
Breaking the Solidity Compiler with a Fuzzer
Over the last few months, we’ve been fuzzing solc, the standard Solidity smart contract compiler, and we’ve racked up almost 20 (now mostly fixed) new bugs. A few of these are duplicates of existing bugs with slightly different symptoms or triggers, but the vast majority are previously unreported bugs in the compiler.
This has been a very successful fuzzing campaign and, to our knowledge, one of the most successful ever launched against solc. This isn’t the first time solc has been fuzzed with AFL; fuzzing solc via AFL is a long-standing practice. The compiler has even been tested on OSSFuzz since January of 2019. How did we manage to find so many previously undiscovered bugs–and bugs worth fixing fairly quickly, in most cases? Here are five important elements of our campaign.
1. Have a secret sauce
Fortunately, it’s not necessary that the novelty actually be kept secret, just that it be genuinely new and somewhat tasty! Essentially, we used AFL in this fuzzing campaign, but not just any off-the-shelf AFL. Instead, we used a new variant of AFL expressly designed to help developers fuzz language tools for C-like languages without a lot of extra effort.
The changes from standard AFL aren’t particularly large; this fuzzer just adds a number of new AFL havoc mutations that look like those used by a naive, text-based source code mutation testing tool (i.e., universalmutator). The new approach requires less than 500 lines of code to implement, most of it very simple and repetitive.
This variation of AFL is part of a joint research project with Rijnard van Tonder at Sourcegraph, Claire Le Goues at CMU, and John Regehr at the University of Utah. In our preliminary experiments comparing the method to plain old AFL, the results look good for solc and the Tiny C Compiler, tcc. As science, the approach needs further development and validation; we’re working on that. In practice, however, this new approach has almost certainly helped us find many new bugs in solc.
We found a few of the early bugs reported using plain old AFL in experimental comparisons, and some of the bugs we found easily with our new approach we also eventually duplicated using AFL without the new approach—but the majority of the bugs have not been replicated in “normal” AFL. The graph below shows the number of issues we submitted on GitHub, and underscores the significance of the AFL changes:
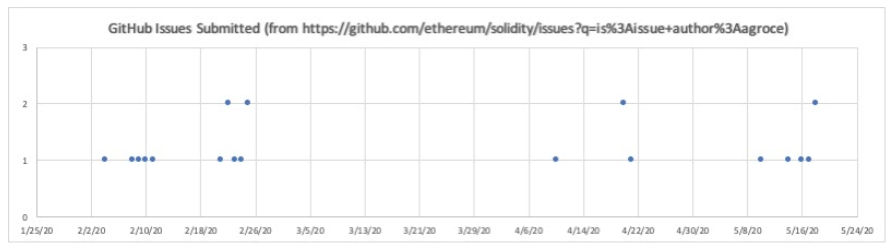
The big jump in bug discovery in late February came immediately after we added a few smarter mutation operations to our version of AFL. It could be coincidence, but we doubt it; we manually inspected the files generated and saw a qualitative change in the AFL fuzzing queue contents. Additionally, the proportion of files AFL generated that were actually compilable Solidity jumped by more than 10%.
2. Build on the work of others
Fuzzing a system that has never been fuzzed can certainly be effective; the system’s “resistance” to the kinds of inputs fuzzers generate is likely to be extremely low. However, there can also be advantages to fuzzing a system that has been fuzzed before. As we noted, we aren’t the first to fuzz solc with AFL. Nor were previous efforts totally freelance ad-hoc work; the compiler team was involved in fuzzing solc, and had built tools we could use to make our job easier.
The Solidity build includes an executable called solfuzzer that takes a Solidity source file as input and compiles it using a wide variety of options (with and without optimization, etc.) looking for various invariant violations and kinds of crashes. Several of the bugs we found don’t exhibit with the normal solc executable unless you use specific command-line options (especially optimization) or run solc in certain other, rather unusual, ways; solfuzzer found all of these. We also learned from the experience of others that a good starting corpus for AFL fuzzing is in the test/libsolidity/syntaxTests directory tree. This was what other people were using, and it definitely covers a lot of the “what you might see in a Solidity source file” ground.
Of course, even with such existing work, you need to know what you’re doing, or at least how to look it up on Google. Nothing out there will tell you that simply compiling solc with AFL won’t actually produce good fuzzing. First, you need to notice that that the fuzzing results in a very high map density, which measures the degree to which you’ve “filled” AFL’s coverage hash. Then you either need to know the advice given in the AFL User Guide, or search for the term “afl map density” and see that you need to recompile the whole system with AFL_INST_RATIO set to 10 to make it easier for the fuzzer to identify new paths. This only happens, according to the AFL docs, when “you’re fuzzing extremely hairy software.” So if you’re used to fuzzing compilers, you probably have seen this before, but otherwise you probably haven’t run into map density problems.
