
Codex (and GPT-4) can’t beat humans on smart contract audits
Is artificial intelligence (AI) capable of powering software security audits? Over the last four months, we piloted a project called Toucan to find out. Toucan was intended to integrate OpenAI’s Codex into our Solidity auditing workflow. This experiment went far beyond writing “where is the bug?” in a prompt and expecting sound and complete results.
Our multi-functional team, consisting of auditors, developers, and machine learning (ML) experts, put serious work into prompt engineering and developed a custom prompting framework that worked around some frustrations and limitations of current large language model (LLM) tooling, such as working with incorrect and inconsistent results, handling rate limits, and creating complex, templated chains of prompts. At every step, we evaluated how effective Toucan was and whether it would make our auditors more productive or slow them down with false positives.
The technology is not yet ready for security audits for three main reasons:
- The models are not able to reason well about certain higher-level concepts, such as ownership of contracts, re-entrancy, and fee distribution.
- The software ecosystem around integrating large language models with traditional software is too crude and everything is cumbersome; there are virtually no developer-oriented tools, libraries, and type systems that work with uncertainty.
- There is a lack of development and debugging tools for prompt creation. To develop the libraries, language features, and tooling that will integrate core LLM technologies with traditional software, far more resources will be required.
Whoever successfully creates an LLM integration experience that developers love will create an incredible moat for their platform.
The above criticism still applies to GPT-4. Although it was released only a few days before the publication of this blog post, we quickly ran some of our experiments against GPT-4 (manually, via the ChatGPT interface). We conclude that GPT-4 presents an incremental improvement at analyzing Solidity code. While GPT-4 is considerably better than GPT-3.5 (ChatGPT) at analyzing Solidity, it is still missing key features, such as the ability to reason about cross-function reentrancy and inter-function relationships in general. There are also some capability regressions from Codex, like identification of variables, arithmetic expressions, and understanding of integer overflow. It is possible that with the proper prompting and context, GPT-4 could finally reason about these concepts. We look forward to experimenting more when API access to the large context GPT-4 model is released.
We are still excited at the prospect of what Codex and similar LLMs can provide: analysis capabilities that can be bootstrapped with relatively little effort. Although it does not match the fidelity of good algorithmic tools, for situations where no code analysis tools exist, something imperfect may be much better than having nothing.
Toucan was one of our first experiments with using LLMs for software security. We will continue to research AI-based tooling, integrating it into our workflow where appropriate, like auto-generating documentation for smart contracts under audit. AI-based capabilities are constantly improving, and we are eager to try newer, more capable technologies.
We want AI tools, too
Since we like to examine transformational and disruptive technologies, we evaluated OpenAI’s Codex for some internal analysis and transformation tasks and were very impressed with its abilities. For example, a recent intern integrated Codex within Ghidra to use it as a decompiler. This inspired us to see whether Codex could be applied to auditing Solidity smart contracts, given our expertise in tool development and smart contract assessments.
Auditing blockchain code is an acquired skill that takes time to develop (which is why we offer apprenticeships). A good auditor must synthesize multiple insights from different domains, including finance, languages, virtual machine internals, nuances about ABIs, commonly used libraries, and complex interactions with things like pricing oracles. They must also work within realistic time constraints, so efficiency is key.
We wanted Toucan to make human auditors better by increasing the amount of code they could investigate and the depth of the analysis they could accomplish. We were particularly excited because there was a chance that AI-based tools would be fundamentally better than traditional algorithmic-based tooling: it is possible to learn undecidable problems to an arbitrarily high accuracy, and program analysis bumps against undecidability all the time.
We initially wanted to see if Codex could analyze code for higher-level problems that could not be examined via static analysis. Unfortunately, Codex did not provide satisfactory results because it could not reason about higher-level concepts, even though it could explain and describe them in words.
We then pivoted to a different problem: could we use Codex to reduce the false positive rate from static analysis tools? After all, LLMs operate fundamentally different from our existing tools. Perhaps they provide enough signals to create new analyses previously untenable due to unacceptable false positives. Again, the answer was negative, as the number of failures was high even in average-sized code, and those failures were difficult to predict and characterize.
