
Threat modeling the TRAIL of Bits way
Our threat modeling process is a little bit different. Over time, multiple application security experts have refined this process to provide maximal value for our clients and to minimize the effort required to update the threat model as the system changes.
We call our process TRAIL, which stands for Threat and Risk Analysis Informed Lifecycle. TRAIL enables us to trace and document the impact of flawed trust assumptions and insecure design decisions through our clients’ architectures and the systems and processes that support them. Mitigating system-level findings like these squashes whole classes of vulnerabilities, which means fewer one-off bug reports and fixes to worry about.
What TRAIL is
We’ve all used a variety of threat modeling methodologies over the years; each has its strong suit, but none perfectly fit our clients’ needs, so we combined the best parts of what we knew and iterated to build our own process. TRAIL initially extended Mozilla’s single-component Rapid Risk Assessment (RRA) process to whole systems (large and small), incorporating parts of the NIST SP 800-154 Guide to Data-Centric Threat Modeling and the NIST SP 800-53 security and privacy controls dictionary.
While RRA’s data dictionary inspired our approach, TRAIL enables us to model all in-scope parts of the system and their relationships with more rigor. When following TRAIL, we systematically cover each connection between components. We don’t just uncover direct threats to the data that each component handles, but also emergent weaknesses that arise from improper interaction between components, and other architectural and design-level risks.
Security patching can easily become a cycle of receiving a security report, making a one-off fix, and then getting yet another ticket that documents yet another instance of exactly the same problem. Structured threat modeling breaks this cycle of treating the symptoms over and over. A proper threat model exposes design-level weaknesses (of which individual vulnerabilities are symptoms) so they can be remediated.
Why a TRAIL threat model provides value
TRAIL has three goals:
- Document the current system’s architecture-level and operational risks;
- For each risk, provide our client with both practical, short-term mitigation options and long-term strategic recommendations;
- Enable our client to update the threat model themselves1 as they mitigate risks, and the system otherwise changes over time.
Throughout the software/systems development life cycle (SDLC)2, application security review results in a better product. The design phase of the SDLC is an ideal time for collaborative3 threat modeling exercises involving both security engineers and the people building the system: there aren’t yet users relying on particular system features, but requirements are mostly set in stone, so it’s easier to make design improvements. But the second-best time to plant a tree is, naturally, now. Threat modeling work provides value in every SDLC phase since it improves developers’ understanding of the consequences of design choices.
How TRAIL works
Model building
TRAIL’s foundation is in first building as accurate a model as possible. We work with our client to identify all in-scope system components. Then, we’ll place a trust boundary anywhere that security controls4 gate connections between components (or should, as per security requirements and design). We’ll group components that share trust boundaries into trust zones.
We’ll talk extensively with our client and read their system documentation to build knowledge of the system and its SDLC, uncovering and documenting previously unwritten assumptions. Then, we establish relevant combinations of connections and threat actors5, especially for those connections that cross trust boundaries. We call these connection-actor combinations threat actor paths6.
While our discussion of potential threats with the client throughout this process is relatively free-form, building threat actor paths ensures we stay rigorous and don’t miss a way that an attacker could maliciously escalate their privilege or cause data to move between components or out of the system.
Threat scenarios
Our core model-building work allows us to identify design-level and operational risks that our client could have otherwise missed. We’ll document these risks in the form of threat scenarios. Each threat scenario describes a potential way that an adversary could exploit a single connection crossing a trust boundary between two components in the system. Putting threat scenarios together and doing further confirmation research enables us to write findings, but we’ll discuss findings later. For some threat modeling exercises, we will stop refining our system context at this point and will wrap up our work with summary-level remediation recommendations—we call this type of review a lightweight threat model.
