
Trusted publishing: a new benchmark for packaging security
Read the official announcement on the PyPI blog as well!
For the past year, we’ve worked with the Python Package Index to add a new, more secure authentication method called “trusted publishing.” Trusted publishing eliminates the need for long-lived API tokens and passwords, reducing the risk of supply chain attacks and credential leaks while also streamlining release workflows. Critical packages on PyPI are already using trusted publishing to make their release processes more secure.
If you publish packages to PyPI, use the official PyPI documentation to set up trusted publishing for your projects today. The rest of this post will introduce the technical how and why of trusted publishing, as well as where we’d like to see similar techniques applied in the future.
We love to help expand trust in language ecosystems. Contact us if you’re involved in a packaging ecosystem (e.g., NPM, Go, Crates, etc) and want to adopt more of these techniques!
Trusted publishing: a primer
At its core, trusted publishing is “just” another authentication mechanism. In that sense, it’s no different from passwords or long-lived API tokens: you present some kind of proof to the index that states your identity and expected privileges; the index verifies that proof and, if valid, allows you to perform the action associated with those privileges.
What makes trusted publishing interesting is how it achieves that authentication without requiring a preexisting shared secret. Let’s get into it!
OpenID Connect and “ambient” credentials
Trusted publishing is built on top of OpenID Connect (OIDC), an open identity attestation and verification standard built on top of OAuth2. OIDC enables identity providers (IdPs) to produce publicly verifiable credentials that attest to a particular identity (like [email protected]) . These credentials are JSON Web Tokens (JWTs) under the hood, meaning that an identity under OIDC is the set of relevant claims in the JWT.
To drive that point home, here’s what a (slightly redacted) claim set might look like for a user identity presented by GitHub’s OIDC IdP:
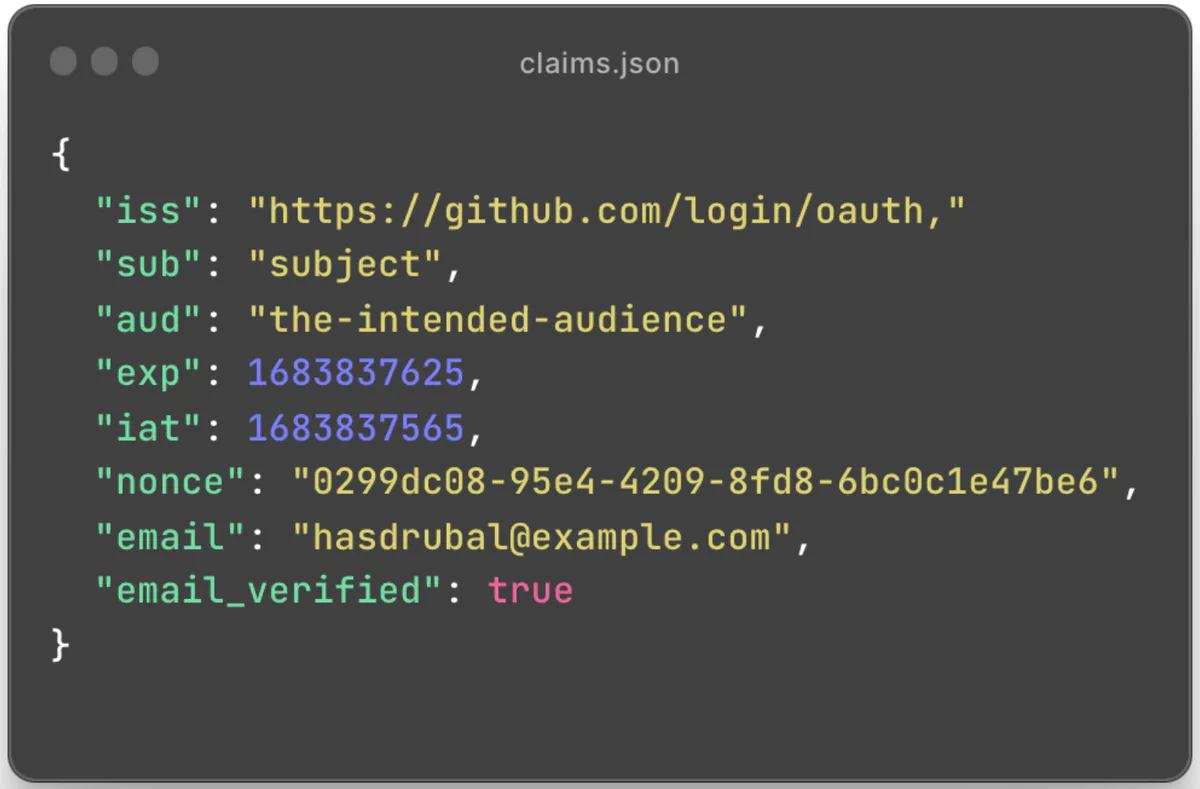
(In an actual JWT, this claim set would be accompanied by a digital signature proving its authenticity for a trusted signing key held by the IdP. Without that digital signature, we’d have no reason to trust the claims!)
