
cURL audit: How a joke led to significant findings
In fall 2022, Trail of Bits audited cURL, a widely-used command-line utility that transfers data between a server and supports various protocols. The project coincided with a Trail of Bits maker week, which meant that we had more manpower than we usually do, allowing us to take a nonstandard approach to the audit.
While discussing the threat model of the application, one of our team members jokingly asked, “Have we tried curl AAAAAAAAAA… yet”? Although the comment was made in jest, it sparked an idea: we should fuzz cURL’s command-line interface (CLI). Once we did so, the fuzzer quickly uncovered memory corruption bugs, specifically use-after-free issues, double-free issues, and memory leaks. Because the bugs are in libcurl, a cURL development library, they have the potential to affect the many software applications that use libcurl. This blog post describes how we found the following vulnerabilities:
- CVE-2022-42915 – Double free when using HTTP proxy with specific protocols. Fixed in cURL 7.86.0
- CVE-2022-43552 – Use-after-free when HTTP proxy denies tunneling SMB/TELNET protocols. Fixed in cURL 7.87.0
- TOB-CURL-10 – Use-after-free while using parallel option and sequences. Fixed in cURL 7.86.0
- TOB-CURL-11 – Unused memory blocks are not freed, resulting in memory leaks. Fixed in cURL 7.87.0
Working with cURL
cURL is continuously fuzzed by the OSS-Fuzz project, and its harnesses are developed in the separate curl-fuzzer GitHub repository. When I consulted the curl-fuzzer repository to check out the current state of cURL fuzzing, I noticed that cURL’s command-line interface (CLI) arguments are not fuzzed. With that in mind, I decided to focus on testing cURL’s handling of arguments. I used the AFL++ fuzzer (a fork of AFL) to generate a large amount of random input data for cURL’s CLI. I compiled cURL using collision-free instrumentation at link time with AddressSanitizer and then analyzed crashes that could indicate a bug.
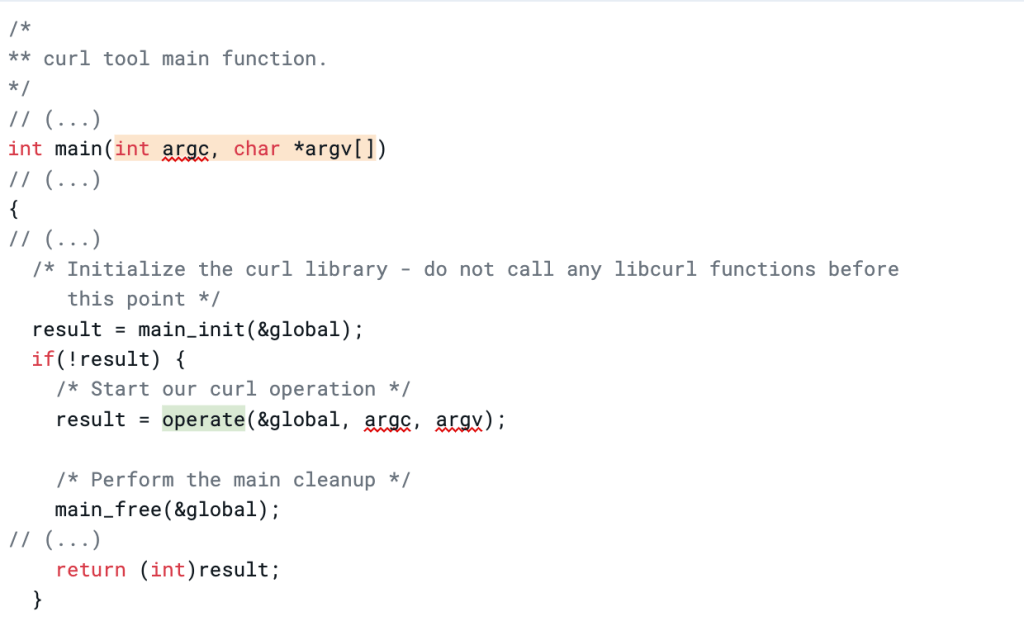
cURL obtains its options through command-line arguments. As cURL follows the C89 standard, the main() function of a program can be defined with no parameters or with two parameters (argc and argv). The argc argument represents the number of command-line arguments passed to the program (which includes the program’s name). The argv argument is an array of pointers to the arguments passed to the program from the command line.