What you get from a lightweight threat model
A lightweight threat modeling engagement results in an end-to-end, high-level overview of the risks inherent to a system’s design, illustrated with a handful of threat scenarios plus recommendations. Our clients typically use the results of lightweight threat models to guide further security review and remediation. Here are a few threat scenarios from the 2023 Trail of Bits assessment of the Arch Linux package manager, Pacman:
| Scenario | Actor(s) | Component(s) |
|---|---|---|
An environment variable affects the Pacman package manager’s libcurl dependency. For instance, Pacman redirects its HTTP connections through the proxy defined in the http_proxy environment variable. If an attacker injects an environment variable into Pacman’s runtime environment — a difficult prospect, given that it runs as root during installs — they could cause Pacman to exhibit exploitable or undesirable behavior. |
|
|
| An attacker attempts a substitution attack, bumping versions on a popular package through a compromised local network repository or remote repository. Pacman will always install the latest version of a package across all repositories it has access to. As such, if a user has both local and remote repositories enabled, an attacker who can introduce an identically named, higher-versioned package into one of the remote repositories can easily induce the user to install this version of the package. Similar attacks may also be possible via DNS confusion (e.g. if an attacker registers a domain that shadows a local network domain name). See this GitHub blog post on substitution attacks against npm. |
|
|
| An attacker compromises a packaging key and produces different but valid signatures for a package to introduce malicious changes. In this case, Pacman would install the new package version normally, and the user would be entirely unaware. Currently, there is no way to enable a warning when a package’s signature changes. |
|
|
Table 1: Example threat scenarios from our 2023 assessment of Arch Linux Pacman
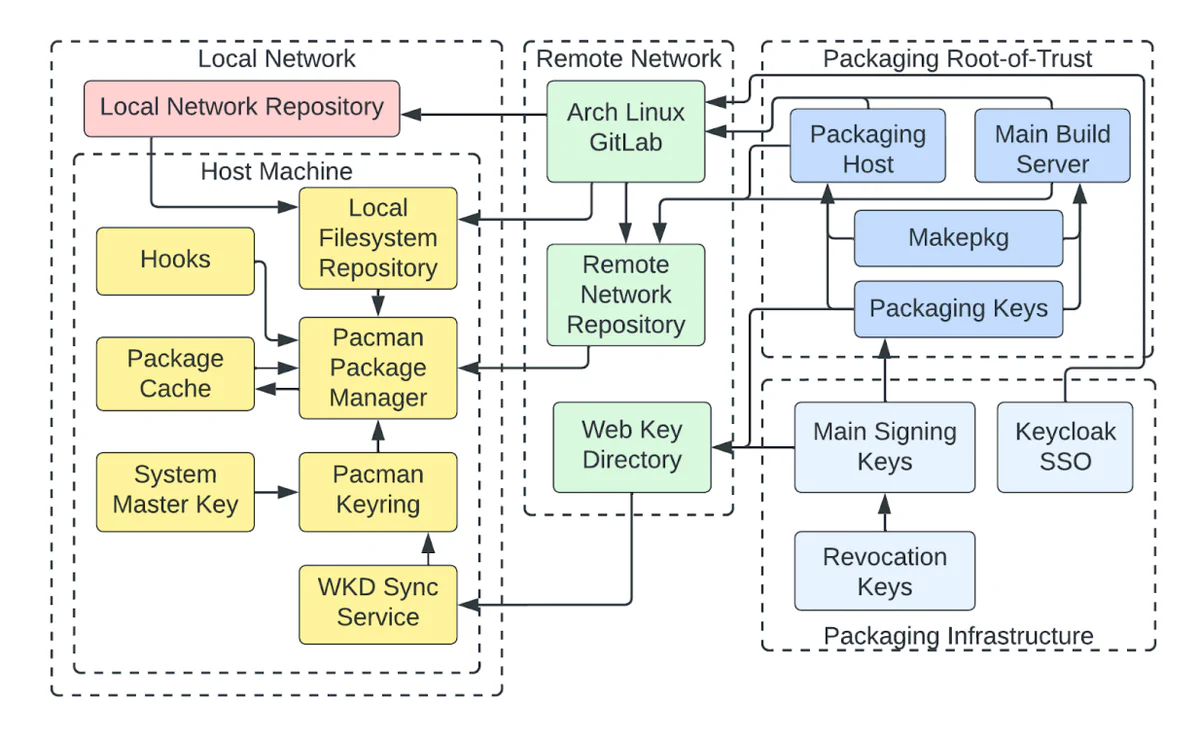
More lightweight threat models can be found in audit reports in our Publications repo, including in the reports from our assessments of CoreDNS, Eclipse Jetty, Kubernetes Event-Driven Autoscaling (KEDA), and others.