Anybody can be an IdP in an OpenID Connect scheme. Still, a large part of the practical value of OIDC is derived from interactions with large, presumed-to-be-trustworthy-and-well-secured IdPs. There’s value in proving ownership over things like GitHub and Google accounts, particularly for things like SSO and service federation.
So far, so good, but none of this is especially relevant to packaging indices like PyPI. PyPI could allow users to sign in with OIDC rather than passwords, but it’s unclear how that would make publishing workflows, particularly CI-based ones, any more convenient.
What makes OIDC useful to package indices like PyPI is the observation that an OIDC identity doesn’t need to be a human: it can be a machine identifier, a source repository, or even a specific instance of a CI run. Moreover, it doesn’t need to be obtained through an interactive OAuth2 flow: it can be offered “ambiently” as an object or resource that only the identity (machine, etc.) can access.
CI providers figured this out not too long ago: GitHub Actions added support for ambient OIDC credentials in late 2021, while GitLab added it just a few months ago. Here’s what retrieving one of those credentials looks like on GitHub Actions:

And here’s what the (again, filtered) claim set for a GitHub Actions workflow run might look like:
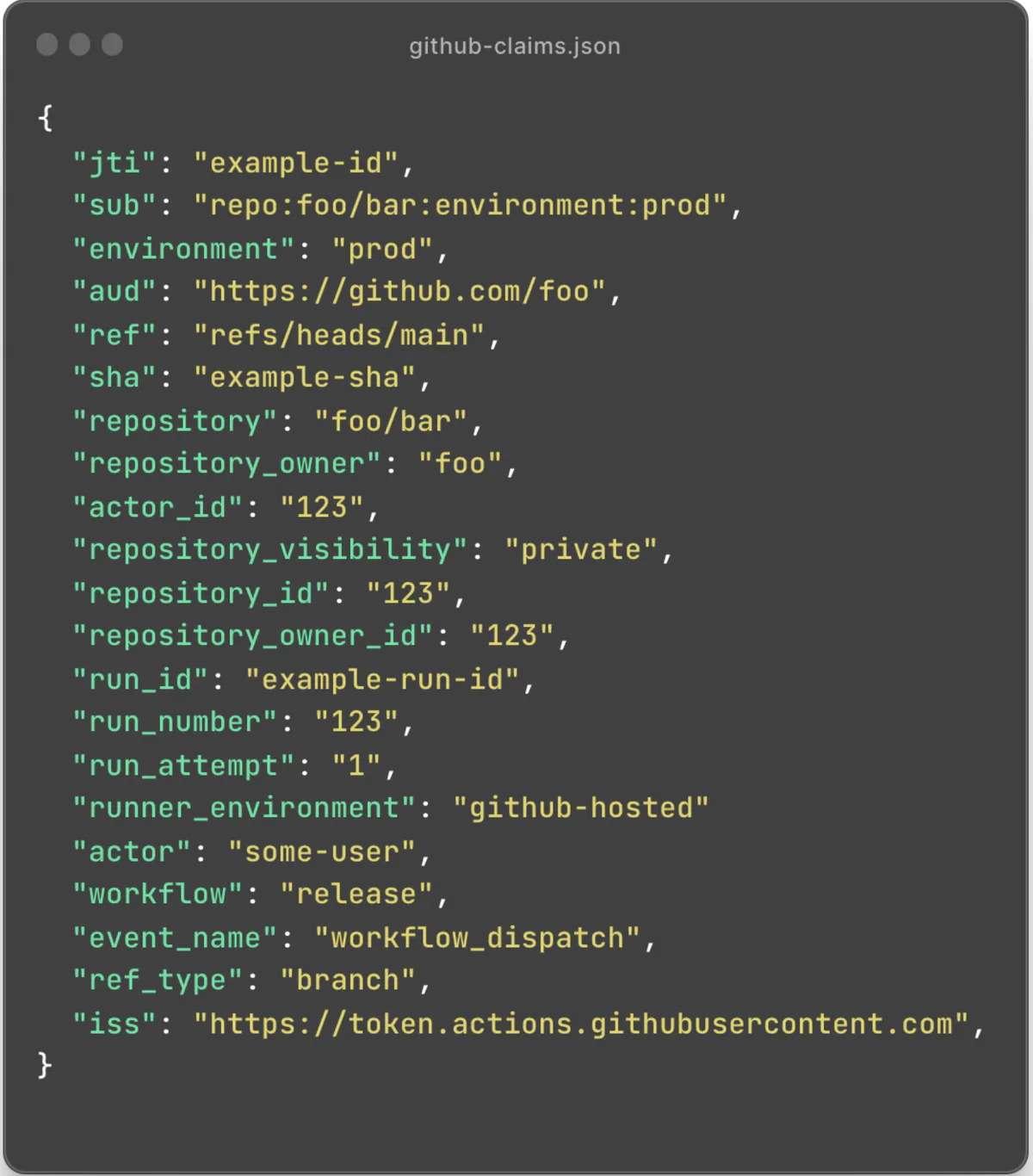
This is a lot of context to work with: assuming that we trust the IdP and that the signature checks out, we can verify the identity down to the exact GitHub repository, the workflow that ran, the user that triggered the workflow, and so forth. Each of these can, in turn, become a constraint in an authentication system.
