
PDF is Broken: a justCTF Challenge
Trail of Bits sponsored the recent justCTF competition, and our engineers helped craft several of the challenges, including D0cker, Go-fs, Pinata, Oracles, and 25519. In this post we’re going to cover another of our challenges, titled PDF is broken, and so is this file. It demonstrates some of the PDF file format’s idiosyncrasies in a bit of an unusual steganographic puzzle. CTF challenges that amount to finding a steganographic needle in a haystack are rarely enlightening, let alone enjoyable. LiveOverflow recently had an excellent video on file format tricks and concludes with a similar sentiment. Therefore, we designed this challenge to teach justCTF participants some PDF tricks and how Trail of Bits’ open source tools can make easy work of these forensic challenges.
In which a PDF is a webserver, serving copies of itself
The PDF file in the challenge is in fact broken, but most PDF viewers will usually just render it as a blank page with no complaints. The file command reports the challenge as just being “data.” Opening the file in a hex editor, we see that it looks like a Ruby script:
require "json"
require "cgi"
require "socket"
=begin
%PDF-1.5
%ÐÔÅØ
% <code>file</code> sometimes lies
% and <code>readelf -p .note</code> might be useful laterThe PDF header on line 5 is embedded within a Ruby multi-line comment that begins on line 4, but that’s not the part that’s broken! Almost all PDF viewers will ignore everything before the %PDF-1.5 header. Lines 7 and 8 are PDF comments affirming what we saw from the file command, as well as a readelf hint that we’ll get to later.
The remainder of the Ruby script is embedded within a PDF object stream—the “9999 0 obj” line—, which can contain arbitrary data ignored by PDF. But what of the remainder of the PDF? How does that not affect the Ruby script?
9999 0 obj
<< /Length 1680 >>^Fstream
=end
port = 8080
if ARGV.length > 0 then
port = ARGV[0].to_i
end
html=DATA.read().encode('UTF-8', 'binary', :invalid => :replace, :undef => :replace).split(/<\/html>/)[0]+"\n"
v=TCPServer.new('',port)
print "Server running at http://localhost:#{port}/\nTo listen on a different port, re-run with the desired port as a command-line argument.\n\n"
⋮
__END__Ruby has a feature where the lexer will halt on the __END__ keyword and effectively ignore everything thereafter. Sure enough, this curious PDF has such a symbol, followed by the end of the encapsulating PDF object stream and the remainder of the PDF.
This is a Ruby/PDF polyglot, and you can turn any PDF into such a polyglot using a similar method. If your script is short enough, you don’t even need to embed it in a PDF stream object. You can just prepend all of it before the %PDF-1.5 header. Although some PDF parsers will complain if the header is not found within the first 1024 bytes of the file.
You didn’t think it would be that easy, did you?
So let’s be brave and try running the PDF as if it were a Ruby script. Sure enough, it runs a webserver that serves a webpage with a download link for “flag.zip.” Wow, that was easy, right? Inspect the Ruby script further and you’ll see that the download is the PDF file itself renamed as a .zip. Yes, in addition to being a Ruby script, this PDF is also a valid ZIP file. PoC||GTFO has used this trick for years, which can also be observed by running binwalk -e on the challenge PDF.
Unzipping the PDF produces two files: a MμPDF mutool binary and false_flag.md, the latter suggesting the player run the broken PDF through the mutool binary.
Clearly, this version of mutool was modified to render the broken PDF properly, despite whatever is “broken” about it. Is the CTF player supposed to reverse engineer the binary to figure out what was modified? If someone tried, or if they tried the readelf clue embedded as a PDF comment above, they might notice this:
The first thing you should do is: Open the PDF in a hex editor. You’ll probably need to “fix” the PDF so it can be parsed by a vanilla PDF reader. You could reverse this binary to figure out how to do that, but it’s probably easier to use it to render the PDF, follow the clues, and compare the raw PDF objects to those of a “regular” PDF. You might just be able to repair it with
bbe!
The Binary Block Editor (bbe) is a sed-like utility for editing binary sequences. This implies that whatever is causing the PDF to render as a blank page can easily be fixed with a binary regex.
Deeper Down the Hole
When we use the modified version of mutool to render the PDF, it results in this ostensibly meaningless memetic montage:

Searching Google for the LMGTFY string will take you to Didier Stevens’ excellent article describing the PDF stream format in detail, including how PDF objects are numbered and versioned. One important factor is that two PDF objects can have the same number but different versions.
The first hint on the page identifies PDF object 1337, so that is probably important. The figures in Stevens’ article alone, juxtaposed to a hexdump of the broken PDF’s stream objects, provide a clear depiction of what was changed.

