
Leaves of Hash
Trail of Bits has released Indurative, a cryptographic library that enables authentication of a wide variety of data structures without requiring users to write much code. Indurative is useful for everything from data integrity to trustless distributed systems. For instance, developers can use Indurative to add Binary Transparency to a package manager — so users can verify the authenticity of downloaded binaries — in only eight lines of code.
Under the hood, Indurative uses Haskell’s new DerivingVia language extension to automatically map types that instantiate FoldableWithIndex to sparse Merkle tree representations, then uses those representations to create and verify inclusion (or exclusion) proofs. If you understood what that means, kudos, you can download Indurative and get started. If not, then you’re in luck! The whole rest of this blog post is written for you.
“That looks like a tree, let’s call it a tree”
In 1979, Ralph Merkle filed a patent for a hash-based signature scheme. This patent introduced several novel ideas, perhaps most notably that of an “authentication tree,” or, as it’s now known, a Merkle tree. This data structure is now almost certainly Merkle’s most famous work, even if it was almost incidental to the patent in which it was published, as it vastly improves efficiency for an incredible variety of cryptographic problems.
Hash-based signatures require a “commitment scheme” in which one party sends a commitment to a future message such that i) there is exactly one message they can send that satisfies the commitment, ii) given a message, it is easy to check if it satisfies the commitment, and iii) the commitment doesn’t give away the message’s contents. Commitment schemes are used everywhere from twitter to multi-party computation.
Typically, a commitment is just a hash (or “digest”) of the message. Anyone can hash a message and see if it’s equal to the commitment. Finding a different message with the same hash is a big deal. That didn’t quite work for Merkle’s scheme though: he wanted to commit to a whole set of different messages, then give an inclusion proof that a message was in the set without revealing the whole thing. To do that, he came up with this data structure:
{kind=link}
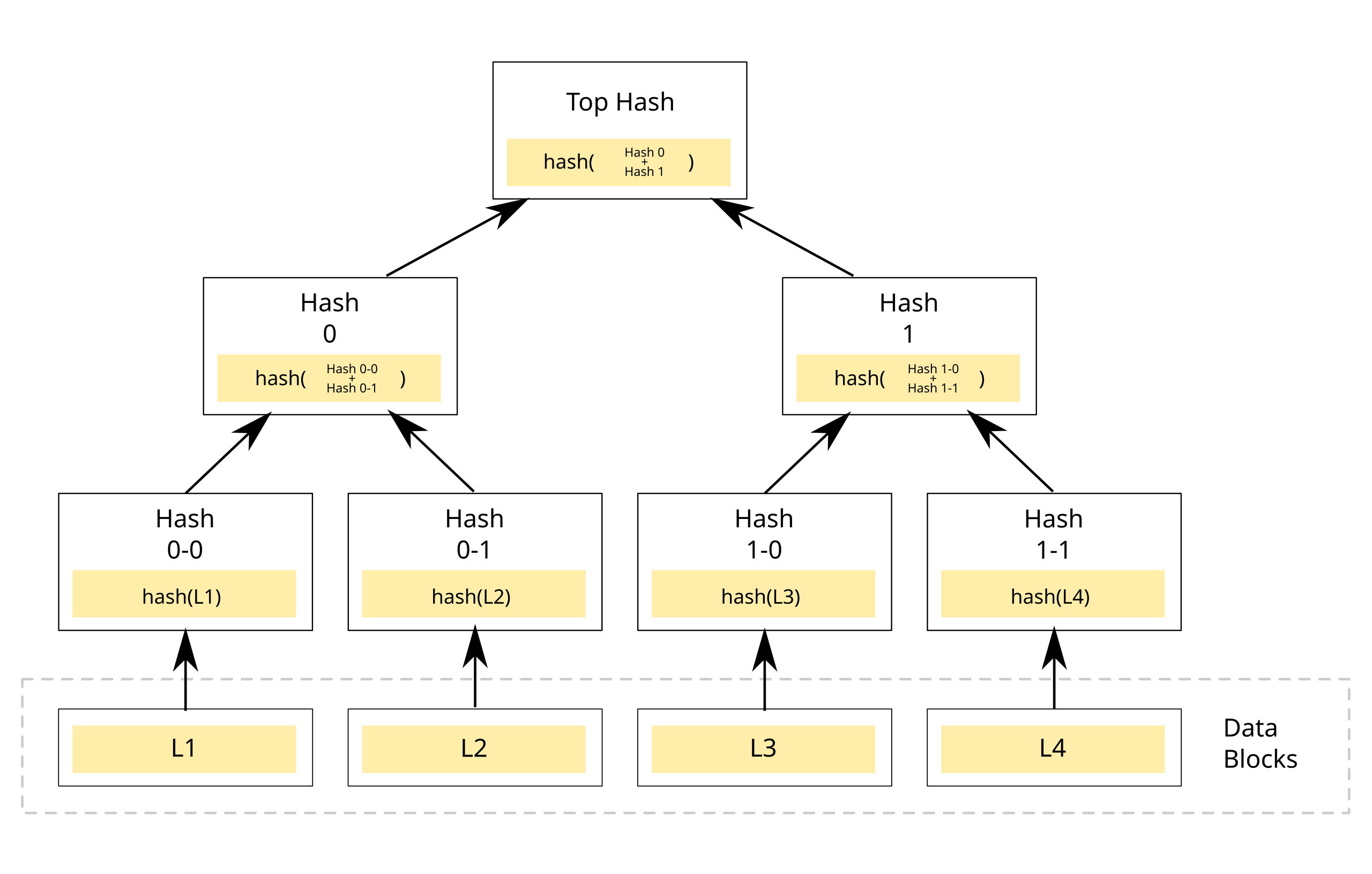
Think of a binary tree where each node has an associated hash. The leaves are each associated with the hash of a message in the set. Each branch is associated with the hash of its childrens’ hashes, concatenated. In this scheme, we can then just publish the top hash as a commitment. To prove some message is included in the set, we start at the leaf associated with its hash and walk up the tree. Every time we walk up to a branch, we keep track of the side we entered from and the hash associated with the node on the other side of that branch. We can then check proofs by redoing the concatenation and hashing at each step, and making sure the result is equal to our earlier commitment.