Trust is everything
To recap: OpenID Connect gives us the context and machinery we need to verify proofs of identity (in the form of OIDC tokens) originating from an IdP. The identities in these proofs can be anything, including the identity of a GitHub Actions workflow in a particular repository.
Any third-party service (like PyPI) can, in turn, accept OIDC tokens and determine a set of permissions based on them. Because OIDC tokens are cryptographically tied to a particular OIDC IdP’s public key, an attacker cannot spoof an OIDC token, even if they know the claims within it.
But wait a second: how do we get from an OIDC token containing an identity to a specific PyPI project? How do we know which PyPI project(s) should trust which OIDC identity or identities?
This is where a bit of trusted setup is required: a user (on PyPI) has to log in and configure the trust relationship between each project and the publishers (i.e., the OIDC identities) that are authorized to publish on behalf of the project.
This needs to be done only once, as with a normal API token. Unlike an API token, however, it only involves one party: the CI (and OIDC) provider doesn’t need to be given a token or any other secret material. Moreover, even the trusted setup part is composed of completely public information: it’s just the set of claim values that the user considers trustworthy for publishing purposes. For GitHub Actions publishing to PyPI, the trusted setup would include the following:
- The GitHub user/repo slug
- The filename of the GitHub Actions workflow that’s doing the publishing (e.g., release.yml)
- Optionally, the name of a GitHub Actions environment that the workflow uses (e.g., release)
Together, these states allow the relying party (e.g., PyPI) to accept OIDC tokens, confirm that they’re signed by a trusted identity provider (e.g., GitHub Actions), and then match the signed claims against one or more PyPI projects that have established trust in those claims.
Look ma, no secrets
At this point, we have everything we need to allow an identity verified via OIDC to publish to PyPI. Here’s what that looks like in the GitHub case:
- A developer (or automation) triggers a GitHub Actions workflow to release to PyPI.
- The normal build process (python -m build or similar) commences.
- Automation retrieves an OIDC token for the current workflow run, attesting to the current workflow’s identity (user/repo, workflow name, environment, etc.) via GitHub Actions’ OIDC IdP.
- That OIDC token is shot over to PyPI.
- If valid, PyPI verifies it and exchanges it for a short-lived PyPI API token that’s scoped to just the PyPI projects that trust those token claims.
- PyPI returns the short-lived API token as a response to the OIDC token.
- The workflow continues, performing a normal PyPI publish step (e.g., with twine) with the short-lived API token.
