
Introducing Patch the Planet
What happens when you clear dozens of Trail of Bits engineers’ schedules, pair them with every open-source maintainer they can contact, and unleash the latest frontier models like GPT-5.5-Cyber on critical open-source targets? Thanks to our partnership with OpenAI and its Daybreak initiative, we can report that the impact is hundreds of discovered bugs, 64 pull requests, and 51 issues filed across 19 projects (with many more still undergoing coordinated disclosure). That was just the first week of Patch the Planet.
Frontier models like GPT-5.5-Cyber are producing a firehose of security findings, and already-stretched maintainers must sift through all of it to separate real vulnerabilities from plausible-sounding false positives. Patch the Planet is different: with our experts orchestrating and triaging findings, we handle the work of fixing and hardening the code alongside the people who maintain it.
The first week of Patch the Planet covered 19 projects across cryptography, networking, language infrastructure, and software supply chain. Among these 19 projects were cURL, NATS, pyca, Sigstore, aiohttp, the Go project, freenginx, Python and python.org, urllib3, PyPI, SimpleX, Valkey, and RustCrypto. Over 30 projects have joined the initiative so far, and we’re rapidly expanding it to include more; if you maintain an open-source project, apply to join!

Anyone can file an issue, flex, and walk away. We showed up with the patches: 37 are already merged, and many more are in flight. These merges go beyond just fixing bugs: we’re adding new tests and fuzzing harnesses, CI security scanning, supply-chain tooling, correctness fixes, and features maintainers had been meaning to get to. The goal of Patch the Planet is to leave essential open-source projects measurably better off.
We brought patches, not just bug reports
We’re reporting public findings on GitHub, including 64 total pull requests. We also filed 51 issues, 19 of which are already closed with a fix. This public tally undercounts the work, since several projects take reports through private channels like HackerOne, GitHub security advisories, mailing lists, and private forks, and most of these have not been released publicly yet.
What’s in those pull requests matters more than the count. At python.org, we added a CI workflow built on zizmor, an open-source GitHub Actions static analyzer, fixed all of the issues it flagged, and integrated it into their CI. In RustCrypto, we contributed correctness fixes to the big-integer library that higher-level cryptography is built on, alongside genuine feature work in review: serde encoding support and HPKE DHKEM suite IDs. Other patches were plain engineering help: storage-accounting and service-restart fixes in SimpleX, a clearer admin-quarantine confirmation in PyPI’s Warehouse, and supply-chain improvements like SBOM sidecars for Python’s Windows artifacts. We will also be upstreaming many testing improvements and new testing campaigns. Arguably, our best contributions are not even bug or security fixes.
Keeping track of all of this is a bot we call Patchy. Patchy monitors every project, posts each new finding and merged patch to our Slack, and, for reasons we consider scientifically sound, reintroduces the common use of goblins, gremlins, and assorted creatures. Here’s Patchy’s description of an issue that has been patched:

When a patch lands, Patchy celebrates with a triumphant PATCHY HAPPY. Making Patchy happy is really what drives us.