This is a lot easier to understand by example. In the image above, to prove L3’s inclusion, our proof consists of [(Left, Hash 1-1), (Right, Hash 0)] because we enter Hash 1 from the left, with Hash 1-1 on the other side, then Top Hash from the right, with Hash 0 on the other side. To check this proof, we evaluate hash(Hash 0 + hash(hash(L3) + Hash 1-1)). If this is equal to Top Hash, the proof checks! Forging these proofs is, at each step, as hard as finding a hash collision, and proof size is logarithmic in message set size.
This has all kinds of applications. Tahoe-LAFS, Git, and ZFS (see: Wikipedia) all use it for ensuring data integrity. It appears in decentralization applications from IPFS to Bitcoin to Ethereum (see again: Wikipedia). Lastly, it makes certificate transparency possible (more on that later). The ability to authenticate a data structure turns out to solve all kinds of hard computer science problems.
“You meet your metaphor, and it’s good”
Of course, a Merkle tree is not the only authenticated data structure possible. It’s not hard to imagine generalizing the approach above to trees of arbitrary branch width, and even trees with optional components. We can construct authenticated versions of pretty much any DAG-like data structure, or just map elements of the structure onto a Merkle tree.
In fact, as Miller et al. found in 2014, we can construct a programming language where all data types are authenticated. In Authenticated Data Structures, Generically the authors create a fork of the OCaml compiler to do exactly that, and prove it to be both sound and performant. The mechanics for doing so are fascinating, but beyond the scope of this post. I highly recommend reading the paper.
One interesting thing to note in Miller et al.’s paper is that they re-contextualize the motivation for authenticated data structures. Earlier in this post, we talked about Merkle trees as useful for commitment schemes and data integrity guarantees, but Miller et al. instead chooses to frame them as useful for delegation of data. Specifically, the paper defines an authenticated data structure as one “whose operations can be carried out by an untrusted prover, the results of which a verifier can efficiently check as authentic.”
If we take a moment to think, we can see that this is indeed true. If I have a Merkle tree with millions of elements in it, I can hand it over to a third party, retaining only the top hash, then make queries to this data expecting both a value and an inclusion proof. As long as the proof checks, I know that my data hasn’t been tampered with. In the context of trustless distributed systems, this is significant (we’ll come back to exactly why later, I promise).
In fact, I can authenticate not just reads, but writes! When I evaluate an inclusion proof, the result is a hash that I check against the digest I have saved. If I request the value at some index in the tree, save the proof, then request to write to that same index, by evaluating the old proof with the value I’m writing, I can learn what the digest will be after the write has taken place. Once again, an example may be helpful.
