
Fast and accurate syntax searching for C and C++
The naive approach to searching for patterns in source code is to use regular expressions; a better way is to parse the code with a custom parser, but both of these approaches have limitations. During my internship, I prototyped an internal tool called Syntex that does searching on Clang ASTs to avoid these limitations. In this post, I’ll discuss Syntex’s unique approach to syntactic pattern matching.
Searching, but with context
Syntex addresses two overarching problems with traditional pattern-searching tools.
First, existing tools are prone to producing false negatives. These tools usually contain their own parsers that they use depending on the language of the codebase they are searching in. For C and C++ codebases, these tools usually parse source code without performing macro expansion, searching through non-macro-expanded code instead of the macro-expanded code that a real compiler like Clang would produce. This means these tools cannot ensure accurate results. A client of such a tool won’t be able to confidently say, “here are all the occurrences of this pattern” or “this pattern never occurs.” In theory, these tools could match uses of macros in non-macro-expanded code, but in practice, they would be able to match only top-level uses of macros, meaning that false negatives are likely.
Another problem with these tools is that their internal parsers do not use the same representation of the code as a real compiler would, and they do not have an understanding of the semantics of the source code. That is, these tools produce plaintext output highlighting their results, so they cannot provide semantic information about the code in which their results appear. Without such information, it is difficult to further analyze the output, especially using other analysis tools. It is not strictly speaking impossible to access the source code internally parsed by these tools, but it would not be particularly useful in a multi-stage analysis pipeline requiring access to semantic information available only to a compiler. All this severely limits these tools’ usefulness as a foundation on which to use other analysis tools to more deeply analyze the given code.
For instance, let’s say we are trying to find code in which the length of a string in the argument list of a call to some risky function is implicitly truncated. We might have our tool search for the pattern $func($... $str->len $...). The tool will likely find a superset of code snippets that we actually care about. We ought to be able to semantically filter these search results to check that len is the structure field of interest and that its use induces an implicit downcast. However, whatever tool we choose to use would not be able to do this filtering because it would understand only the structure of the code, not the semantics. And because of its lack of semantic understanding, it’s more difficult to introduce other analysis tools to help further analyze the results.
Syntex solves both of these problems by operating on actual Clang ASTs. Because Syntex uses the same ASTs that the compiler uses, it eliminates the inaccuracies of typical pattern-searching tools and provides semantic information for further analysis. Syntex produces results with references to AST nodes, allowing developers to conduct follow-up semantic analysis. For instance, a client enumerating the downcast pattern above will be able to make decisions based on the type and nature of the submatches corresponding to both func and str.
Syntex matches syntax patterns against indexed code
Parsing C and C++ code is a notoriously difficult task, in that it requires implementing unbounded lookaheads and executing Turing-complete templates just to obtain a parse tree. Syntex solves the problem of parsing source code by relying on Clang, but how does it parse Syntex queries themselves?
Aside from queries containing $-prefixed meta variables, Syntex queries are syntactically valid C and C++ code. Ideally, we would parse Syntex queries with Clang, then unify the parsed queries and parsed source code to identify matches. Unfortunately, life is not so easy: Syntex queries lack the necessary syntactic/semantic context that would allow them to be parsed. For example, the pattern foo(0) yields different parse trees depending on the type of foo.
Syntex doesn’t directly resolve the edge cases of C and C++ syntax; instead, it considers all possible ambiguous interpretations while parsing queries. However, instead of defining the ambiguous language patterns itself, Syntex derives its pattern grammar from the Clang compiler’s AST. Using this approach, we can guarantee that patterns will be accepted for every construct appearing in the indexed source code.
