
Creating an LLVM Sanitizer from Hopes and Dreams
Each year, Trail of Bits runs a month-long winter internship aka “winternship” program. This year we were happy to host 4 winterns who contributed to 3 projects. This project comes from Carson Harmon, a new graduate from Purdue interested in compilers and systems engineering, and a new full-time member of our research practice.
I set out to implement a dynamic points-to analysis in LLVM for my winternship. Points-to analyses tell us, for a given address or pointer in our program, the type of data residing in memory at said address, and possibly, where the allocation may have occurred. This is useful because it helps evaluate the accuracy of a static analysis, augments static analysis with additional facts, and provides context into when and where certain objects are created.
The LLVM sanitizer infrastructure provides a natural location for implementing such an analysis. Sanitizers can instrument programs at compile time, and include a runtime support library with a libc implementation, interfaces for function replacement, memory and thread management, operating system-specific syscall support, and much more. To wit, many existing bug finding tools that enjoy regular use by developers are implemented as sanitizers, including:
- AddressSanitizer: Identifies invalid stack and heap accesses, use-after-frees, and other types of memory-access errors
- MemorySanitizer: Detects uninitialized reads
- LeakSanitizer: Locates memory leaks
- UndefinedBehaviorSanitizer: Detects undefined behavior (e.g., integer overflows and overshifts)
Unfortunately, I didn’t get very far with my points-to analysis due to the lack of documentation on LLVM sanitizers. Instead, I’ll give a high-level overview of LLVM and how to use it to make sanitizers, retracing the steps I went through during my winternship.
How to write your own LLVM sanitizer
I started by reviewing Eli Bendersky’s blog and GitHub repo, Dr. Adrian Sampson’s blog, conference proceedings from EuroLLVM, and LLVM’s extensive toolchain documentation. Some of the information I found was outdated, but it helped identify the modules I needed to interact with in order to build my own sanitizer.
The compiler driver is the glue between all the modules in LLVM; any information that needs to be passed between modules is passed through the driver. Building a sanitizer might require modifying any number of these components. I found understanding the drivers design important for developing on the system.
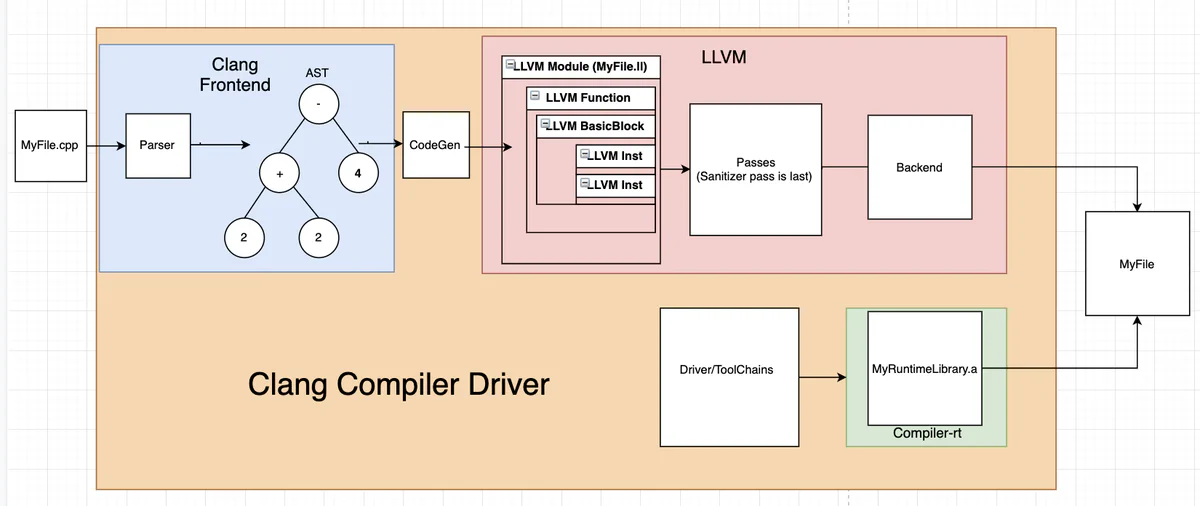
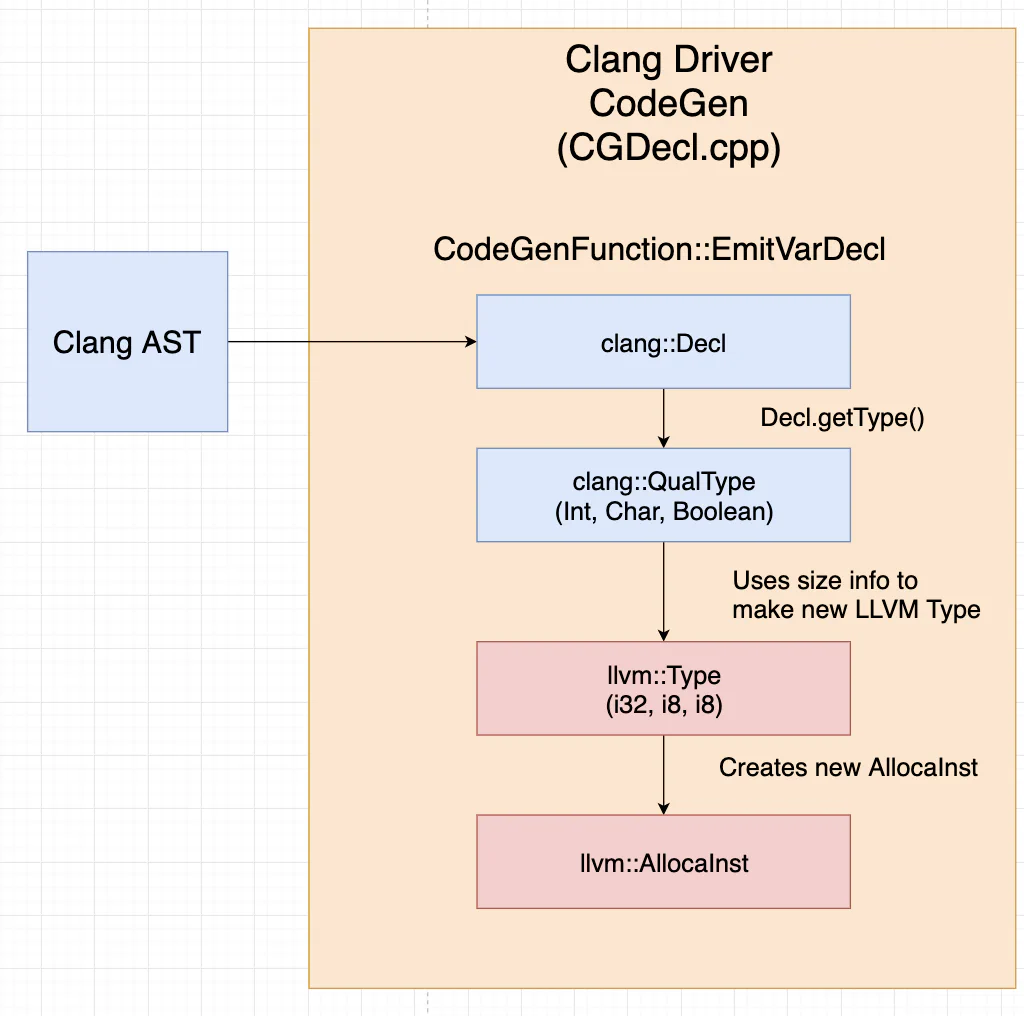
If an analysis pass or sanitizer wanted to modify the LLVM type generation process, they would need to modify the driver’s code-generation process.