Recall our earlier (diagrammed) example, where to prove L3’s inclusion, our proof consists of [(Left, Hash 1-1), (Right, Hash 0)]. If we want to write a new value, we first retrieve L3 and the associated proof. Then, just as we checked our proof by calculating hash(Hash 0 + hash(hash(L3) + Hash 1-1)) and ensured it was equal to the root hash, we calculate hash(Hash 0 + hash(hash(new_L3) + Hash 1-1)) and update our saved digest to the result. If this isn’t intuitive, looking back at the diagram can be really helpful.
The combination of authenticated reads and writes allow for some very powerful new constructions. Specifically, by adding authentication “checkpoints” to a program in Miller et al.’s new language judiciously, we can cryptographically ensure that a client and server always agree on program state, even if the client doesn’t retain any of the data a program operates on! This is game-changing for systems that distribute computation to semi-trusted nodes (yes, like blockchains).
This sounds like a wild guarantee with all manner of caveats, but it’s much less exciting than that. Programs ultimately run on overcomplicated Turing machines. Program state is just what’s written to the tape. Once you’ve accepted that all reads and writes can be authenticated for whatever data structure you’d like, the rest is trivial. Much of Miller et al.’s contribution is ultimately just nicer semantics!
“We love the things we love for what they are”
So far, we’ve achieved some fairly fantastical results. We can write code as usual, and cryptographically ensure client and server states are synchronized without one of them even having the data operated upon. This is a powerful idea, and it’s hard not to read it and seek to expand on it or apply it to new domains. Consequently, there have been some extremely impressive developments in the field of authenticated data structures even since 2014.
One work I find particularly notable is Authenticated Data Structures, as a Library, for Free! by Bob Atkins, written in 2016. Atkins builds upon Miller et al.’s work so that it no longer requires a custom compiler, a huge step towards practical adoption. It does require that developers provide an explicit serialization for their data type, as well as a custom retrieval function. It now works with real production code in OCaml relatively seamlessly.
There is still, however, the problem of indexing. Up until now we’ve been describing our access in terms of Merkle tree leaves. This works pretty well for data structures like an array, but it’s much harder to figure out how to authenticate something like a hashmap. Mapping the keys to leaves is trivial, but how do you verify that there was a defined value for a given key in the first place?
Consider a simple hashmap from strings to integers. If the custodian of the authenticated hashmap claims that some key “hello” has no defined value, how do we verify that? The delegator could keep a list of all keys and authenticate that, but that’s ugly and inelegant, and effectively grows our digest size linearly with dataset size. Ideally, we’d still like to save only one hash, and synchronizing this key list between client and server is fertile breeding ground for bugs.
Fortunately, Ben Laurie and Emilia Kasper of Google developed a novel solution for this in 2016. Their work is part of Trillian, the library that enables certificate transparency in Chrome. In Revocation Transparency, they introduce the notion of a sparse Merkle tree, a Merkle tree of infeasible size (in their example, depth 256, so a node per thousand atoms in the universe) where we exploit the fact that almost all leaves in this tree have the same value to compute proofs and digests in efficient time.
