
We beat Google’s zero-knowledge proof of quantum cryptanalysis
Two weeks ago, Google’s Quantum AI group published a zero-knowledge proof of a quantum circuit so optimized, they concluded that first-generation quantum computers will break elliptic curve cryptography keys in as little as 9 minutes. Today, Trail of Bits is publishing our own zero-knowledge proof that significantly improves Google’s on all metrics. Our result is not due to some quantum breakthrough, but rather the exploitation of multiple subtle memory safety and logic vulnerabilities in Google’s Rust prover code. Google has patched their proof, and their scientific claims are unaffected, but this story reflects the unique attack surface that systems introduce when they use zero-knowledge proofs.
Google’s proof uses a zero-knowledge virtual machine (zkVM) to calculate the cost of a quantum circuit on three key metrics. The total number of operations and Toffoli gate count represent the running time of the circuit, and the number of qubits represents the memory requirements. Google, along with their coauthors from UC Berkeley, the Ethereum Foundation, and Stanford, published proofs for two circuits; one minimizes the number of gates, and the other minimizes qubits. Our proof improves on both.
| Resource Type | Google’s Low-Gate | Google’s Low-Qubit | Our Proof |
|---|---|---|---|
| Total Operations | 17,000,000 | 17,000,000 | 8,300,000 |
| Number of Qubits | 1,425 | 1,175 | 1,164 |
| Toffoli Count | 2,100,000 | 2,700,000 | 0 |
Table 1: Resource upper bounds reported in different proofs for circuits computing the correct output across 9,024 randomly sampled inputs
Our proof fully verifies when using Google’s unpatched verification code. It has the same verification key as their original proofs and is cryptographically indistinguishable from a zero-knowledge proof resulting from actual algorithmic improvements to the quantum circuit. We are releasing the code we developed to forge the proof, and a summary of our proof follows.
Circuit SHA-256 hash: 0x7efe1f62bb14a978322ab9ed41d670fc0fe0f211331032615c910df5a540e999
Groth16 proof bytes: 0x0e78f4db0000000000000000000000000000000000000000000000000000000000000000008cd56e10c2fe24795cff1e1d1f40d3a324528d315674da45d26afb376e8670000000000000000000000000000000000000000000000000000000000000000024ac7f8dd6b1de6279bcce54e8840d8eb20d522bf27dedd776046f6590f33add217db465201c63724e6b460641985543d2b79c3c54daeea688581676a786aafc1dba8604a361acdd9809e268b6d8bc73943a713bb0ed0d96221f73d26def6ea4041d05b077523d9351a48b2ecd984c686b6473df69d20a24296d0a1cba3cdbe92eb13a7cc0ecd92f27f7bf23f9ac859d4293e17216dcbd85d1c7f60a52f65a9d02faef077336acd39e845d534200b575b029d6e3f0afb4f90815557233eab70b0fe88919834dd9beb90d47241f1490dc202e0dce44e4894982b07073c8d4426513732d79e9af9913b254aa29471e1a98fa1b43a1886afb5dbd36988153217aa2
Verification key: 0x00ca4af6cb15dbd83ec3eaab3a0664023828d90a98e650d2d340712f5f3eb0d4
Zero-knowledge virtual machines
Google used Succinct Labs’ SP1 zkVM for their proofs. A zkVM is essentially a way to prove that you know which private inputs for an arbitrary guest program on the zkVM generate some public output. For example, consider this basic Rust guest program.
#![no_main]
sp1_zkvm::entrypoint!(main);
pub fn main() {
// Read in private inputs a and b
let a = sp1_zkvm::io::read::<u32>();
let b = sp1_zkvm::io::read::<u32>();
// Add them together
let c = a + b;
// Write the public output a + b
sp1_zkvm::io::commit(&c);
}A user can take the private inputs 2 and 3, run this program on the zkVM, and get a proof that the program ran successfully and that the output was 5. Anyone can verify the proof, but they would get zero knowledge about whether the input was (2, 3), (1, 4), or (6, 0xffffffff). Obviously, this toy problem is simple; real programs can be significantly more complicated.
