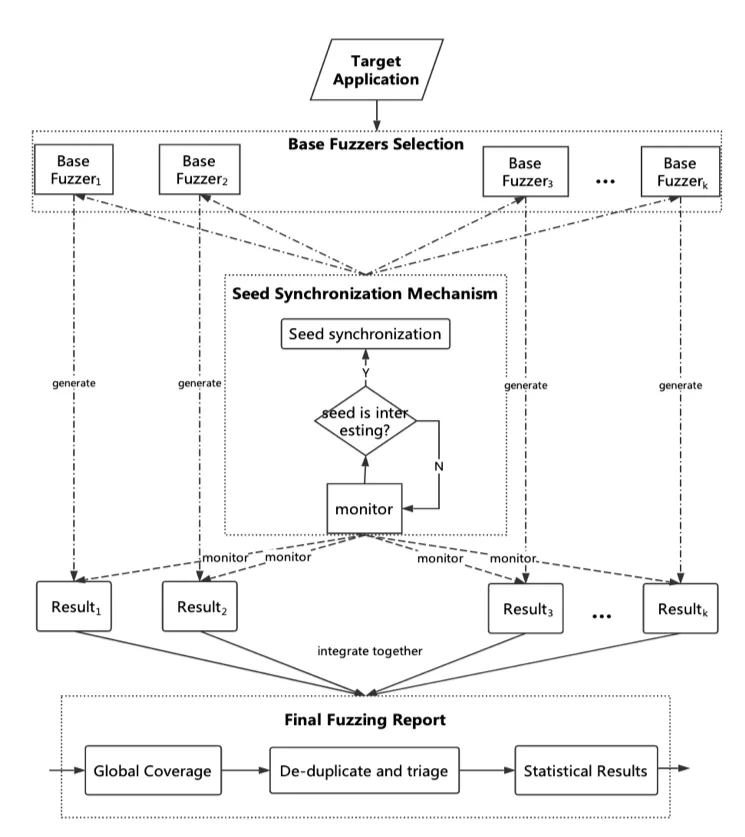
Given a set of pre-determined diverse base fuzzers with respective local seed queues, we can integrate a global-asynchronous and local-synchronous (GALS) seed synchronization mechanism that pulls interesting seeds from local queues to a shared global queue during an execution cycle. Therefore, as a base fuzzer’s heuristics fail to improve coverage or discover interesting input seeds, it can now pull other fuzzers’ seeds from this global queue in the next execution cycle. Furthermore, once the campaign is terminated, we can receive any fuzzing feedback from the ensembler regarding base fuzzer performance, crash triaging/deduplication, or any other post-processing statistics.
Using ensemble fuzzing and our already powerful unit-testing framework for fuzzing/symbolic execution, DeepState, we are able to approach the following problems during testing:
- Fuzzer performance diversity – do different fuzzer heuristics contribute varying useful seeds, maximizing the potential for improving coverage and crashes discovered?
- Fuzzer workflow – how can we do exhaustive fuzz testing and/or symbolic execution while simplifying our workflow?
- Invariant consistency – do different fuzzers return different results, indicating that there might be a source of nondeterminism in our test?
Spinning up Front-ends
Since DeepState already supports Eclipser as a backend, we chose to first build a front-end API, where a developer can write a front-end wrapper for a fuzzer backend. This orchestrates the running fuzzer process, and performs compile-time instrumentation, pre- and post-processing, and seed synchronization. It also simplifies the fuzzing environment setup by unifying how we can construct tools while implementing functionality.
The snippet below shows an example of a front-end wrapper for AFL. It inherits from a base DeepStateFrontend class and includes methods that define fuzzer-related functionality.