Findings and follow-on work
When a client wants a more granular security review but isn’t sure how best to target it, we can do a lightweight threat model and use its results to scope a follow-on secure code review, infrastructure review, or fuzzing work to just a few threat scenarios or system components.
Or, instead of stopping with the high-level overview provided by a lightweight threat model, we can alternatively do a comprehensive threat model to produce system-level findings. A threat model finding concretizes threat scenarios with deeper, targeted investigation, evaluates the severity and difficulty of exploitation by different possible threat actors, and concludes with tailored recommendations on how to remediate those threats.
What you get from a comprehensive threat model
In a comprehensive TRAIL threat model, we’ll continue past the endpoint of a lightweight threat model, putting our identified threat scenarios together and doing more research to ultimately present findings and finding-specific recommendations. Here are summaries of a few findings from our Linkerd engagement:
- At the time of the Linkerd engagement (in 2022), the destination service, which served routing information to sidecar proxies within a Linkerd-integrated Kubernetes cluster, lacked built-in rate limiting. This could have allowed an attacker with sidecar proxy access within one of the cluster user application namespaces to easily cause a denial of service by repeatedly requesting routing information, or to change the destination service’s availability status to force updates in the Linkerd controller component.
- We also discovered that nothing prevented infrastructure operators from using the Linkerd CLI tool to fetch YAML definitions, including sensitive information, over unencrypted HTTP. This cleartext data flow would weaken the overall security posture of an infrastructure operator’s system.
- Also at that time, the
linkerd-vizweb dashboard lacked access controls. This meant that any attacker who learned the Linkerd dashboard’s network address by simply running a scanning tool on a Linkerd-configured Kubernetes cluster could then gain detailed knowledge about the namespaces, services, pods, containers, and other resources in the cluster by accessing this dashboard, and could use this information as a basis for targeting the software running on top of the cluster.
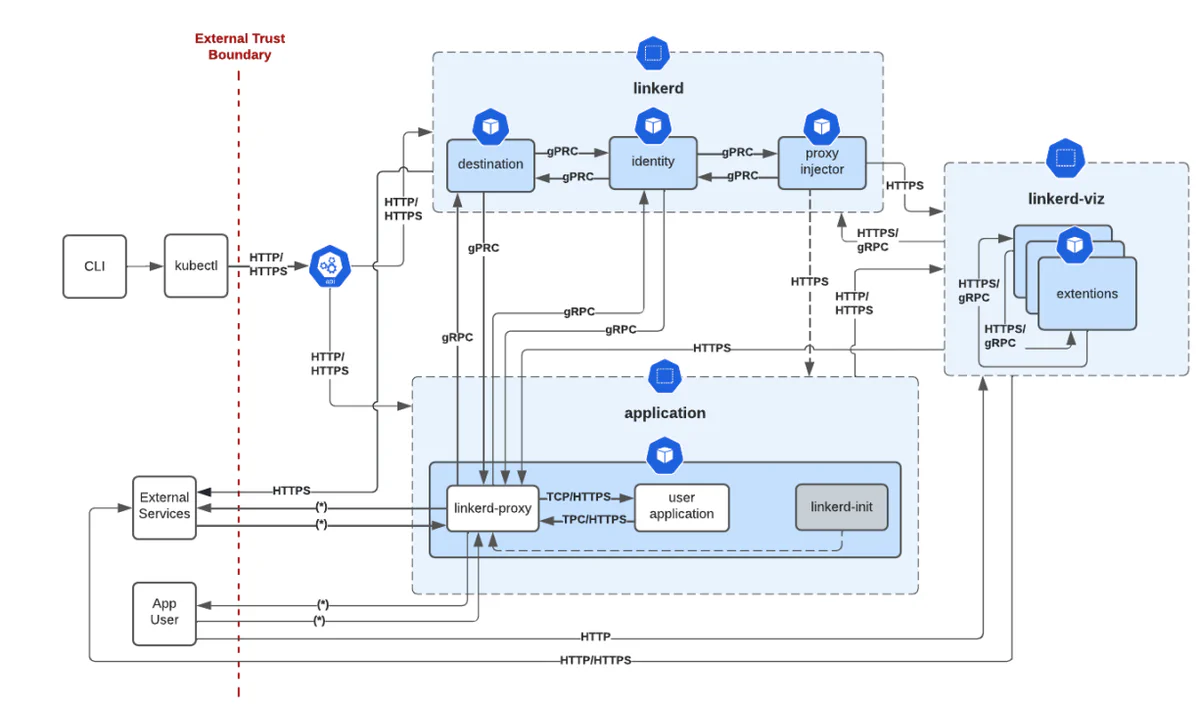
The table below includes some of the threat scenarios that we used to build the findings summarized above:
| Originating Zone | Destination Zone | Actor(s) | Description |
|---|---|---|---|
| External | User Application Namespaces | Infrastructure Operator | User applications share a pod with their sidecar proxies and respective init containers. Therefore, operators of user application infrastructure should be aware that if a user application is compromised, lateral components such as the sidecar proxy could also be compromised. This may expose routing information and certificates within the namespace. |
| External | Linkerd Namespace | Internal Attacker | An internal attacker with access to an external service that hosts an infrastructure operator’s YAML files may be able to manipulate the underlying infrastructure. |
| User Application Namespaces | linkerd-viz Namespace | Internal Attacker | Internal attackers with access restricted to the application namespace could reach Prometheus endpoints to obtain metrics data that could give them insight into other cluster components that they would not otherwise have visibility into. |
Table 2: Example threat scenarios from our 2022 Linkerd comprehensive threat model