The standard also states that in a hosted environment, the main() function takes a third argument, char *envp[]; this argument points to a null-terminated array of pointers to char, each of which points to a string with information about the program’s environment.
The three parameters can have any name, as they are local to the function in which they are declared.
cURL’s main() function in the curl/src/tool_main.c file passes the command-line arguments to the operate() function, which parses them and sets up the global configuration of cURL. cURL then uses that global configuration to execute the operations.
Fuzzing argv
When I started the process of attempting to fuzz cURL, I looked for a way to use AFL to fuzz its argument parsing. My search led me to a quote from the creator of AFL (Michal Zalewski):
“AFL doesn’t support argv fuzzing because TBH, it’s just not horribly useful in practice. There is an example in experimental/argv_fuzzing/ showing how to do it in a general case if you really want to.”
I looked at that experimental AFL feature and its equivalent in AFL++. The argv fuzzing feature makes it possible to fuzz arguments passed to a program from the CLI, instead of through standard input. That can be useful when you want to cover multiple APIs of a library in fuzz testing, as you can fuzz the arguments of a tool that uses the library rather than writing multiple fuzz tests for each API.
How does the AFL++ argvfuzz feature work?
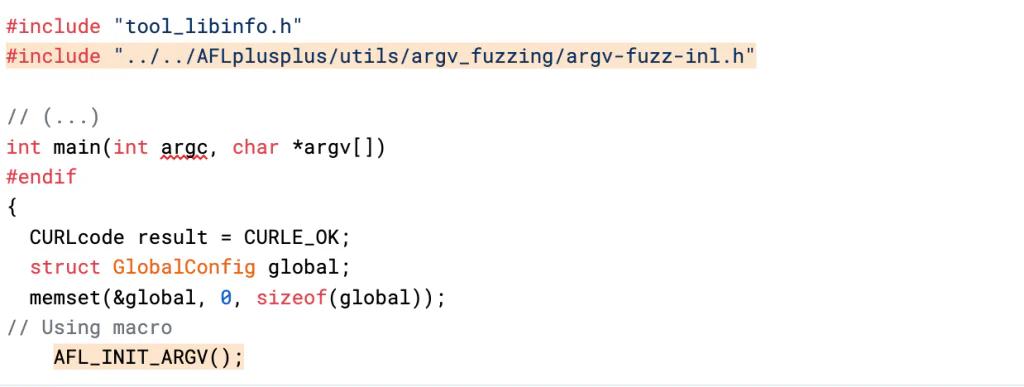
The argv-fuzz-inl.h header file of argvfuzz defines two macros that take input from the fuzzer and set up argv and argc:
- The
AFL_INIT_ARGV()macro initializes theargvarray with the arguments passed to the program from the command line. It then reads the arguments from standard input and puts them in theargvarray. The array is terminated by twoNULLcharacters, and any empty parameter is encoded as a lone0x02character. - The
AFL_INIT_SET0(_p)macro is similar toAFL_INIT_ARGV()but also sets the first element of theargvarray to the value passed to it. This macro can be useful if you want to preserve the program’s name in theargvarray.
Both macros rely on the afl_init_argv() function, which is responsible for reading a command line from standard input (by using the read() function in the unistd.h header file) and splitting it into arguments. The function then stores the resulting array of strings in a static buffer and returns a pointer to that buffer. It also sets the value pointed to by the argc argument to the number of arguments that were read.
To use the argv-fuzz feature, you need to include the argv-fuzz-inl.h header file in the file that contains the main() function and add a call to either AFL_INIT_ARGV or AFL_INIT_SET0 at the beginning of main(), as shown below:
Preparing a dictionary
A fuzzing dictionary file specifies the data elements that a fuzzing engine should focus on during testing. The fuzzing engine adjusts its mutation strategies so that it will process the tokens in the dictionary. In the case of cURL fuzzing, a fuzzing dictionary can help afl-fuzz more effectively generate valid test cases that contain options (which start with one or two dashes).