Behind the scenes, the Rust guest program compiles down to a RISC-V ELF binary. This simple architecture allows complex program logic to be encoded into provable mathematical relationships. For example, the state of the RISC-V registers after executing an instruction is a deterministic function of their state before execution. Having to prove every step makes generating zkVM proofs resource-intensive and costly, but significant engineering work has enabled proving statements about complex programs.
Google’s zkVM guest
In the case of Google’s zero-knowledge proofs, the private input is the quantum circuit (in a custom assembly language), and the program is a simulator that checks the circuit. Note that these are “circuits” in the quantum sense, not the typical zero-knowledge definition. The public output includes bounds on the number of qubits and gate operations. In general, simulating quantum circuits is difficult, but the “kickmix” circuits defined in this paper refer to a specific subset that can be tested classically.
The following script, adapted from one of Google’s examples, increments a 3-qubit value. It includes three operations and a total of three qubits. Note that the first instruction CCX has two inputs (q0 and q1) and computes q2 = q2 ^ (q0 & q1). This is called a Toffoli gate. Toffoli gates are quite useful, but they’re much harder to implement on actual quantum hardware, so the complexity of quantum algorithms is sometimes measured in the number of Toffoli gates (or more accurately, non-Clifford gates). Circuits like this are serialized into bytes and sent to the zkVM simulator.
# Increment a value held in 3 qubits (q2, q1, q0). Sends
# (0, 0, 0) -> (0, 0, 1)
# (0, 0, 1) -> (0, 1, 0)
# ...
# (1, 1, 1) -> (0, 0, 0)
# If q0 and q1 are set, flip q2.
CCX q0 q1 q2
# If q0 is set, flip q1.
CX q0 q1
# Flip q0.
X q0To verify that a circuit computes the correct function, the simulator deserializes the circuit, randomly initializes the qubits (e.g., to (1, 0, 1)), iteratively applies every operation in the circuit, and panics unless the final state is as expected (e.g., (1, 1, 0)). The simulator repeats this for many different inputs (9,024 times, to be precise), so proving that the simulator terminated without error is essentially the same as proving that the circuit is correct with high probability. In Google’s zkVM program, the circuit must compute one elliptic curve point addition, a critical subroutine of Shor’s algorithm for solving the elliptic curve discrete logarithm problem.
In addition to checking that the circuit computes the correct function, it also counts the total number of operations, the number of qubits, and the average number of Toffoli gates (some Toffoli gates are conditioned on classical bits and may be skipped during simulation). These performance metrics are checked to ensure they do not exceed specified upper bounds; if they don’t, the upper bounds are committed as public output.
Plan of attack
Since Google’s zero-knowledge proof comes from the results of running a Rust simulator on a private kickmix assembly script, we can create our own zero-knowledge proof by providing our own private input to the same program. If we find some input that causes the simulator to misreport the quantum costs, we’ll have successfully forged a proof. To beat Google’s results on any metric, we have the following goals:
- Must compute elliptic curve point addition correctly
- Preferably reports fewer than 17 million total operations
- Preferably reports fewer than 2.1 million Toffoli gates
- Preferably reports fewer than 1,175 qubits
This turns a quantum computing problem into an application security problem. Any deserialization bugs when parsing the kickmix circuit input are fair game, as well as any logic bugs we find in the simulator.
Vulnerability 1: Bypassing the Toffoli counter
One area of concern in the Rust source code was the use of unsafe blocks, disabling important memory safety checks. This was presumably done to reduce the overall cycle count of the zkVM guest program; each additional bounds check inflates the already substantial cost of generating a zero-knowledge proof, particularly checks that run millions of times. The vulnerability starts in the following two lines of code from program/src/main.rs.
let private_circuit_bytes = sp1_zkvm::io::read_vec();
let ops = unsafe {
rkyv::access_unchecked::<rkyv::Archived<Vec<Op>>>(&private_circuit_bytes)
};The first line shows that private circuit bytes (private_circuit_bytes) are directly read from outside the zkVM, and the use of the rkyv serialization library’s access_unchecked function instructs the library to assume that private_circuit_bytes corresponds to a valid serialization. But data from outside the zkVM is untrusted, so what happens if the bytes, which are meant to represent a vector of circuit operations, are malformed?