Other comprehensive threat model reports in our Publications repo include even more threat actor paths and the findings we built with them; our reports for Curl and Kubernetes are great examples.
Applying the results
Once we’ve mapped your whole system, identified security control gaps in its design, explored potential threat scenarios together, and provided our findings and recommendations, what’s next?
Informing further security reviews
We internally use our threat models’ outcomes to provide context and direction for further Trail of Bits reviews of the same system, improving efficiency and outcomes on subsequent audits. If you are interested in both the results of a threat model and another type of security engagement we offer, why not book both engagements back-to-back with the threat model first? This retrospective blog post from 2024 on our work with OSTIF gives several excellent examples of this pairing!
Remediation
Our practice is to include short-term (immediate stopgap) and longer-term (to achieve the ideal state) mitigation suggestions for each finding in a comprehensive threat model. Where possible, we recommend several overlapping mitigations per finding, since a single mitigation could fail or be subverted by a resourceful attacker. We also include a high-level summary of our recommendations in both comprehensive and lightweight threat models.
Updating your threat model
A threat model must change as the system evolves. We provide an appendix with every report that includes directions to help you periodically modify your threat model so it remains relevant as your system’s design and requirements change over time. We’ll also discuss how and when to update your threat model in our next post!
I like how a TRAIL threat model sounds. How do I get one?
Please use our contact form to get in touch. We’d be delighted to learn about your system and your needs!
Special thanks to Stefan Edwards, Brian Glas, Alex Useche, David Pokora, Spencer Michaels, Paweł Płatek, Artem Dinaburg, Ben Samuels, and everyone else who has worked on threat modeling engagements at Trail of Bits for your awesomeness and contributions to the evolution of TRAIL.
We cover updating your threat model as your system changes and as you fix security issues in our next post! ↩︎
The SDLC is a common process flow (we hope you use it!) that organizes the work that people do while creating and maintaining a system into several life cycle phases: requirement gathering, design, development, testing, maintenance, and re-evaluation. While some associate the SDLC with Agile, using the SDLC to frame and measure the progress of your development process does not require following Agile or any other process or management framework. ↩︎
As Adam Shostack has previously said: “[Threat modeling] gives a structured, systematic, comprehensive approach to security. Structured threat-modeling techniques identify what can go wrong and provide assurance that you’re being comprehensive. Organizations get collaboration, rather than conflict, between teams.” ↩︎
We use NIST SP 800-53 security controls families to classify the findings we write up during a threat modeling assessment. This classification indicates the controls gap in the system that the finding details. You’ll see brief definitions of each security control family in our threat model reports. ↩︎
Personae non Gratae (threat actor personas) help us describe who’s in the system (legitimately or otherwise), what privileges they have, and these actors’ (ab)use cases. We write simple actor personas as an early step in the TRAIL process. ↩︎
The NIST SP 800-154 definition of an attack vector, which includes both a source component and the data that an attacker leverages to access a vulnerability in the destination component, is the basis of our threat actor path concept. ↩︎