5 0 obj
<< /Length 100 >>^Fstream
⋮
endstream
endobjAs the hints suggest, the PDF specification only allows for six whitespace characters: \0, \t, \n, \f, \r, and space. The version of mutool in the ZIP was modified to also allow ACK (0x06) to be used as a seventh whitespace character! Sure enough, on the twelfth line of the file we see:
>>^FstreamThat “^F” is an ACK character, where the PDF specification says there should be whitespace! All of the PDF object streams are similarly broken. This can be fixed with:
bbe -e "s/\x06stream\n/\nstream\n/" -o challenge_fixed.pdf challenge.pdfSolving the Puzzle
Is fixing the file strictly necessary to solve the challenge? No, the flag may be found in PDF object 0x1337 using a hex editor
4919 0 obj
<< /Length 100 /Filter /FlateDecode >>^Fstream
x<9c>^MËA^N@0^PFá}OñëÆÊÊ <88>X;^Ba<9a>N<8c>N£#áöº~ßs<99>s^ONÅ6^Qd<95>/°<90>^[¤(öHû }^L^V k×E»d<85>fcM<8d>^[køôië<97><88>^N<98> ^G~}Õ\°L3^BßÅ^Z÷^CÛ<85>!Û
endstream
endobj
4919 1 obj
<< /Length 89827 /Filter [/FlateDecode /ASCIIHexDecode /DCTDecode] >>^Fstream
…
endstream
endobjand manually decoding the stream contents. Binwalk will even automatically decode the first stream because it can decode the Flate compression. That contains:
pip3 install polyfile
Also check out the`--html`option!
But you’ll need to “fix” this PDF first!
Binwalk doesn’t automatically expand the second stream because it’s also encoded with the ASCIIHex and DCT PDF filters. A casual observer who had not followed all of the clues and wasn’t yet familiar with the PDF specification might not even realize that the second version of the PDF stream object 0x1337 even existed! And that’s the one with the flag. Sure, it’s possible to have combed through the dozens of files extracted by binwalk to manually decode the flag, or even directly from the stream content in a hex editor, with a quick implementation of PDF’s decoders. But why do that when Polyfile can do it for you?
polyfile challenge_fixed.pdf -html challenge_fixed.html
Oh, hey, that’s a hierarchical representation of the PDF objects, with an interactive hex viewer! How about we go to object 0x1337’s stream?

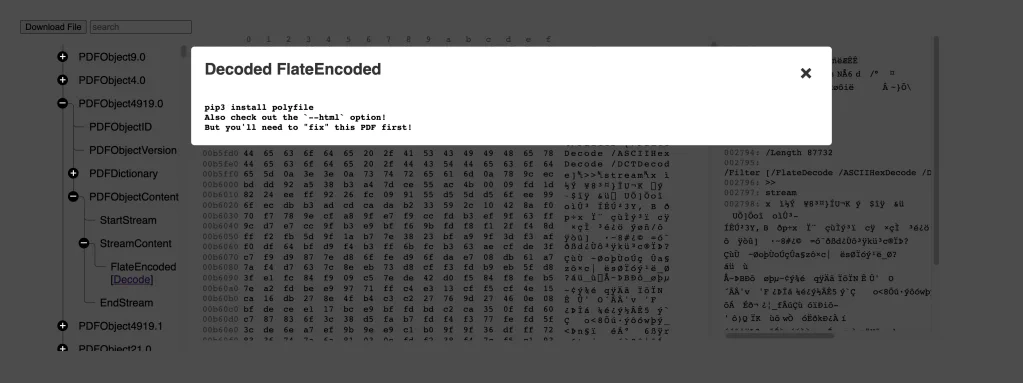
And finally, let’s look at the second version of object 0x1337, containing the multi-encoded flag:


Conclusions
PDF is a very … flexible file format. Just because a PDF looks broken, it doesn’t mean it is. And just because a PDF is broken, it doesn’t mean PDF viewers will tell you it is. PDF is at its core a container format that lets you encode arbitrary binary blobs that don’t even have to contribute to the document’s rendering. And those blobs can be stacked with an arbitrary number of encodings, some of which are bespoke features of PDF. If this is interesting to you, check out our talk on The Treachery of Files, as well as our tools for taming them, such as Polyfile and PolyTracker.