The answer is “not much.” There are relative pointer offsets and length fields in the serialization for the Vec type, but I couldn’t see a viable path from manipulating those to getting the prover to underreport resource counts. The Op type is similarly simple, consisting of seven 32-bit fields: one describes the OperationType, and six describe the identifiers of which qubits and classical bits to use as inputs and outputs for the operation. For a while, I was chasing down a bug in how the magic identifier 0xffffffff could bypass the qubit count and trigger an out-of-bounds write in the array of simulated qubit values. I was deep in the details of understanding the Rust heap allocator used by the SP1 zkVM before a colleague pointed out that Google was using SP1’s 64-bit RISC-V architecture rather than the potentially exploitable 32-bit architecture.
That left the kind field, an enum describing which of the 18 supported kickmix OperationType opcodes to apply. When simulating the quantum circuit, the guest program iterates over the vector of operations and determines whether to conditionally execute each operation; if so, it increments the count of Toffoli or Clifford gates, depending on the operation type, and executes the operation. This code is in Simulator::apply_iter.
match op.kind {
OperationType::CCZ | OperationType::CCX => {
self.stats.toffoli_gates += executed_shots;
}
OperationType::CX
| OperationType::CZ
| OperationType::Swap
| OperationType::R
| OperationType::Hmr => {
self.stats.clifford_gates += executed_shots;
}
// Note: X and Z are not considered Clifford gates in the
// stats because they can be tracked in the classical control system.
// They don't need to cause something to happen on the quantum computer.
_ => {}
}
match op.kind {
OperationType::CCX => {
let v = cond & self.qubit(op.q_control1) & self.qubit(op.q_control2);
*self.qubit_mut(op.q_target) ^= v;
}
OperationType::CX => {
let v = cond & self.qubit(op.q_control1);
*self.qubit_mut(op.q_target) ^= v;
}What if op.kind falls outside of the expected 0–17 range because rkyv was instructed not to check this value during deserialization? This is undefined behavior, so to investigate, I used Ghidra to reverse-engineer the RISC-V ELF binary Google provided with their proof.
After identifying the location of this function in the binary, I discovered that the Rust compiler emits a pair of jump tables for these two match expressions. The first jump table determines which gate counter to increment, and the second performs the actual operation. But we maliciously control the value of op.kind, so what if instead of the normal behavior, we dereference past the end of the first jump table and directly jump to an address from the second jump table? Then an out-of-range OperationType could still perform the correct operation, but it would completely bypass the Toffoli counter!
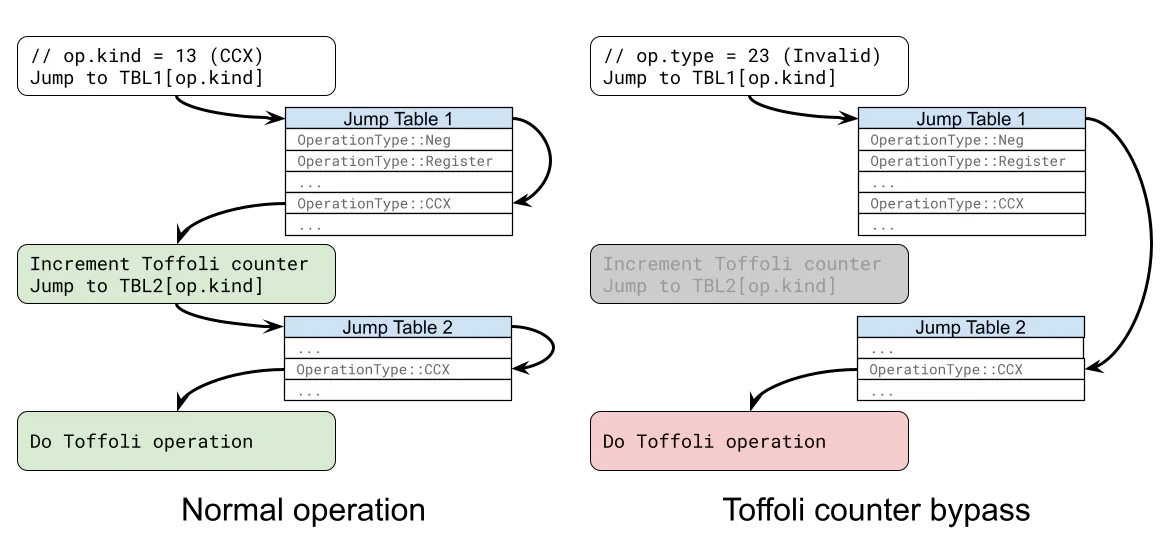
I calculated the necessary offsets, modified Google’s example prover code to inject the invalid operation types, and attempted to simulate a zero-knowledge proof of a simple 64-qubit adder circuit. To my surprise, it worked on the first try.