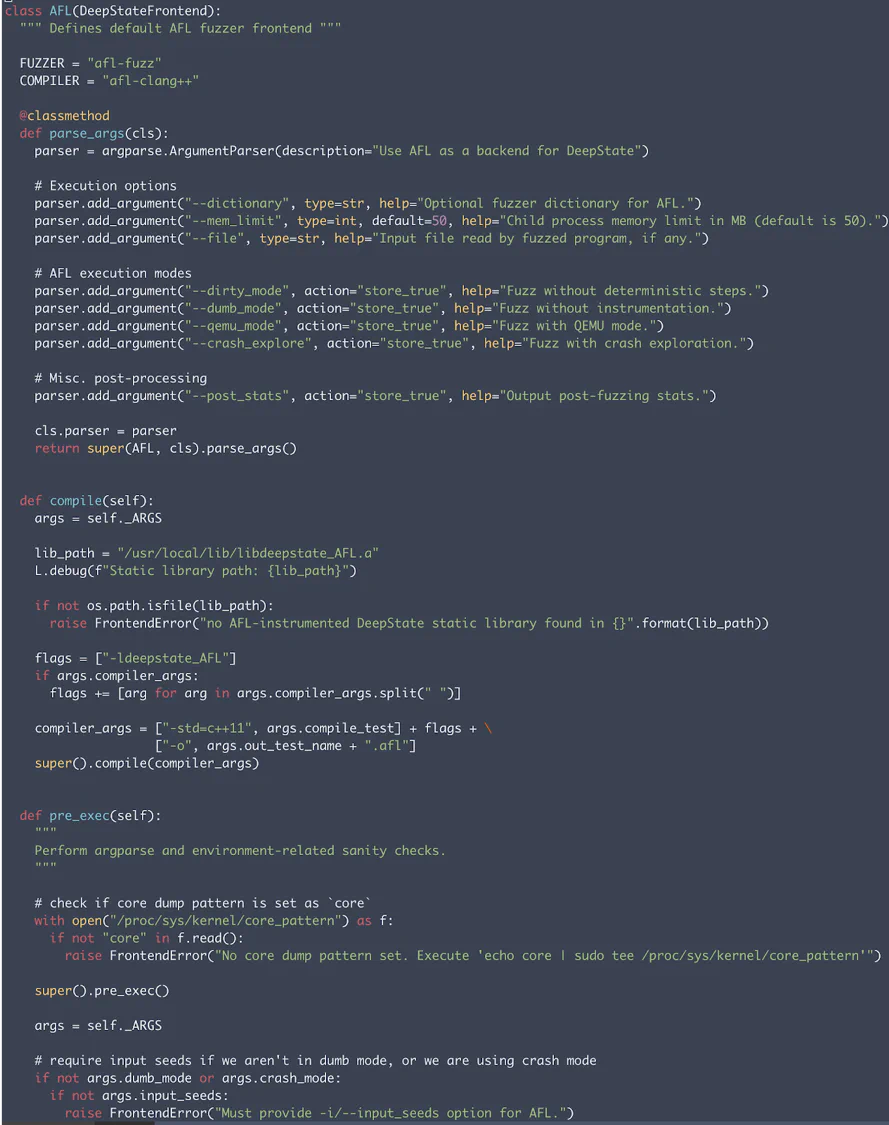
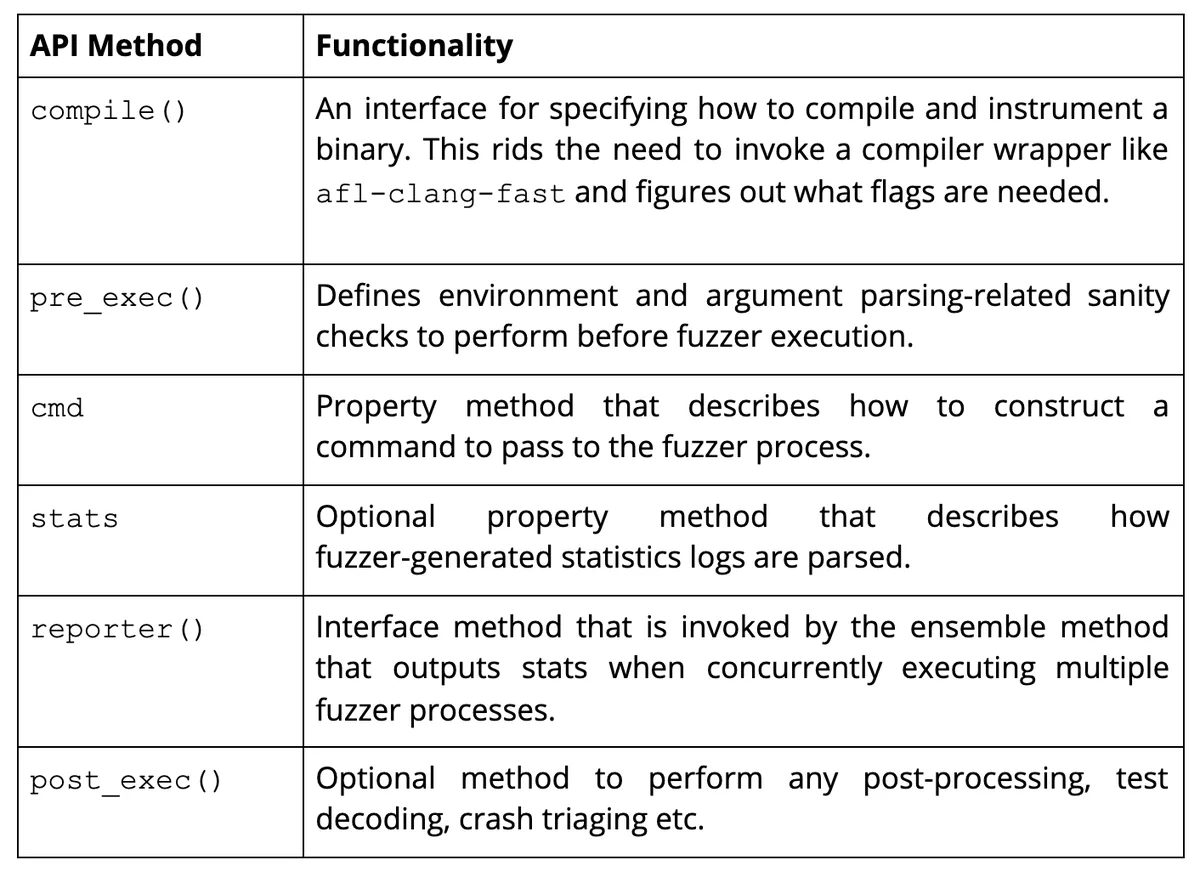
In order to build a front-end wrapper, we should have the following methods in our fuzzer object:
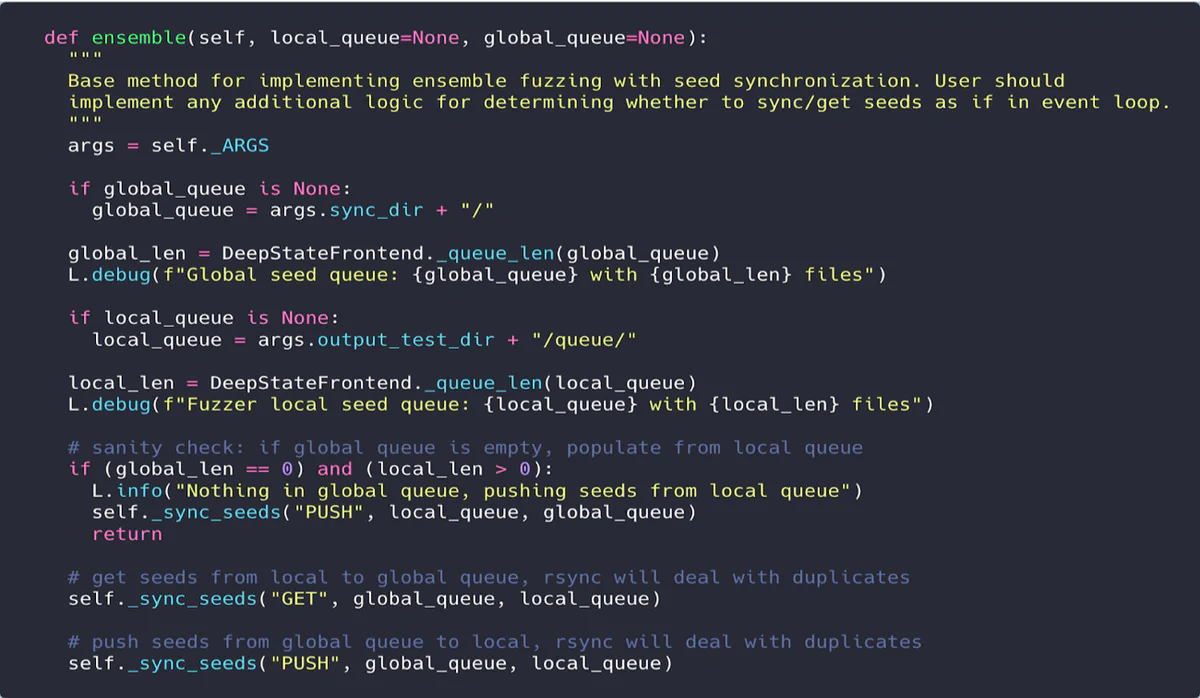
Each fuzzer has its own ensemble method, which provides a specialized rsync call to push and pull seeds from a global and local queue directory:
Once built, we can use a front-end wrapper as so:
# compile a DeepState harness with AFL instrumentation
$ deepstate-afl --compile_test MyDeepStateHarness.cpp --compiler_args=”-Isomelib/include -lsomelib -lotherlib”
# execute the AFL fuzzer through DeepState
$ deepstate-afl -i seeds -o out ./out.aflFor a more detailed look into the fuzzer front-end API and how you can implement your own frontends, see this tutorial. DeepState has existing front-end executors for AFL, libFuzzer, Angora, Eclipser, and Honggfuzz.
https://asciinema.org/a/262023
Building the Ensembler
Using the unified API, we can now build an ensemble fuzzer that provisions front-end objects and executes fuzzers concurrently while maintaining seed synchronization.