To fuzz cURL, I used the afl-clang-lto compiler’s autodictionary feature, which automatically generates a dictionary during compilation of the target binary. This dictionary is transferred to afl-fuzz on startup, improving its coverage. I also prepared a custom dictionary based on the cURL manpage and passed it to afl-fuzz via the -x parameter. I used the following Bash command to prepare the dictionary:
man curl | grep -oP '^\s*(--|-)\K\S+' | sed 's/[,.]$//' | sed 's/^/"&/; s/$/&"/' | sort -u > curl.dictSetting up a service for cURL connections
Initially, my focus was solely on CLI fuzzing. Still, I had to consider that each valid cURL command generated by the fuzzer would likely result in a connection to a remote service. To avoid connecting to those services but maintain the ability to test the code responsible for handling connections, I used the netcat tool as a simulation of remote service. First, I configured my machine to redirect outgoing traffic to netcat’s listening port.
I used the following command to run netcat in the background:
netcat -l 80 -k -w 0 &The parameters indicate that the service should listen for incoming connections on port 80 (-l 80), continue to listen for additional connections after the current one is closed (-k), and immediately terminate the connection once it has been established (-w 0).
cURL is expected to connect to services using various hostnames, IP addresses, and ports. I needed to forward them to one place: a previously created TCP port 80.
To redirect all outgoing TCP packets to the local loopback address (127.0.0.1) on port 80, I used the following iptables rule:
iptables -t nat -A OUTPUT -p tcp -j REDIRECT --to-port 80The command adds a new entry to the network address translation table in iptables. The -p option specifies the protocol (in this case, TCP), and the -j option specifies the rule’s target (in this case, REDIRECT). The --to-port option specifies the port to which the packets will be redirected (in this case, 80).
To ensure that all domain names would be resolved to IP address 127.0.0.1, I used the following iptables rule:
iptables -t nat -A OUTPUT -p udp --dport 53 -j DNAT --to-destination 127.0.0.1This rule adds a new entry to the NAT table, specifying the protocol (-p) as UDP, the destination port (--dport) as 53 (the default port for DNS), and the target (-j) as destination NAT. The --to-destination option specifies the address to which the packets will be redirected (in this case, 127.0.0.1).
The abovementioned setup ensures that every cURL connection is directed to the address 127.0.0.1:80.
Results analysis
The fuzzing process ran for a month on a 32-core machine with an Intel Xeon Platinum 8280 CPU @ 2.70GHz. The following bugs were identified during that time, most of them in the first few hours of fuzzing:
CVE-2022-42915 (Double free when using HTTP proxy with specific protocols)
Using cURL with proxy connection and dict, gopher, LDAP, or telnet protocol triggers a double-free vulnerability due to flaws in the error/cleanup handling. This issue is fixed in cURL 7.86.0.
To reproduce the bug, use the following command:
curl -x 0:80 dict://0CVE-2022-43552 (Use after free when HTTP proxy denies tunneling SMB/TELNET protocols)
cURL can virtually tunnel supported protocols through an HTTP proxy. If an HTTP proxy blocks SMB or TELNET protocols, cURL may use a struct that has already been freed in its transfer shutdown code. This issue is fixed in cURL 7.87.0.
To reproduce the bug, use the following commands:
curl 0 -x0:80 telnet:/[j-u][j-u]//0 -m 01
curl 0 -x0:80 smb:/[j-u][j-u]//0 -m 01TOB-CURL-10 (Use after free while using parallel option and sequences)
A use-after-free vulnerability can be triggered by using cURL with the parallel option (-Z), an unmatched bracket, and two consecutive sequences that create 51 hosts. cURL allocates memory blocks for error buffers, allowing up to 50 transfers by default. In the function responsible for handling errors, errors are copied to the appropriate error buffer when connections fail, and the memory is then freed. For the last (51) sequence, a memory buffer is allocated, freed, and an error is copied to the previously freed memory buffer. This issue is fixed in cURL 7.86.0.
To reproduce the bug, use the following command:
curl 0 -Z [q-u][u-~] }TOB-CURL-11 (Unused memory blocks are not freed, resulting in memory leaks)
cURL allocates blocks of memory that are not freed when they are no longer needed, leading to memory leaks. This issue is fixed in cURL 7.87.0.