For 99% of package publishers, steps 3 through 7 are entirely implementation details: the official PyPA GitHub Action for publishing to PyPI encapsulates them, making the user-facing piece just this:
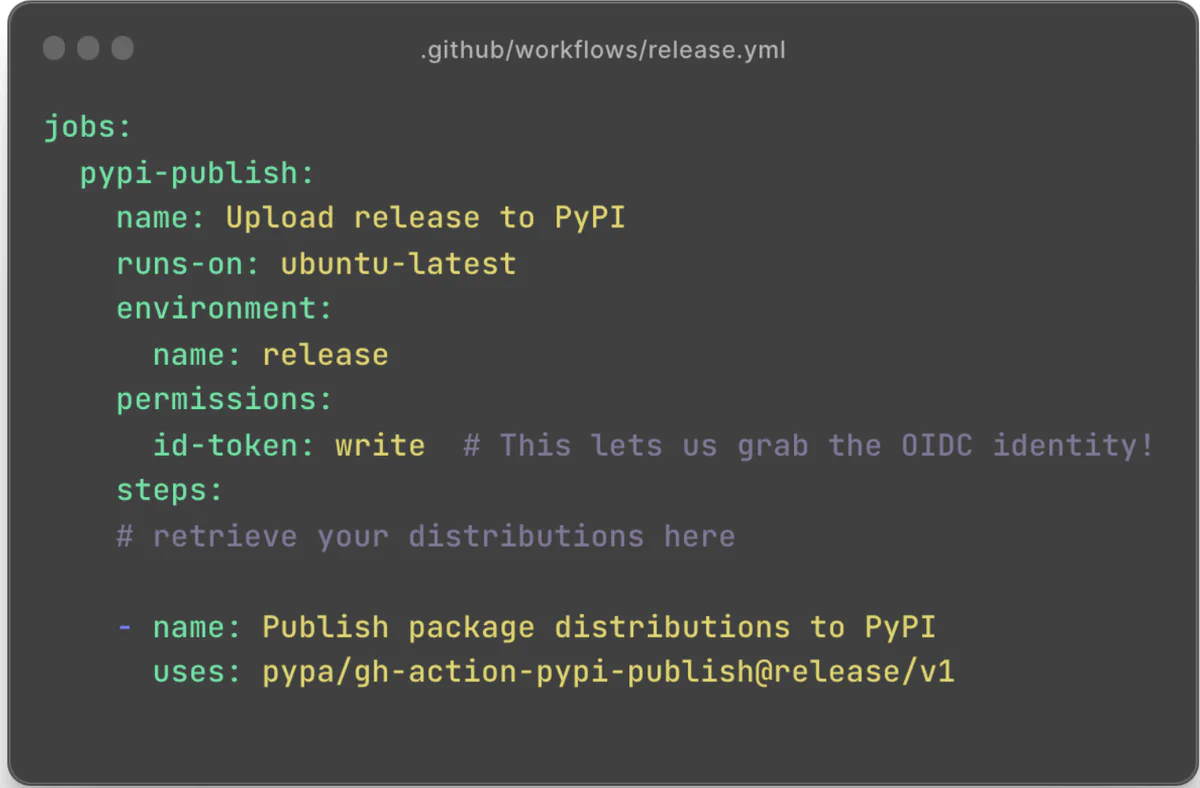
Why should I care?
At this point, you might reasonably think:
I’m a competent engineer, and I already do everything right. My tokens are correctly scoped to the smallest permissions required, they’re stored as workflow (or per-environment) secrets, and I carefully audit my release workflows to ensure that all third-party code is trustworthy." – You, a competent engineer
Here’s the thing: you’ve been doing everything right! Until now, the most secure way to authenticate to PyPI was to do the following:
- Create a project-scoped API token.
- Store it as a (scoped) secret in your CI.
- Access it carefully in a publishing workflow you’ve reviewed and established trust in.
This suffices for many use cases but also leaves a great deal to be desired from both the usability and security perspectives:
- Usability. Manually managing and creating API tokens is tedious, especially in scenarios where a single source repository hosts multiple PyPI packages: each needs its own separately scoped token, a unique secret name, and so forth. You and your fellow engineers have better ways to spend your time!
- Pre-compromise security. Not all attackers are born equal: some are passive, some are active, some might be able to compromise only a specific step in your publishing process, and so forth. Reducing the power of (or outright eliminating) one of these attackers is useful, even when the mitigation involved doesn’t meaningfully impact other attackers. Unfortunately, doing so with long-lived tokens is difficult: a long-lived token is equally susceptible to any attacker who gets access for any time.
- Post-compromise recovery. Designing for security means attempting to thwart attackers and preparing for and mitigating the risk posed by a successful attacker. With long-lived credentials (either passwords or API tokens), this is slow, tedious, and error-prone: missing a single credential leaves a gap for the attacker to return. A better system wouldn’t have this problem to begin with.
Trusted publishing addresses these problems and more:
Usability. With a trusted publisher, no manual API token management is necessary: configuring the publisher is a one-time action for each project, including for projects that haven’t been created yet.
This avoids the annoying API token dance involved when publishing a brand new project and the game of “credential hot potato” that engineers play when trying to hand an API token to the party responsible for adding it to the CI’s secrets. No more Slack DMs with API tokens!
Pre-compromise security. Trusted publishing reduces the number of adversaries: an attacker with access to only some GitHub Actions environments or particular (non-permission) steps can’t mint the OIDC credential needed to use the trusted publisher. This is in marked contrast to a long-lived token stored in a GitHub Actions secret, where any step (and frequently any environment) can access the credential!