stdout: circuit.average_cliffords_performed() = 0
stdout: circuit.average_non_cliffords_performed() = 0
stdout: The circuit passed fuzz testing.I had been concerned that the RISC-V registers would be in an invalid state when jumping into the wrong table, but this ended up not being the case. Now I had the primitive I needed to forge a circuit that misreports the number of Toffoli gates, and I just had to scale up my attack on the 64-qubit adder circuit to full elliptic curve point addition.
Building a quantum circuit
I now had a virtually unlimited budget for Toffoli operations, and the path forward looked simple. I could implement any kickmix circuit that correctly performs elliptic curve point addition without worrying about the Toffoli count, tweak the operation types before feeding the script to the prover, and then forge a proof for whatever Toffoli upper bound I wanted. I might use more total operations or more qubits than Google’s circuits, but it would be an amusing proof of concept. The only concern was that the prover’s running time is proportional to the total number of operations, so my circuit still needed a reasonably low operation count.
It turns out that programming a quantum computer is way more challenging than I anticipated, and this is because of the requirements of reversibility and uncomputation.
Requirement 1: Reversibility. A quantum circuit is made up of a series of reversible (unitary) gates. For kickmix circuits, think of these as reversible bit operations. For example, c’ = c XOR b is allowed because the original value of c can be recovered with c = c’ XOR b. On the other hand, c’ = c AND b is not allowed because if c’ and b are both 0, we cannot know if c was originally 0 or 1. By itself, AND is not reversible, but with an additional input in Toffoli gates, it is. The kickmix Toffoli operation CCX q1 q2 q3 updates q3 to q3’ = q3 XOR (q1 AND q2), and this operation can be reversed with q3 = q3’ XOR (q1 AND q2).
Requirement 2: Uncomputation. To avoid the undesirable effects of entanglement, any auxiliary (or ancilla) qubits used to store intermediate results of computation must be “uncomputed,” or reset to state 0. The reversibility requirement makes this a challenge, since the intermediate result may have been 0 or 1. The intermediate state must be uncomputed from the computation result in order to be reversibly cleared out.
As we try to build our reversible elliptic curve point addition circuit with uncomputation, a couple of tools are available. We could use Bennett’s trick, which involves preserving inputs and outputs in spare qubits, then running the full computation a second time in reverse to clear ancilla qubits. This approach isn’t ideal because it roughly doubles the operation count for each level of the call stack. Another approach is to use the more efficient measurement based uncomputation. Google has revealed that this is the technique their circuits use, but it requires a much finer-grained algorithmic analysis to apply correctly.
Vulnerability 2: Efficient operations with register aliasing
After struggling to implement elliptic curve point addition while keeping the operation count and qubit count low, I discovered another exploitable vulnerability: register aliasing. Recall the Toffoli (CCX) operation defined in Simulator::apply_iter.