To reproduce the bug, use the following commands:
curl 0 -Z 0 -Tz 0
curl 00 --cu 00
curl --proto =0 --proto =0Dockerfile
If you want to learn about the full process of setting up a fuzzing harness and immediately begin fuzzing cURL’s CLI arguments, we have prepared a Dockerfile for you:
# syntax=docker/dockerfile:1
FROM aflplusplus/aflplusplus:4.05c
RUN apt-get update && apt-get install -y libssl-dev netcat iptables groff
# Clone a curl repository
RUN git clone https://github.com/curl/curl.git && cd curl && git checkout 2ca0530a4d4bd1e1ccb9c876e954d8dc9a87da4a
# Apply a patch to use afl++ argv fuzzing feature
COPY <<-EOT /AFLplusplus/curl/curl_argv_fuzz.patch
diff --git a/src/tool_main.c b/src/tool_main.c
--- a/src/tool_main.c
+++ b/src/tool_main.c
@@ -54,6 +54,7 @@
#include "tool_vms.h"
#include "tool_main.h"
#include "tool_libinfo.h"
+#include "../../AFLplusplus/utils/argv_fuzzing/argv-fuzz-inl.h"
/*
* This is low-level hard-hacking memory leak tracking and similar. Using
@@ -246,6 +247,8 @@ int main(int argc, char *argv[])
struct GlobalConfig global;
memset(&global, 0, sizeof(global));
+ AFL_INIT_ARGV();
+
#ifdef WIN32
/* Undocumented diagnostic option to list the full paths of all loaded
modules. This is purposely pre-init. */
EOT
# Apply a patch to use afl++ argv fuzzing feature
RUN cd curl && git apply curl_argv_fuzz.patch
# Compile a curl using collision-free instrumentation at link time and ASAN
RUN cd curl && \
autoreconf -i && \
CC="afl-clang-lto" CFLAGS="-fsanitize=address -g" ./configure --with-openssl --disable-shared && \
make -j $(nproc) && \
make install
# Download a dictionary
RUN wget
https://gist.githubusercontent.com/ahpaleus/f94eca6b29ca8824cf6e5a160379612b/raw/3de91b2dfc5ddd8b4b2357b0eb7fbcdc257384c4/curl.dict
COPY <<-EOT script.sh
#!/bin/bash
# Running a netcat listener on port tcp port 80 in the background
netcat -l 80 -k -w 0 &
# Prepare iptables entries
iptables-legacy -t nat -A OUTPUT -p tcp -j REDIRECT --to-port 80
iptables-legacy -t nat -A OUTPUT -p udp --dport 53 -j DNAT --to-destination 127.0.0.1
# Prepare fuzzing directories
mkdir fuzz &&
cd fuzz &&
mkdir in out &&
echo -ne 'curl\x00http://127.0.0.1:80' > in/example_command.txt &&
# Run afl++ fuzzer
afl-fuzz -x /AFLplusplus/curl.dict -i in/ -o out/ -- curl
EOT
RUN chmod +x ./script.sh
ENTRYPOINT ["./script.sh"]Use the following commands to run this file:
docker buildx build -t curl_fuzz .
docker run --rm -it --cap-add=NET_ADMIN curl_fuzzAll joking aside
In summary, our approach demonstrates that fuzzing CLI can be an effective supplementary technique for identifying vulnerabilities in software. Despite initial skepticism, our results yielded valuable insights. We believe this has improved the security of CLI-based tools, even when OSS-Fuzz has been used for many years.
It is possible to find a heap-based memory corruption vulnerability in the cURL cleanup process. However, use-after-free vulnerability may not be exploitable unless the freed data is used in the appropriate way and the data content is controlled. A double-free vulnerability would require further allocations of similar size and control over the stored data. Additionally, because the vulnerability is in libcurl, it can impact many different software applications that use libcurl in various ways, such as sending multiple requests or setting and cleaning up library resources within a single process.
It is also worth noting that although the attack surface for CLI exploitation is relatively limited, if an affected tool is a SUID binary, exploitation can result in privilege escalation (see CVE-2021-3156: Heap-Based Buffer Overflow in sudo).
To enhance the efficiency of fuzz testing similar tools in the future, we have extended the argv_fuzz feature in AFL++ by incorporating a persistent fuzzing mode. Learn more about our AFL++ pull request.
Finally, our cURL audit reports are public. Check the audit report and the threat model.