Below we’ll discuss what we actually built and how we went about assessing Toucan’s capabilities.
Was this worth our time?
Our assessment does not meet the rigors of scientific research and should not be taken as such. We attempted to be empirical and data-driven in our evaluation, but our goal was to decide whether Toucan warranted further development effort—not scientific publication.
At each point of Toucan development, we tried to assess whether we were on the right track. Before starting development, we manually used Codex to identify vulnerabilities that humans had found in specific open-source contracts—and with enough prompt engineering, Codex could.
After we had the capability to try small examples, we focused on three main concepts that seemed within Codex’s capability to understand: ownership, re-entrancy, and integer overflow. (A quick note for the astute reader: Solidity 0.8 fixed most integer overflow issues; developing overflow checks was an exercise in evaluating Codex’s capability against past code.) We could, fairly successfully, identify vulnerabilities regarding these concepts in small, purpose-made examples.
Finally, as we created enough tooling to automate asking questions against multiple larger contracts, we began to see the false positive and hallucination rates become too high. Although we had some success with ever more complex prompts, it was still not enough to make Toucan viable.
Below are some key takeaways from our experience.
Codex does not fully grasp the higher-level concepts that we would like to ask about, and explaining them via complex prompt engineering does not always work or produce reliable results. We had originally intended to ask questions about higher-level concepts like ownership, re-entrancy, fee distribution, how pricing oracles are used, or even automated market makers (AMMs). Codex does not fully understand many of these abstract concepts, and asking about them failed in the initial evaluation stage. It somewhat comprehends the simplest concept — ownership — but even then it often cannot always correlate changes in the ‘owner’ variable with the concept of ownership. Codex does not appear to grasp re-entrancy attacks as a concept, even though it can describe them with natural language sentences.
It is very easy to delude yourself by p-hacking a prompt that works for one or a few examples. It is extremely difficult to get a prompt that generalizes very well across multiple, diverse inputs. For example, when testing whether Toucan could reason about ownership, we initially tried seven small (<50 LOC) examples from which we could determine a baseline. After a thorough prompt-engineering effort, Toucan could pass six out of seven tests, with the lone failing test requiring complex logic to induce ownership change. We then tried the same prompt on eight larger programs (> 300 LOC), among which Toucan identified 15 potential changes of ownership, with four false positives—including complete hallucinations. However, when we tried slight permutations of the original small tests, we could usually get the prompt to fail given relatively minor changes in input. Similarly, for integer overflow tests, we could get Toucan to successfully identify overflows in 10 out of 11 small examples, with one false positive—but a larger set of five contracts produced 12 positives — with six of them being false, including four instances of complete hallucinations or inability to follow directions.
Codex can be easily misled by small changes in syntax. Codex is not as precise as existing static analysis tools. It is easily confused by up comments, variable names, and small syntax changes. A particular thorn is reasoning about conditionals (e.g. ==, !=, <, >), where Codex will seemingly ignore them and create a conclusion based on function and variable names instead.
Codex excels at abstract tasks that are difficult to define algorithmically, especially if errors in the output are acceptable. For example, Codex will excel at queries like “Which functions in this contract manipulate global state?” without having to define “global state” or “manipulate.” The results might not be exact, but they will often be good enough to experiment with new analysis ideas. And while it is possible to define queries like this algorithmically, it is infinitely easier to ask in plain language.
The failure modes of Codex are not obvious to predict, but they are different from those of Slither and likely similar static analysis tools based on traditional algorithms.