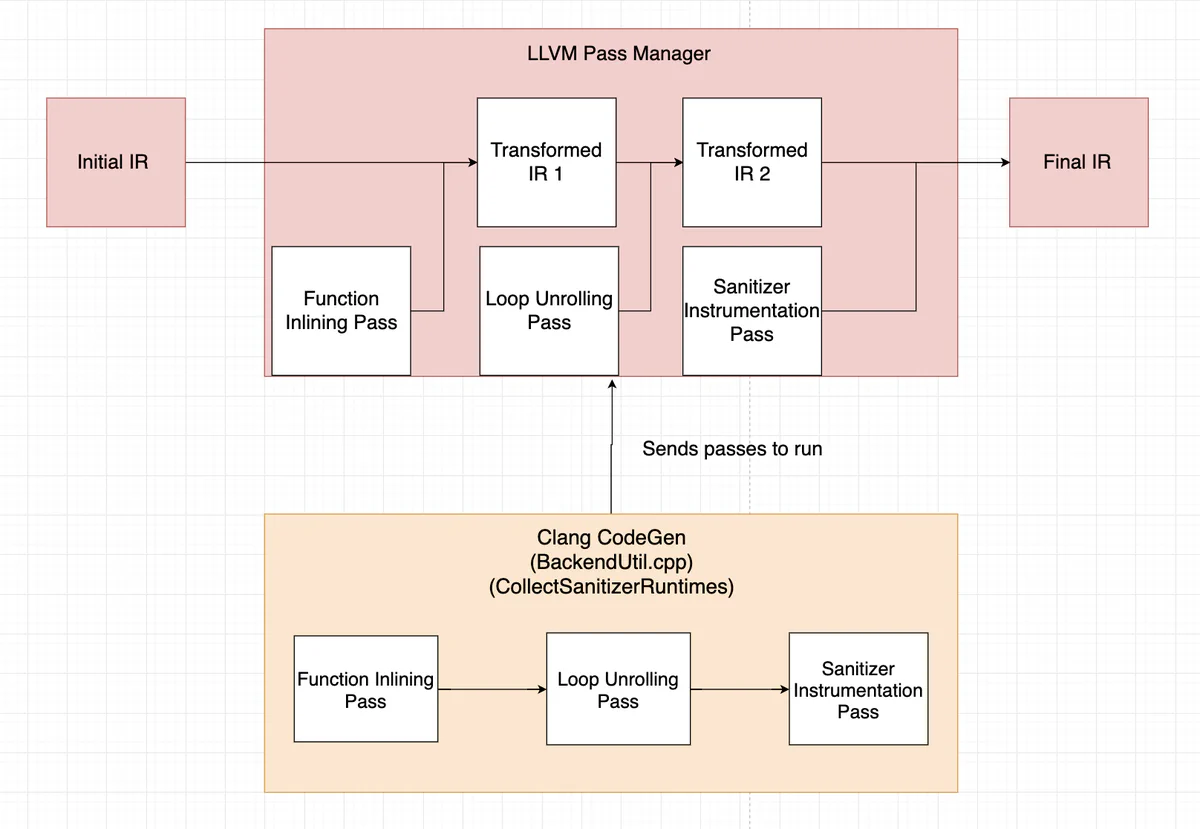
The driver is also responsible for scheduling and running LLVM passes. LLVM passes modify the IR to insert, remove, or replace instructions which is especially useful as it allows sanitizers to modify instructions and insert function calls without any extra effort from the developer. The driver registers passes based on configuration settings passed to the frontend. Sanitizer passes should be registered to run last, since the driver may run optimization passes, analysis passes, or other transformation passes that might affect your instrumentation.
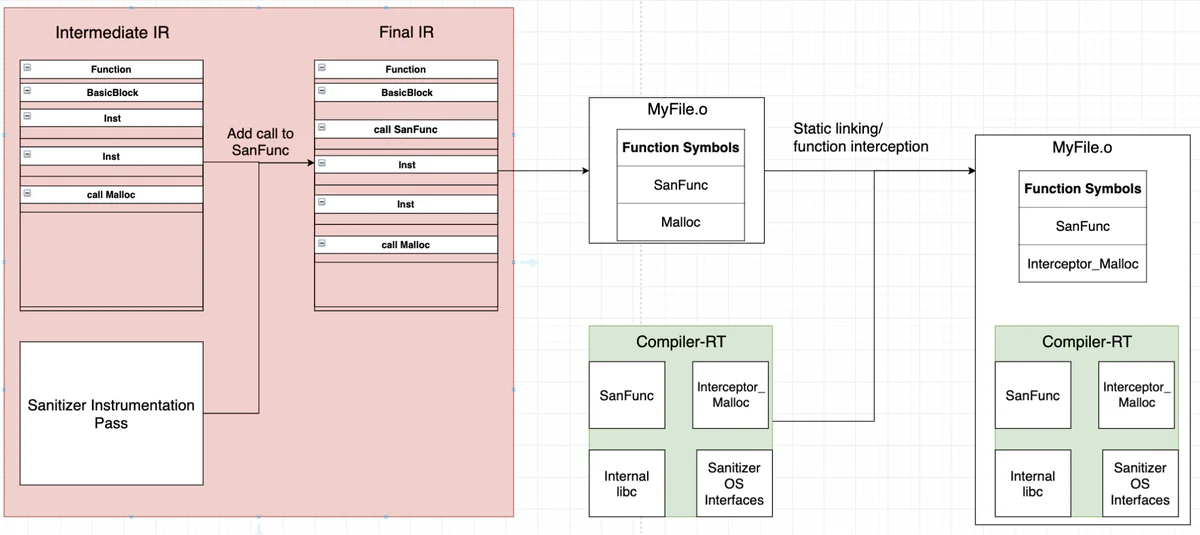
Finally, the driver is responsible for linking the sanitizer’s runtime component, compiler-rt. Compiler-rt is a library that provides sanitizers the ability to interact with the target program during its execution. This interaction can happen via LLVM transformation passes inserting calls to functions defined in compiler-rt or by using compiler-rt’s function hooking interface.
Make your own sanitizer
I created a tutorial to help make your own sanitizer that includes a prebuilt test sanitizer, a step-by-step guide on developing and integrating passes and runtime components, and other helpful resources for developing on LLVM. I think the winternship was a great way to learn something new over winter break and I wish more companies offered similar programs.