To start, take a DeepState test harness input, and “ensemble compile” multiple instrumented binaries to a workspace directory with our fuzzers through the exposed compile() call from each frontend object.
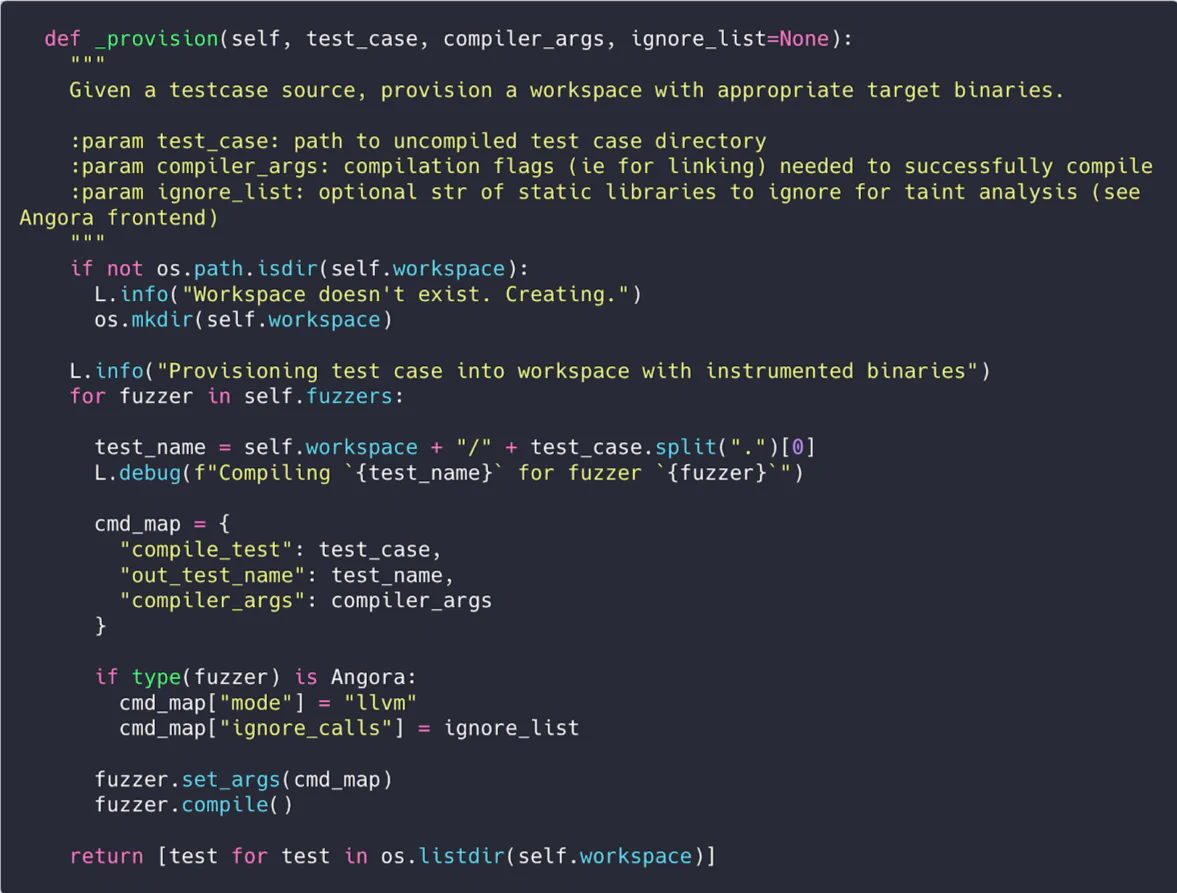
Once complete, each parallel fuzzer process is instantiated through run(). Since each front-end wrapper invokes rsync-style synchronization through ensemble(), the ensembler simply calls it from each front-end after a specified sync cycle (in seconds) to synchronize seeds.
This implementation is surprisingly simple, and was built with around 300 lines of code in Python. Here’s a quick demo running the ensembler on one of our test examples, Crash.cpp.