A few highlights from the week
The week produced more than we can fit in this post, but here are some quick highlights.
A fuzzing lab built in a day. Given a narrow goal (find remotely exploitable bugs) and no instructions on how, GPT-5.5-Cyber decided that reading the source of one of the most-reviewed C libraries in existence was a poor use of tokens. Instead, it stood up a full fuzzing lab in under a day: sanitizer and variant builds, a seed corpus drawn from existing tests, and harnesses across a dozen entry points. Instead of simply fuzzing exposed APIs, it successfully built a harness that injected operating system backpressure to identify novel issues by reaching previously unexplored buggy states. We estimate all of that effort likely would’ve taken one of our fuzzing experts two to three weeks to do manually. Just as important, it showed judgment about what to test, what to report (and not report), and where to find higher-impact findings. We’ll publish the full details in a standalone field report.
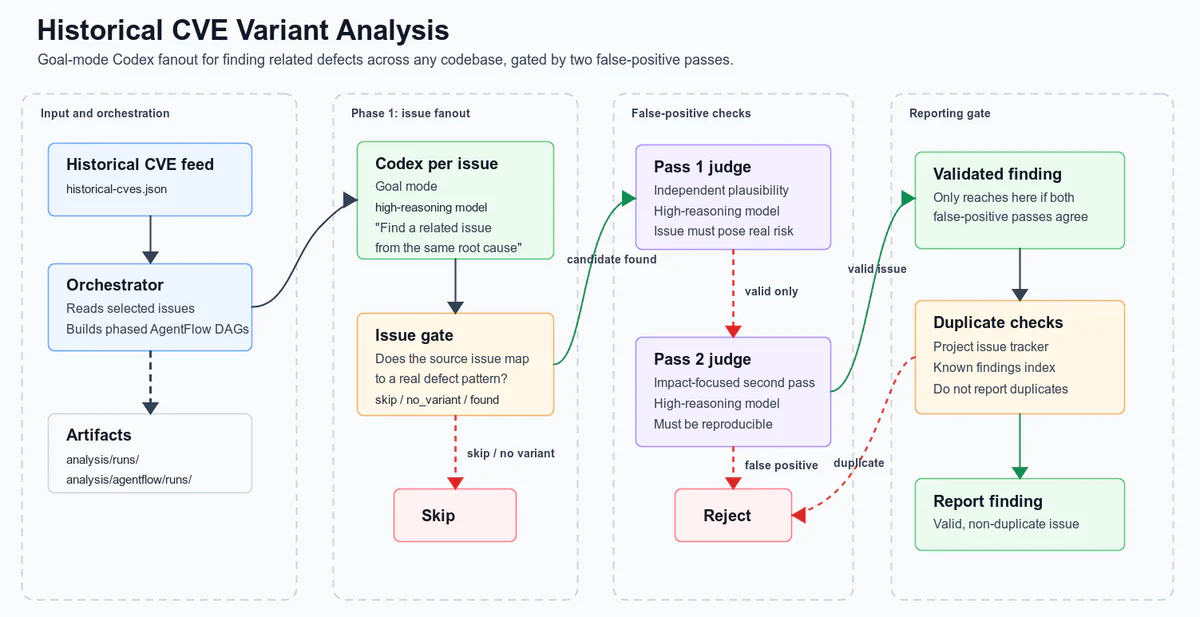
A pipeline for variant testing historical CVEs built in a day. Codex was also adept at building simple but effective pipelines, such as the CVE variant analysis pipeline shown below. Codex’s /goal feature combined with frontier models like GPT-5.5-Cyber for this type of variant analysis produced novel issues with almost exclusively high-signal output.
A release-pipeline improvement at python.org. We reported multiple security issues for python.org, including some issues closing a legacy-API authorization gap. But we’re most proud of the work that produced long-term improvements to python.org’s release infrastructure: the new zizmor CI scanning, tightened release-file and metadata validation, deletion scoping fixed so bulk operations can’t reach beyond their target, and release-tooling patches in review that quote remote command arguments, fail safely on partial uploads, and add SBOM sidecars.
The aiohttp maintainers fixed their issues almost immediately. We privately reported a cluster of issues across aiohttp’s client and server paths, including cookies that could regain broader scope after a save and reload, digest credentials that could answer a challenge from the wrong origin, and resource limits that ran after attacker-controlled buffering rather than before. The maintainers authored and merged all eight fixes within hours, seven of them inside a single five-hour window. We were impressed and appreciate the maintainers’ prompt and collaborative work on these issues!
Differentially testing major cryptographic libraries against each other. Many of our projects implement the same logic, protocols, and algorithms. In particular, multiple projects implement the same cryptographic algorithms and standards like X.509 certificates. Therefore, we used Codex to point these projects at each other, and identify any relevant behavioral differences. This proved to be a high-signal approach that uncovered several issues, including this AES-GCM issue in PyCA and several X.509 issues, which we plan to upstream to x509-limbo.
Finding the bugs is now the easy part
If it wasn’t already clear from the last several months of security news, this week makes one thing clear: the expensive part of security work has moved. Arming Codex with fuzzing campaigns, variant analysis, differential testing, agentic searching, and similar techniques produces real vulnerabilities and compresses weeks or months of manual effort into hours. The advantage is no longer in finding bugs, but everything after: confirming a finding, getting its severity right, writing a patch a maintainer will accept, hardening the surrounding code, making long-term improvements to prevent similar issues in the future, and coordinating a disclosure. That is the work that floods of AI-generated reports threaten to bury.
Guidance for maintainers
If you’re a maintainer managing an unsustainable number of AI-generated bug reports, the core challenges you need to solve are deduplication, false-positive filtering, and severity correction.
Deduplication is the easiest problem to solve technically. Even simple AI-based tools that compare new reports against open issues perform well, especially when grounded in affected code lines. Automating this step eliminates most of the noise.
False-positive filtering and severity correction are harder, but they can be managed. Without explicit guidance, models default to rating everything as critical.

Generic approaches like our fp-check tool help, but only to a point. The best improvements require project-specific documentation, threat models, and severity criteria. PyCA’s security documentation, for example, was dramatically effective at reducing false positives in our bug candidates. Files like AGENTS.md that explicitly tell models which documentation to consult produced the most consistent and effective results. If security researchers are armed with this documentation, especially AGENTS.md for AI-based research, more noise will be filtered out before reaching the maintainers.
What’s next and how to get involved
This was just our first week. Over 30 projects have committed to join Patch the Planet, with a growing waitlist. As more findings clear coordinated disclosure, we’ll publish more results and deeper field reports, including full fuzzing lab details, the variant-analysis and differential-testing pipelines, and the tooling we’re building to help maintainers triage AI-generated reports themselves. Our Patch the Planet gist contains the full public list of our week one output.

If you maintain a critical open-source project and want this kind of help, you can apply to join Patch the Planet.