
Datasig: Fingerprinting AI/ML datasets to stop data-borne attacks
Today we’re releasing Datasig, a lightweight tool that solves one of AI security’s most pressing blindspots: knowing exactly what data was used to train your models. Datasig generates compact, unique fingerprints for AI/ML datasets that let you compare training data with high accuracy—without needing access to the raw data itself. This critical capability helps AIBOM (AI bill of materials) tools detect data-borne vulnerabilities that traditional security tools completely miss.
Training data is a major attack vector against AI systems. Attackers can use techniques like data poisoning to backdoor models, leak private information, or silently introduce bias—often leaving no obvious traces of their handiwork. When these attacks happen, most organizations can’t even answer a simple question: “What data did we actually use to train this model?”
Without data traceability, you can’t verify a model’s integrity, audit for compliance, or investigate security incidents. Yet the AI ecosystem still lacks tools to fingerprint training data without storing the entire dataset (which is often impractical for privacy, legal, and storage reasons).
Datasig creates unique identifiers and compact fingerprints for AI/ML datasets that make it easy to automate comparing datasets with great accuracy and without access to the raw data. It proposes a theoretical solution to dataset fingerprinting and provides a practical implementation, as we demonstrate on the MNIST vision dataset.
This post reviews the AI/ML security research that motivates Datasig, describes how our prototype works in detail, and discusses its future evolution.
Ready to dive straight into the code? Check out Datasig on GitHub.
Why your AI security is incomplete without data traceability
Traditional security tools have blindspots when it comes to AI’s unique attack surface. Your SBOM might tell you which libraries your model is using, but it knows nothing about the data that shaped your model’s behavior. This blind spot creates a perfect opportunity for attackers.
The rise of AIBOM tools
AI Bill of Materials (AIBOM) tools are emerging to fill this gap, aiming to document the entire AI supply chain. But there’s a critical piece missing: a reliable way to track and verify training data. Without this capability, these tools can’t answer fundamental questions like:
Was this model trained on poisoned data?
Did sensitive information leak into the training set?
Are two models using the same datasets, making them vulnerable to the same attacks?
Why training data is so hard to track
Tracing datasets isn’t as simple as adding a dependency to your requirements.txt file. Three key challenges make this particularly difficult:
Data volatility: Datasets evolve constantly. Without capturing the exact state at training time it becomes impossible to reproduce or verify anything about training data.
Scale and privacy issues: Storing complete copies of training data is often impractical or legally problematic, especially for large datasets containing personal information.
Different vulnerability patterns: data-borne vulnerabilities are inherently different from traditional software vulnerabilities, and traditional dependency scanning can’t check for the presence of vulnerable data.
Datasig’s approach: Fingerprinting that works
Datasig helps trace and verify what data was used to train a model without storing all the data itself. It does so by using a novel dataset fingerprinting approach that generates unique identifiers and compact fingerprints for AI/ML datasets. This allows upstream AIBOM tools to compare datasets with great accuracy without access to the actual training data, improving dataset verifiability and traceability in AI/ML systems. More precisely, fingerprints allow AIBOM tools to:
- Verify dataset provenance
- Compare datasets to identify potential vulnerabilities based on similarity
- Track dataset evolution across model versions
- Detect when a model might have been trained on compromised data
Under the hood: How datasig works
Datasig’s dataset fingerprinting approach is based on MinHash Signatures. Datasig takes the dataset as input and outputs a list of binary hash values that mathematically corresponds to a MinHash Signature. This fingerprint can be compared to another to estimate how similar the corresponding datasets are. Here’s how it works:
The fingerprinting process
Canonization: Datasig first transforms the dataset into a standardized format. We hash each individual data point (image, text sample, etc.) to create a flat set of hash values.
MinHash transformation: We then apply MinHash algorithms to this canonical representation, generating a fixed-size signature that preserves similarity relationships. This MinHash signature is the dataset fingerprint.
Comparison: The fingerprint can then be compared directly to other fingerprints to measure dataset similarity without needing the original data.