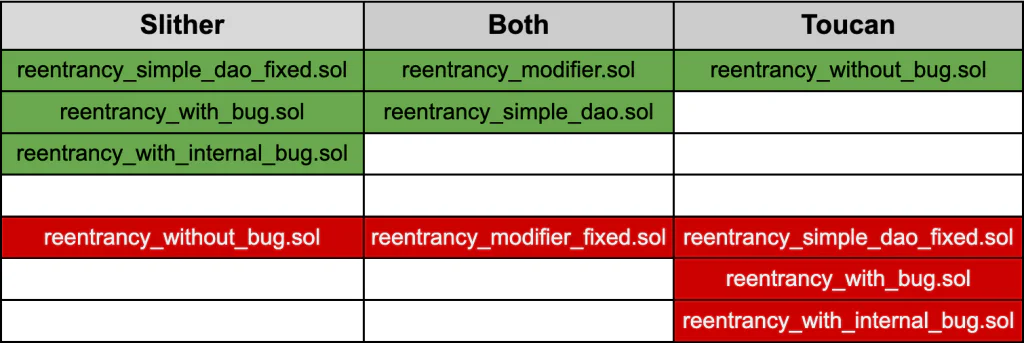
We tried looking at the true/false positive sets of Slither and Toucan, and found that each tool had a different set of false positives/false negatives, with some overlap (Figure 1). Codex was not able to effectively reduce the false positive rate from a prototype Slither integer overflow detector. Overall, we noticed a tendency to reply affirmatively to our questions, increasing the number of positives discovered by Toucan.
Codex can perform basic static analysis tasks, but the rate of failure is too high to be useful and too difficult to characterize. This capability to perform successful analysis, even on short program fragments, is very impressive and should not be discounted! For languages that Codex understands but for which no suitable tooling exists, this capability could be extremely valuable—after all, some analysis could be much better than nothing. But the benchmark for Solidity is not nothing; we already have existing static analysis tooling that works very well.
How we framed our framework
During Toucan’s development, we created a custom prompting framework, a web-based front end, and rudimentary debugging and testing tools to evaluate prompts and to aid in unit and integration tests. The most important of these was the prompting framework.
Prompting framework
If we were making Toucan today, we’d probably just use LangChain. But at the time, LangChain did not have the features we needed. Frustratingly, neither OpenAI nor Microsoft offered an official, first-party prompting framework. This led us to develop a custom framework, with the goal that it should be possible for auditors to create new prompts without ever modifying Toucan’s code.
requires = ["emit-ownership-doc", "emit-target-contract"]
name = "Contract Ownership"
scope = "contract"
instantiation_condition = "any('admin' in s.name.lower() or 'owner' in s.name.lower() for s in contract.state_variables)"
[[questions]]
name = "can-change"
query = "Is it possible to change the `{{ contract | owner_variable }}` variable by calling a function in the `{{ contract.name }}` contract without aborting the transaction? Think through it step by step, and answer as 'Yes', 'No', or 'Unknown'. If 'Yes', please specify the function."
is_decision = true
[[questions]]
name = "who-can-call"
runtime_condition = "questions['can-change'].is_affirmative()"
query = """To reason about ownership:
1) First, carefully consider the code of the function
2) Second, reason step by step about the question.
Who can call the function successfully, that is, without aborting or revering the transaction?"""
answer_start = """1) First, carefully consider the code of the function:"""
[[questions]]
name = "can-non-owner-call"
runtime_condition = "questions['can-change'].is_affirmative()"
query = "Can any sender who is not the current owner call the function without reverting or aborting?"
is_decision = true
finding_condition = "question.is_affirmative()"Our framework supported chaining multiple questions together to support Chain of Thought and similar prompting techniques (Figure 2). Since GPT models like Codex are multi-shot learners, our framework also supported adding background information and examples before forming a prompt.
The framework also supported filtering on a per-question basis, as there may also be some questions relevant only to specific kinds of contracts (say, only ERC-20 tokens), and others questions may have a specific scope (e.g., a contract, function, or file scope). Finally, each question could be optionally routed to a different model.
The prompting framework also took great lengths to abide by OpenAI’s API limitations, including batching questions into one API invocation and keeping track of both the token count and API invocation rate limits. We hit these limits often and were very thankful the Codex model was free while in beta.
Test data
One of our development goals was that we would never compromise customer data by sending it to an OpenAI API endpoint. We had a strict policy of running Toucan only against open-source projects on GitHub (which would already have been indexed by Codex) with published reports, like those on our Publications page).