Fuzz ‘Em All
Inspired by Google’s fuzzer-test-suite and the aforementioned work in fuzzer-performance testing, we decided that a DeepState-powered test suite, deepstate-test-suite, could help fuzzer performance A/B tests and actual bug-hunting. With our easy-to-use fuzzers and ensembler, let’s evaluate how they stand against real-world test-case benchmarks!
Bignum vulnerabilities are an especially interesting class of bugs because edge cases are much more difficult, and even probabilistic, to discover. This makes them ideal targets for DeepState property tests.
We benchmarked our base and ensembler fuzzers for their performance reproducing an existing test case and a real-world bignum vulnerability—a carry mis-propagation bug in TweetNaCl. Following the evaluation methods in this fuzzing evaluation paper, the average time was measured for each test case using 10 crash instances from well-formed initial inputs:
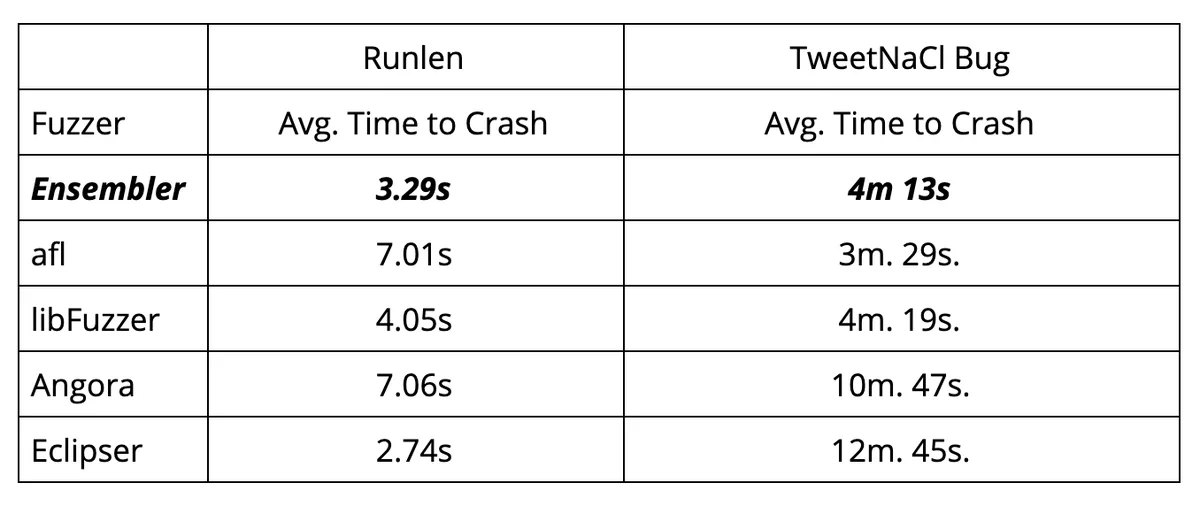
These results provide some interesting insights about fuzzer diversity. Running smarter fuzzers like Angora and Eclipser on smaller contained test cases, like the Runlen example, work well. However, their performance falters when scaled up to the context of actual bug discovery in real-world software, like the TweetNaCl bug. The ensemble fuzzer’s performance shows it can scale up well for both of these test cases.
What’s in the future for Ensemble Fuzzing?
Ensemble fuzzing is a powerful technique that scales to real-world software libraries and programs. Integrating an ensemble fuzzer into DeepState gives power to unit-testing with a simplified workflow, and it opens up the possibility for many other research and engineering efforts.
Based on our current benchmark results, we can’t definitely say that ensemble fuzzing is the best fuzzing strategy, but it’s worth noting that there are always elements of randomness and probabilistic behavior when evaluating fuzzers. Effective ensemble fuzzing may be dependent on base fuzzer selection—determining which fuzzers to invoke and when based on the type of target or bug class being analyzed.
Maybe our current ensemble of fuzzers works effectively on reproducing bignum vulnerabilities, but would they work just as well on other classes of bugs? Would it be even more effective if we invoke fuzzers in a specific order? These are the questions we can answer more accurately with more benchmark tests on diverse targets.
Thanks
Being a security engineering intern at Trail of Bits has been a wonderful experience, as always. Working with awesome employees and interns has really propelled my understandings in security research and how we can turn insightful academic research into working software implementations, just like my previous work with analyzing cryptographic primitives with Manticore. I’m especially excited to continue to do this at NYU, where I’ll be starting in the spring!