Post-compromise recovery. Trusted publishing is fundamentally ephemeral: the credentials involved (both the OIDC and PyPI credentials) live for only a few minutes at a time, meaning that an attacker who loses access during post-compromise response is automatically sealed off without any human intervention. That means fewer manual steps and fewer possible human errors.
Security and threat model considerations
Trusted publishing is another way to securely authenticate to a package index. Like every security feature, it must be designed and implemented to a threat model. That threat model must justify trusted publishing’s existence, both for addressing attackers that previous authentication methods do not address and for new attack scenarios it exposes.
Existing threats: account takeover and supply chain attacks
Account takeover (ATO) is a known problem in packaging ecosystems: an attacker who manages to compromise a legitimate user’s PyPI or GitHub account can upload malicious releases (or even override previous ones) without any outward indication of inauthenticity.
In the general case, ATO is an unsolvable problem: services like PyPI and GitHub can improve access to security features (and even mandate those features) but fundamentally cannot prevent a user from disclosing their credentials (e.g., via phishing), much less protect them from every piece of potentially vulnerable software they use.
At the same time, features like trusted publishing can reduce the scope of account takeover: a future in which package indices allow packages to opt in to only trusted publishing is one where an ATO on the package index itself doesn’t allow the attacker to upload malicious releases.
Similarly, “supply chain security” is all the rage these days: companies and hobbyists alike are taking a second look at out-of-control dependency trees and their frequently unaccountable and untraceable components.
Without trusted publishing, the status quo for GitHub Actions is that you trust every third-party action you execute: they can all read your configured secrets. This is extremely non-ideal and is one of the key attack models trusted publishing intends to secure against.
New threats: “account resurrection” and malicious committers
Trusted publishing works because it’s tied to a notion of “trusted identity”: the trusted identity on the other side (e.g., on GitHub Actions) is a tuple of user/repo, workflow name, and an optional environment name.
But wait: what happens if a user changes their username and an attacker takes over their old username? We call this “account resurrection,” and it’s explicitly supported by most services: a username isn’t intended to be a permanent, stable identifier for the underlying identity.
This opens up an entirely new attack vector: a PyPI project that trusts hamilcar/cartago might suddenly begin trusting an attacker-controlled hamilcar/cartago, all because the original hamilcar is now hannibal (and the legitimate hamilcar/cartago is now hannibal/cartago).
We thought of this while designing trusted publishing for PyPI and worked with GitHub to add an additional claim that binds the OIDC token not just to the user, but also to their unique, stable user ID. This gives us the state we need to prevent resurrection attacks: even if an attacker manages to become hamilcar on GitHub, their underlying user ID will not change and PyPI will reject any identity tokens they present.
Trusted publishing also reveals a new (potential) division in a project’s trust model: for any given project, do you trust every member of that project to also be a potential publisher? In many cases, the answer is yes: many projects have only one or two repository members, both of whom are also owners or otherwise privileged on the package index.
In some cases, however, the answer is no: many projects have dozens of low-activity or inactive members, not all of whom may be following best practices for securing their accounts. These members might not be removable because of community policy or because they need access for infrequent (but critical) project activities. These users should not necessarily receive the ability to publish releases to the packaging index just because they have the commit bit on the repository.
This is also a consideration we made while designing trusted publishing, and it’s why PyPI’s implementation supports an optional GitHub Actions environment: for communities where users who commit and users who publish do not wholly overlap, an environment can be used to impose additional workflow restrictions that are reflected (and subsequently honored by PyPI) in the OIDC token. A detailed example of this is given in PyPI’s own security model documentation.
Coming to a package index near you
Our work on PyPI was funded by the incredible Google Open Source Security Team (GOSST), who we’ve also worked with to develop new tooling for the Python ecosystem’s overall security. In particular, we’d like to thank Dustin Ingram for tirelessly working alongside us and directing the overall pace and design of trusted publishing for PyPI.
At the moment, PyPI is the only package index offering trusted publishing that we’re aware of. That being said, nothing about trusted publishing is unique to Python or Python packaging: it could just as easily be adopted by Rust’s Crates, Ruby’s RubyGems, JavaScript’s NPM, or any other ecosystem where publishing from a third-party service is common (like GitHub Actions or GitLab’s CI/CD).
It’s our opinion that, much like Two-Factor Authentication in 2019, this kind of trusted publishing scheme will become instrumental to the security model of open-source packaging. We see it as a building block for all kinds of subsequent improvements, including being able to generate strong cryptographic proof that a PyPI release was built from a particular source artifact.
If you or your company are interested in this work, please get in touch with us! We have years of experience working on security features in open-source ecosystems and are always looking for more ways to contribute to critical open-source projects and services.