We were also able to use the rather extensive test set that comes with Slither, and our “building secure contracts” reference materials as additional test data. It is important to note that some of these tests and reference materials may have been a part of the Codex training set, which explains why we saw very good results on smaller test cases.
The missing tools
The lack of tooling from both OpenAI and Microsoft has been extremely disappointing, although that looks to be changing: Microsoft has a prompting library, and OpenAI recently released OpenAI Evals. The kinds of tools we’d have loved to see include a prompt debugger; a tree-graph visualization of tokens in prompts and responses with logprobs of each token; tools for testing prompts against massive data sets to evaluate quality; ways to ask the same question and combine results from counterexamples; and some plugins to common unit testing frameworks. Surely someone is thinking of the developers and making these tools?
Current programming languages lack the facilities for interfacing with neural architecture computers like LLMs or similar models. A core issue is the lack of capability to work with nondeterminism and uncertainty. When using LLMs, every answer has some built-in uncertainty: the outputs are inherently probabilistic, not discrete quantities. This uncertainty should be handled at the type system level so that one does not have to explicitly deal with probabilities until it is necessary. A pioneering project from Microsoft Research called Infer.NET does this for .NET-based languages, but there seem to be few concrete examples and no real tooling to combine this with LLMs.
Prompt engineering, and surrounding tooling, are still in their infancy. The biggest problem is that you never know when you are done: even now, it is always possible that we were just one or two prompts away from making Toucan a success. But at some point, you have to give up in the face of costs and schedules. With this in mind, the $300K salary for a fantastic prompt engineer does not seem absurd: if the only difference between a successful LLM deployment and a failure is a few prompts, the job quickly pays for itself. Fundamentally, though, this reflects a lack of tooling to assess prompt quality and evaluate responses.
There is no particularly good way to determine if one prompt is better than another or if you’re on the right track. Similarly, when a prompt fails against an input, it is frustratingly difficult to figure out why and to determine, programmatically, which prompts are merely returning the wrong result versus completely hallucinating and misbehaving.
Unit tests are also problematic; the results are not guaranteed to be the same across runs, and newer models may not provide the same results as prior ones. There is certainly a solution here, but again, the tooling developers expect just wasn’t present. OpenAI Evals is likely going to improve this situation.
Overall, the tooling ecosystem is lacking, and surprisingly, the biggest names in the field have not released anything substantial to improve the adoption and integration of LLMs into real software projects that people use. However, we are excited that the open source community is stepping up with really cool projects like LangChain and LlamaIndex.
Humans still reign supreme
OpenAI’s Codex is not yet ready to take over the job of software security auditors. It lacks the ability to reason about the proper concepts and produces too many false positives for practical usage in audit tasks. However, there is clearly a nascent capability to perform interesting analysis tasks, and underlying models should quickly get more capable. We are very excited to keep using the technology as it improves. For example, the new larger context window with GPT-4 may allow us to provide enough context and direction to handle complex tasks.
Even though Codex (and GPT-4) do not currently match mature algorithmic-based tools, LLM-based tools—even those of lower quality—may have interesting uses. For languages for which no analysis tooling exists, developers can bootstrap something from LLMs relatively quickly. The ability to provide some reasonable analysis where none previously existed may be considerably better than nothing at all.
We hope the ability to integrate language models into existing programs improves quickly, as there is currently a severe lack of languages, libraries, type systems, and other tooling for the integration of LLMs into traditional software. Disappointingly, the main organizations releasing LLMs have not released much tooling to enable their use. Thankfully, open-source projects are filling the gap. There is still enormous work to be done, and whoever can make a wonderful developer experience working with LLMs stands to capture developer mindshare.
LLM capability is rapidly improving, and if it continues, the next generation of LLMs may serve as capable assistants to security auditors. Before developing Toucan, we used Codex to take an internal blockchain assessment occasionally used in hiring. It didn’t pass—but if it were a candidate, we’d ask it to take some time to develop its skills and return in a few months. It did return—we had GPT-4 take the same assessment—and it still didn’t pass, although it did better. Perhaps the large context window version with proper prompting could pass our assessment. We’re very eager to find out!