3. Play with the corpus
You may notice that the last spike in submitted bugs comes long after the last commit made to our AFL-compiler-fuzzer repository. Did we make local changes that aren’t yet visible? No, we just changed the corpus we used for fuzzing. In particular, we looked beyond the syntax tests, and added all the Solidity source files we could find under test/libsolidity. The most important thing this accomplished was allowing us to find SMT checker bugs, because it brought in files that used the SMTChecker pragma. Without a corpus example using that pragma, AFL has essentially no chance of exploring SMT Checker behaviors.
The other late-bloom bugs we found (when it seemed impossible to find any new bugs) mostly came from building a “master” corpus including every interesting path produced by every fuzzer run we’d performed up to that point, and then letting the fuzzer explore it for over a month.
4. Be patient
Yes, we said over a month (on two cores). We ran over a billion compilations in order to hit some of the more obscure bugs we found. These bugs were very deep in the derivation tree from the original corpus. Bugs we found in the Vyper compiler similarly required some very long runs to discover. Of course, if your fuzzing effort involves more than just playing around with a new technique, you may want to throw machines (and thus money) at the problem. But according to an important new paper, you may need to throw exponentially more machines at the problem if that’s your only approach.
Moreover, for feedback-based fuzzers, just using more machines may not produce some of the obscure bugs that require a long time to find; there’s not always a shortcut to a bug that requires a mutation of a mutation of a mutation of a mutation…of an original corpus path. Firing off a million “clusterfuzz” instances will produce lots of breadth, but it doesn’t necessarily achieve depth, even if those instances periodically share their novel paths with each other.
5. Do the obvious, necessary things
There’s nothing secret about reducing your bug-triggering source files before submitting them, or trying to follow the actual issue submission guidelines of the project you’re reporting bugs to. And, of course, even if it’s not mentioned in those guidelines, performing a quick search to avoid submitting duplicates is standard. We did those things. They didn’t add much to our bug count, but they certainly sped up the process of recognizing the issues submitted as real bugs and fixing them.
Interestingly, not much reduction was usually required. For the most part, just removing 5-10 lines of code (less than half the file) produced a “good-enough” input. This is partly due to the corpus, and (we think) partly due to our custom mutations tending to keep inputs small, even beyond AFL’s built-in heuristics along those lines.
What did we find?
Some bugs were very simple problems. For instance, this contract used to cause the compiler to bomb out with the message “Unknown exception during compilation: std::bad_cast”:
contract C {
function f() public returns (uint, uint) {
try this() {
} catch Error(string memory) {
}
}
}The issue was easily fixed by changing a typeError into a fatalTypeError, which prevents the compiler from continuing in a bad state. The commit fixing that was only one line of code (though quite a few lines of new tests).
On the other hand, this issue, which prompted a bug bounty award and made it into a list of important bug fixes for the 0.6.8 compiler release, could produce incorrect code for some string literals. It also required substantially more code to handle the needed quoting.
Even the un-reduced versions of our bug-triggering Solidity files look like Solidity source code. This is probably because our mutations, which are heavily favored by AFL, tend to “preserve source-code-y-ness.” Much of what seems to be happening is a mix of small changes that don’t make files too nonsensical plus combination (AFL splicing) of corpus examples that haven’t drifted too far from normal Solidity code. AFL on its own tends to reduce source code to uncompilable garbage that, even if merged with interesting code, won’t make it past initial compiler stages. But with more focused mutations, splicing can often get the job done, as in this input that triggers a bug that’s still open (as we write):
contract C {
function o (int256) public returns (int256) {
assembly {
c:=shl(1,a)
}
}
int constant c=2 szabo+1 seconds+3 finney*3 hours;
}The triggering input combines assembly and a constant, but there are no files in the corpus we used that contain both and look much like this. The closest is:
contract C {
bool constant c = this;
function f() public {
assembly {
let t := c
}
}
}Meanwhile, the closest file containing both assembly and a shl is:
contract C {
function f(uint x) public returns (uint y) {
assembly { y := shl(2, x) }
}Combining contracts like this is not trivial; no instance much like the particular shl expression in the bug-exposing contract even appears anywhere in the corpus. Trying to modify a constant in assembly isn’t too likely to show up in legitimate code. And we imagine manually producing such strange but important inputs is extremely non-trivial. In this case, as happens so often with fuzzing, if you can think of a contract at all like the one triggering the bug, you or someone else probably could have written the right code in the first place.
Conclusion
It’s harder to find important bugs in already-fuzzed high-visibility software than in never-fuzzed software. However, with some novelty in your approach, smart bootstrapping based on previous fuzzing campaigns (especially for oracles, infrastructure, and corpus content), plus experience and expertise, it is possible to find many never-discovered bugs in complex software systems, even if they are hosted on OSSFuzz. In the end, even our most aggressive fuzzing only scratches the surface of truly complex software like a modern production compiler—so cunning, in addition to brute force, is required.
We’re always developing tools to help you work faster and smarter. Need help with your next project? Contact us!