I won’t go too far into the technical details, but essentially, with 2^256 leaves, each leaf can be assigned a 256-bit index. That means that given some set of key/value data, we can hash each key (yielding a 256-bit digest) and get a unique index into the tree. We associate the hash of the value with that leaf, and have a special null hash for leaves not associated with any value. There’s another diagram below I found very helpful:
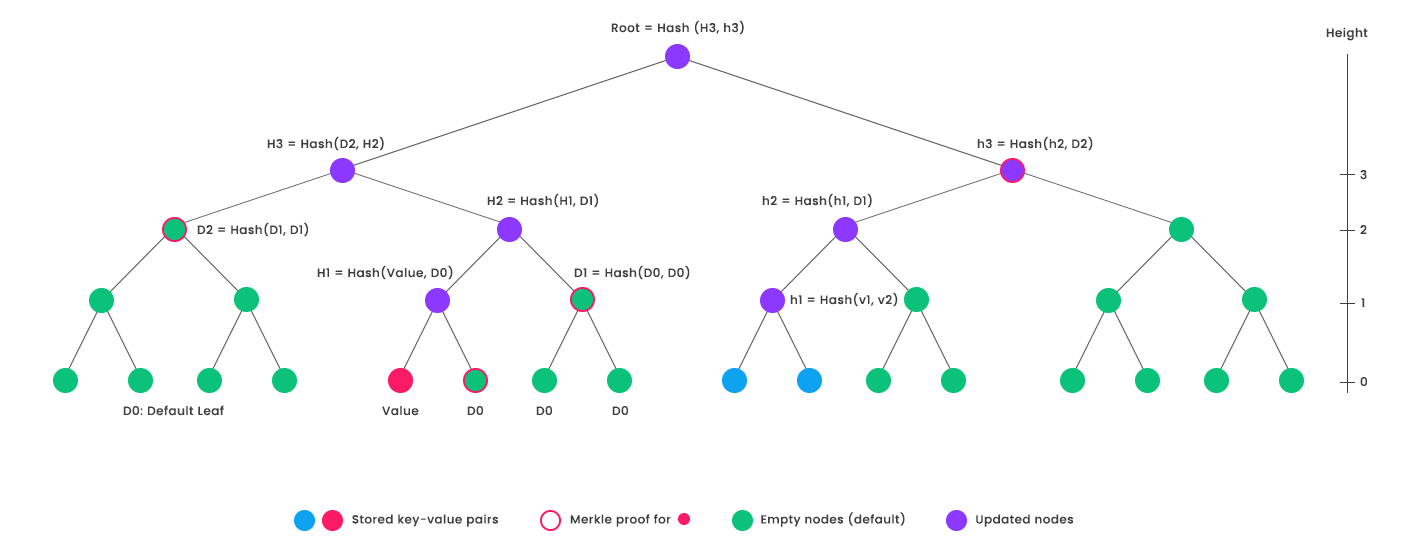
Now we know the hash of every layer-two branch that isn’t directly above one of our defined nodes as well, since it’s just hash(hash(null) + hash(null)). Extending this further, for a given computation we only need to keep track of nodes above at least one of our defined nodes, every other value can be calculated quickly on-demand. Calculating a digest, generating a proof, and checking a proof are all logarithmic in the size of our dataset. Also, we can verify that a key has no associated value by simply returning a retrieval proof valid for a null hash.
Sparse Merkle trees, while relatively young, have already seen serious interest from industry. Obviously, they are behind Revocation Transparency, but they’re also being considered for Ethereum and Loom. There are more than a few libraries (Trillian being the most notable) that just implement a sparse Merkle tree data store. Building tooling on top of them isn’t particularly hard (check out this cool example).
“Give me a land of boughs in leaf”
As exciting as all these developments are, one might still wish for a “best of all worlds” solution: authenticated semantics for data structures as easy to use as Miller et al.’s, implemented as a lightweight library like Atkins’s, and with the support for natural indexing and exclusion proofs of Laurie and Kasper’s. That’s exactly what Indurative implements.
Indurative uses a new GHC feature called DerivingVia that landed in GHC 8.6 last summer. DerivingVia is designed to allow for instantiating polymorphic functions without either bug-prone handwritten instances or hacky, unsound templating and quasiquotes. It uses Haskell’s newtype system so that library authors can write one general instance which developers can automatically specialize to their type.
DerivingVia means that Indurative can offer authenticated semantics for essentially any indexed type that can be iterated through with binary-serializable keys and values. Indurative works out-of-the-box on containers from the standard library, containers and unordered-containers. It can derive these semantics for any container meeting these constraints, with any hash function (and tree depth), and any serializable keys and values, without the user writing a line of code.
Earlier we briefly discussed the example of adding binary transparency to a package-management server in less than ten lines of code. If developers don’t have to maintain parallel states between the data structures they already work with and their Merkle tree authenticated store, we hope that they can focus on shipping features without giving up cryptographic authenticity guarantees.
Indurative is still alpha software. It’s not very fast yet (it can be made waaaay faster), it may have bugs, and it uses kind of sketchy Haskell (UndecidableInstances, but I think we do so soundly). It’s also new and untested cryptographic software, so you might not want to rely on it for production use just yet. But, we’ve worked hard on commenting all the code and writing tests because we think that even if it isn’t mature, it’s really interesting. Please try it, let us know how it works, and let us know what you want to see.
If you have hard cryptographic engineering problems, and you think something like Indurative might be the solution, drop us a line.