Synthesizing the grammar
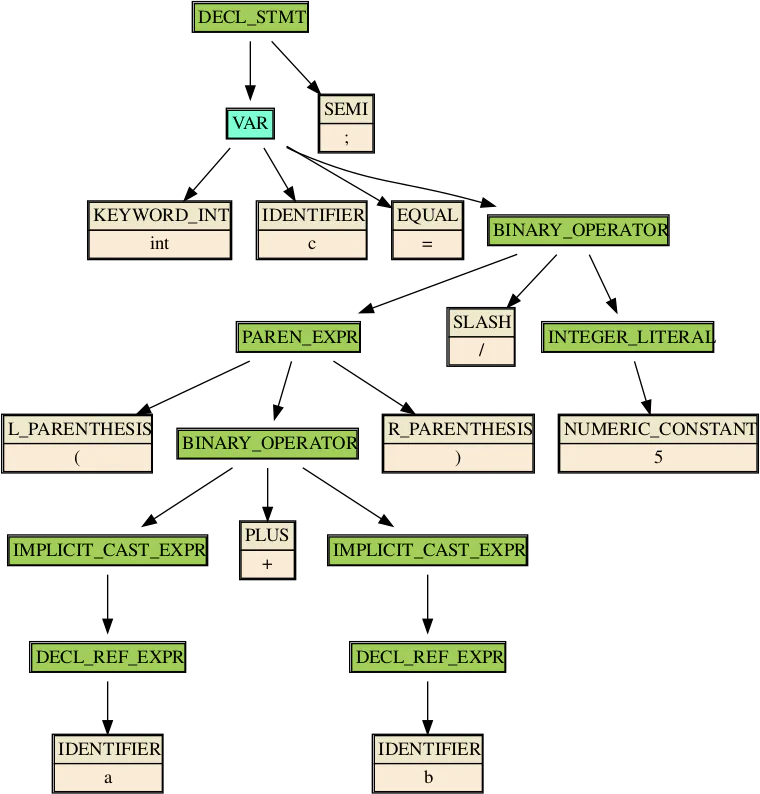
At code building and indexing time, Syntex creates a context-free grammar by recursively walking through the Clang AST and recording the relationships between AST nodes. Nodes with children correspond to non-terminals; each appearance of such a node adds a production rule of the form parent -> child_0 ... child_n. Nodes with no children become terminal symbols in the generated grammar. For instance, the grammar (production rules and terminals) corresponding to the AST in figure 1 is as follows:
DECL_REF_EXPR -> IDENTIFIER
INTEGER_LITERAL -> NUMERIC_CONSTANT
IMPLICIT_CAST_EXPR -> DECL_REF_EXPR
BINARY_OPERATOR -> IMPLICIT_CAST_EXPR PLUS IMPLICIT_CAST_EXPR
PARENT_EXPR -> L_PARENTHESIS BINARY_OPERATOR R_PARENTHESIS
BINARY_OPERATOR -> PAREN_EXPR SLASH INTEGER_LITERAL
VAR -> KEYWORD_INT IDENTIFIER EQUAL BINARY_OPERATOR
DECL_STMT -> VAR SEMI
IDENTIFIER, NUMERIC_CONSTANT, PLUS, L_PARENTHESIS, R_PARENTHESIS, SLASH,
KEYWORD_INT, EQUAL, SEMIIf we interpret DECL_STMT as the “start symbol” of this grammar, then the grammar is deterministic, and a parser that accepts strings could be generated with the commonly used LR algorithm. However, when parsing search queries, Syntex doesn’t actually know the start symbol that the query should reduce to. For example, if the query consists of an IDENTIFIER token, then Syntex can parse that token as an IDENTIFIER, a DECL_REF_EXPR containing an identifier, or an IMPLICIT_CAST_EXPR containing a DECL_REF_EXPR containing an identifier. This means that, in practice, Syntex assumes that every symbol could be a start symbol and retroactively deduces which rules are start rules based on whether they cover the entire input query.
Parsing Syntex queries
Conceptually, the first step in parsing a query is to perform tokenization (or lexical analysis). Syntex performs tokenization using a hand-coded state machine. One difference between Syntax’s tokenizer and those used in typical compilers is that Syntex’s tokenizer returns all possible interpretations of the input characters instead of just the greediest interpretation. For example, Syntex would tokenize the string ”<<“ as both << and two < symbols following each other. That way, the tokenizer doesn’t have to be aware of which interpretation is necessary in which context.