OperationType::CCX => {
let v = cond & self.qubit(op.q_control1) & self.qubit(op.q_control2);
*self.qubit_mut(op.q_target) ^= v;
}There’s no check that the qubit inputs (op.q_control1 and op.q_control2) are different from the qubit output (op.q_target), so tying all three together becomes q1 = q1 ^ (q1 & q1) = 0. That is, we can immediately reset a qubit to zero, violating the quantum requirement of reversibility and making uncomputation trivial.1

In addition, we can use this primitive to create any logical gate we want, like the classical AND gate that violates reversibility or the functionally complete NAND gate. Now that I don’t have to deal with the limitations of quantum circuits, it’s basically Nand2Tetris, except the goal is elliptic curve point addition. I implemented basic logic gates, followed by integer addition and subtraction, modular addition, modular multiplication, modular inversion, and, finally, point addition.
After exploiting a memory corruption issue in unsafe Rust code, implementing elliptic curve operations from the ground up using individual logic gates, and squeezing whatever performance I could out of the non-quantum aspects of the design, I finally had a working kickmix script that passed validation. 0 Toffolis, 8 million operations, and 1288 qubits. This beats one of Google’s two proofs but falls short of beating the other one by just 113 qubits.
If I wanted to truly claim that our zero-knowledge proof beat Google’s, I couldn’t leave it there. I needed to find some way to shave off 113 qubits, but I was all out of vulnerabilities.
The final challenge: Euclidean algorithm optimization
Profiling my circuit made it clear that the most expensive operation was modular inversion, and the same is true for many published quantum elliptic curve addition circuits. My optimized circuit required 4 field elements (1024 qubits) for the inversion, including some tricks to store intermediate field elements, and a handful of qubits for control flags and carry bits. If I were to beat Google’s proof, I needed to lose those tricks and do modular inversion using fewer than 2.59 field elements.
One idea is to use Fermat’s little theorem: $x^{-1} \equiv x^{p-2} \pmod{p}$. We replace inversion with exponentiation, which is just a sequence of modular multiplications. Each multiplication requires three field elements, and this approach requires hundreds of multiplications, well beyond our total qubit and operations budget.
What many quantum circuits use instead is a variant of the extended Euclidean algorithm (EEA). To compute $x^{-1} \pmod{p}$, this algorithm involves four variables $(a, u, b, v)$ initialized to $(x, 1, p, 0)$. The algorithm proceeds through several iterations to cancel out bits of $a$ and $b$, perform the same operations to $u$ and $v$, and (assuming $x$ and $p$ are coprime) the algorithm terminates with $(a, u, b, v) = (0, 0, 1, x^{-1})$.
I based my implementation on the binary EEA, a variant that involves canceling out the least significant bits of a and b rather than the standard most significant bits. Thanks to Thomas Pornin’s clear exposition of this algorithm, it was relatively easy to reimplement a high-performance version in my circuit, but the qubit overhead was still too high.
Next, I found this recent preprint by Han Luo, Ziyi Yang, Ziruo Wang, Yuexin Su, and Tongyang Li, which came out just days after Google’s announcement. It describes a method to compute modular inverses with the space equivalent of 3 field elements. Many of the techniques went above my head, but they open-sourced their code, so I had a much easier time understanding their paper. Their code included a Qiskit circuit, but I was unsuccessful in integrating this into my exploit. Despite these difficulties, the paper gave me the key term I would need to shave off the remaining qubits: Proos-Zalka register sharing.
The 2003 paper by John Proos and Christof Zalka recognizes that over the course of the standard EEA, the bit-lengths of a and b gets smaller, while the bit-lengths of u and v get larger. Their register-sharing algorithm saves space by limiting the number of qubits for each value at each iteration. This can fail with low probability, but rare failures are tolerable when doing Shor’s algorithm. I implemented a classical version of the register-sharing algorithm of Proos and Zalka, and I ended up with 30 million total operations, almost twice Google’s result.
Finally, I had the insight I needed. What if I combined the operation efficiency of the binary EEA with the space efficiency of the Proos-Zalka algorithm? The binary EEA doesn’t have the same bounds on u and v as the standard EEA, but a slight tweak (doubling v instead of halving u) does, and needs only a simple correction factor at the end. This idea is deeply connected to Kaliski’s method, which is considered in papers by Roetteler et al., Gouzien et al., Häner et al., and Litinski. Reversibility constraints require an extra qubit for each of about 512 iterations, but our implementation doesn’t need to be reversible.