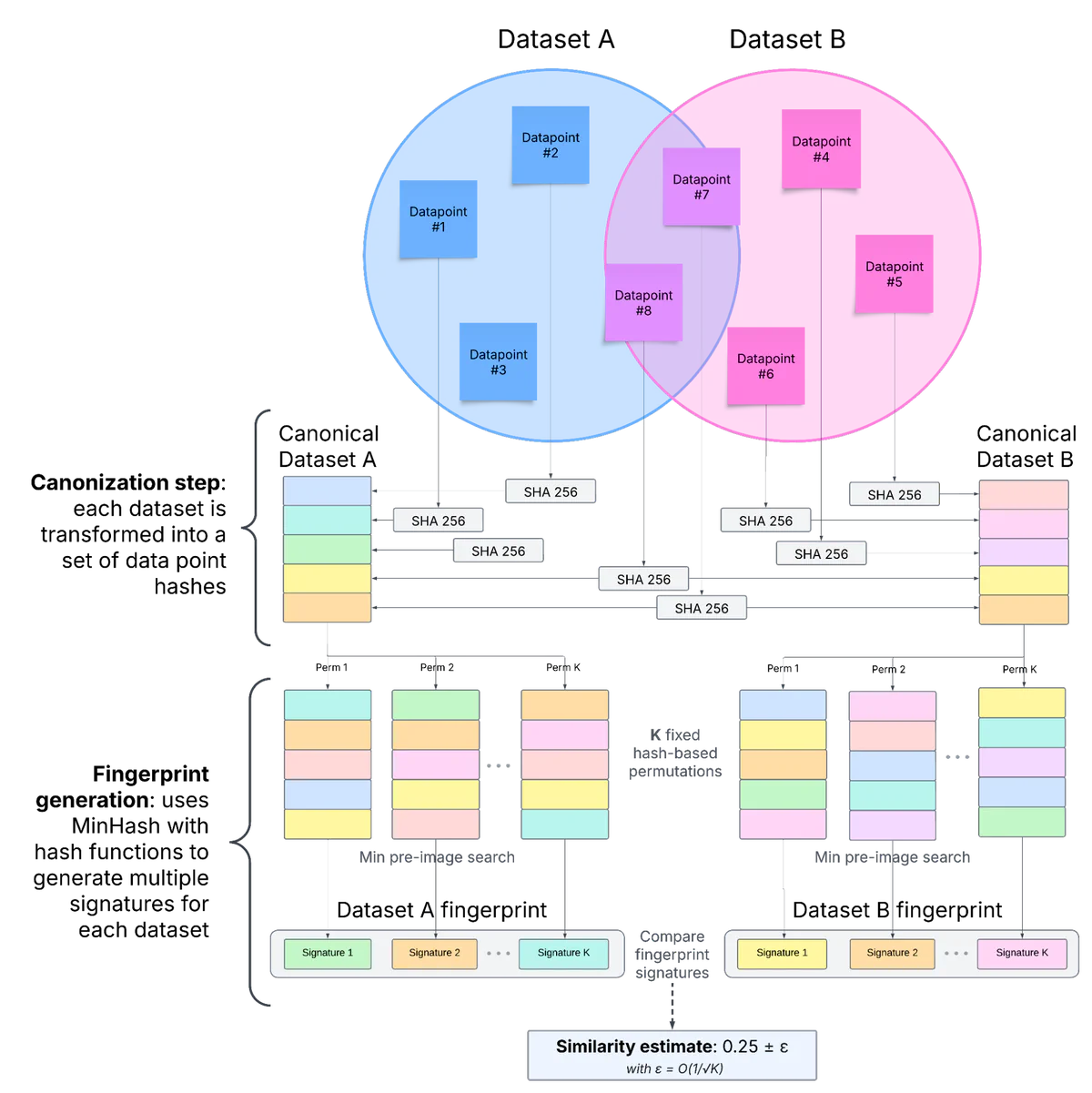
This approach leverages mathematical properties of MinHash to make fingerprints an excellent approximation of how similar two datasets are in terms of identical data points (see the Jaccard index). In our experiments, we use fingerprints consisting of 400 hashes, which give a bounded error margin as small as 5%. Accuracy can be bolstered by generating longer fingerprints, at the cost of heavier computations.
We’re preparing a technical whitepaper that dives deeper into the mathematical foundations, but the key takeaway is this: Datasig’s approach is mathematically sound, produces compact fingerprints, and maintains high accuracy across diverse dataset types.
Real-world validation: The MNIST test case
To demonstrate Datasig’s effectiveness, we put it to the test with the MNIST dataset—a standard computer vision benchmark. Our implementation supports PyTorch vision datasets out of the box, with a clean, straightforward API:

Fingerprinting testing
We wrote tests on MNIST data that build datasets of various degrees of similarity, compute their fingerprints, and estimate their similarity through fingerprint comparison only. The tests empirically confirm that the generated fingerprints, while very compact in size, are very good estimators of dataset similarity, as shown below:.
| Dataset 1 | Dataset 2 | True Similarity in % | Estim. Similarity in % | Error in % |
|---|---|---|---|---|
| Full training set | Full training set | 100 | 100 | 0 |
| Full training set | Half training set | 50 | 52.5 | 2.5 |
| Full training set | Full test set | 0 | 0 | 0 |
| Merged full training & full test sets | Full test set | 14,28 | 13 | 1.28 |
Figure 2: True dataset similarity vs. estimated similarity using compact fingerprints - raw MNIST dataset - expected error <5%
What’s next for Datasig
Datasig shows promising results as a prototype, but we’re just getting started. Our roadmap focuses on making it production-ready for real-world AI security needs.
First, we plan to expand format support beyond PyTorch. We’ll integrate with HuggingFace and add support for database-backed datasets through SQLite and streaming interfaces. This will make Datasig useful across the full spectrum of AI applications.
On the technical side, we’re refining our core fingerprinting approach. We’re exploring single-function MinHash variants that could improve performance, testing alternatives to SHA1, and investigating non-hash-based permutation schemes. All of these improvements aim at strengthening fingerprint properties while making Datasig faster and more resilient.
Finally, we recognize that Python isn’t always the best choice for performance-critical tools. That’s why we’re considering a low-level language implementation of our fingerprinting algorithm to dramatically improve computational efficiency—a critical requirement for large-scale AI systems.
Our goal is straightforward: to provide the missing piece that current AIBOM tools need to effectively address data-borne vulnerabilities in AI systems. We view Datasig as part of a comprehensive approach to AI security—one that finally brings the same level of rigor to AI systems that we expect from traditional software.
If you’re interested in contributing or have feedback on our approach, check out the GitHub repository where our development continues in the open.