Thanks to register sharing, my final modular inversion requires the space of only 2.55 field elements, barely less than the 2.59 required. In total, my elliptic curve point addition circuit uses 8,288,880 operations, 1,164 qubits, 5,980,691 pre-bypass Toffoli gates, and 0 reported Toffoli gates. This is less than half the reported operations in Google’s circuits and just a few qubits fewer than their best variant. The source code for generating this proof of concept is available here.
What Google’s secret circuit (probably) does
The zero-knowledge properties of the proof makes this unanswerable, but framed in a different way, we can answer what problems are documented in prior work that Google would have to overcome to achieve their results.
Google’s circuit does elliptic curve point addition, which requires at least one modular division. In previous circuits, modular inversion is the most expensive step in terms of gate count and qubit count, so that’s where improvements are needed most. Our register-sharing implementation shows that 2.55 field elements of storage is enough for a nonreversible circuit, but prior quantum implementations of Kaliski’s EEA variant require an extra qubit per iteration to preserve reversibility. This adds 512 qubits of overhead to guarantee that modular inversion is invertible, and a circuit based on Kaliski’s method with Google’s qubit counts would need to solve this problem.
Even the most revolutionary scientific breakthroughs are rooted in published literature, and I think a healthy understanding of prior work can help demystify the risk of a shadowy adversary destabilizing cryptocurrencies with a secret algorithm.
The aftermath
Zero-knowledge proofs are a transformational new technology with wide-ranging impacts, and their application to vulnerability disclosure is still new. Without knowing the details of their circuit, it’s impossible for me to conclude whether Google’s decision to announce this discovery using a zero-knowledge proof is justified. However, I do have experience with both vulnerability disclosure and academic publishing, and this points to broader implications in the deployment of zero-knowledge technology.
One potentially overlooked aspect of coordinated disclosure is the importance of an embargo period. Current industry best practices recommend a 30-day buffer between a timely patch becoming available and full disclosure of the technical details. This allows time for patch adoption, benefits defenders who rely on the technical details, and prevents opportunistic exploitation by low-skill attackers. Zero-knowledge proofs can communicate the importance of patching, but they are not a cryptographic replacement for the benefits of eventual disclosure.
In academic publishing, the more details that are available in published work, the easier it is to improve upon that work. Papers that intentionally facilitate replication and have a clear statement of methods and claims are usually the ones that are later cited and have the greatest impact. Using a zero-knowledge proof still establishes improvement over prior work; it also indicates a confidence that no one else will independently develop the same improvement, and that no one but the authors will be able to improve upon the discovery in future work.
As a direct example of the value of open publishing, I want to highlight Google’s decision to release a well-documented kickmix simulator and thorough proof generation instructions. This is the sole reason I was able to find and demonstrate the vulnerabilities, and their patches simultaneously increase confidence in their zero-knowledge claims while preventing attackers from forging proofs of quantum breakthroughs that spread fear, uncertainty, and doubt.
Zero-knowledge systems are an incredible technology with many applications, but their use introduces a different set of risks than traditional approaches. They aren’t a magic wand that eliminates trust; instead, they redistribute trust from an original domain, such as the opinions of scientific experts, to trust in programming languages, compilers, proof systems, and cryptography experts. There are many frontiers that are considering the benefits of zero-knowledge, including electronic voting and age verification, but it’s also critical to consider the risks and make plans for what happens when this technology fails.
Acknowledgments
Thank you to Craig Gidney, Ryan Babbush, Tanuj Khattar, and Adam Zalcman from Google for their quick response and for putting up with my naive questions about quantum algorithms, and to Sophie Schmieg for putting us in touch. Finally, this would not have happened without Joe Doyle and the wider Trail of Bits cryptography team, whose suggestions and enthusiasm pushed this project over the finish line.
There’s a second bug in the
HMRandRinstructions, which are meant to reset a qubit to 0 while randomizing the phase. An error in conditional logic makes it possible to reset the qubit without trashing the phase, but register aliasing is a strictly better exploit primitive. ↩︎