Syntex parses queries against synthetic pattern grammars using a memoizing chart parser. Memoization prevents the parsing process from resulting in (potentially) exponential runtime complexity, and the resulting memo table serves as the in-memory representation of a query parse forest. The matcher (described in the next section) uses this table to figure out which indexed ASTs match the query. This approach means that Syntex doesn’t have to materialize explicit trees for each possible interpretation of a query. Figure 2 presents a memoization table for the query string “++i”.

This table shows that the string at index 0 can be interpreted as the tokens + or ++ and that the production rule UNARY_OPERATOR -> PLUS_PLUS DECL_REF_EXPR is matched at this index. To obtain that match, the parser, after seeing that the left corner of the production above can match PLUS_PLUS, recursively obtains the parses at index 2. With this knowledge, it can enumerate the production forward and conclude that it matches in its entirety up until index 3.
Finding matches
After the parse table of a query is filled, Syntex needs to locate appearances of all interpretations of the query in the indexed source code. This process starts with all entries in the table at index 0 whose next index is the length of the input; these entries correspond to parses covering the entire input string.
Syntex’s matching algorithm operates on a proprietary Clang AST serialization format. Serialized ASTs are deserialized into in-memory trees. The deserialization process builds an index of tree node types (corresponding to grammar symbols) to deserialized nodes, which enables Syntex to quickly discover candidates that could match against a query’s root grammar symbol. A recursive unification algorithm is applied pairwise to each match candidate and each possible parse of the query. The algorithm descends the trees, checking node types and the order in which they appear, and bottoms out at the actual tokens themselves.
For the query “++i” in figure 2, Syntex starts matching at an AST node with the symbol UNARY_OPERATOR. In this case, we know that the only way to produce such a node is to use the rule body PLUS_PLUS DECL_REF_EXPR. First, the matcher makes sure the aforementioned AST node has the right structure: there are two child nodes, a PLUS_PLUS and a DECL_REF_EXPR. Then, Syntex recursively repeats the same process for those nodes. For example, for the PLUS_PLUS child, Syntex ensures that it’s a token node with the spelling “++”.
Additional features and example uses
An important feature of Syntex, briefly shown in the length truncation example above, is that it supports “meta variables” in queries. For instance, when a query such as “++i” is specified, the matcher will find only expressions incrementing variables called i. However, if we were to specify “++$” as the query, then Syntex will find expressions that increment anything. Meta variables can also be named, such as in the query “++$x”, allowing the client to retrieve the matching sub-expression by name (x) for further processing. Furthermore, Syntex allows constraints to be applied to meta variables, such as in the query “++$x:DECL_REF_EXPR”; with these constraints, Syntex would match only increments to expressions x referencing a declaration. In-query constraints are limited in expressivity, which is why the C++ API allows arbitrary C++ functions to be attached as predicates that decide to accept or reject potentially matching candidates.
Another important feature, also shown in the length truncation example above, is the globbing operator “$...”. It allows users to specify queries such as “printf($...)”. The glob operator is useful when one wants to match an unknown number of nodes. Glob operator semantics are neither greedy nor lazy. This is in part because of the non-traditional nature of Syntex-generated grammars: where a hand-coded grammar might condense list-like repetition via recursive rules, Syntex grammars explicitly represent each observed list length via a different rule. Thus, a call to printf with one argument is matched by a different rule than a call to printf with five arguments. Because Syntex can “see” all of these different rules of different lengths, it’s able to express interesting patterns with globbing, such as “printf($... i $...)”, which will find all calls to printf with i appearing somewhere in the argument list.
Parting thoughts
Syntex’s approach is unique among traditional syntactic pattern searching tools: the search engine contains very little language-specific code and easily generalizes to other programming languages. The only requirement for using Syntex is that it needs to have access to the tokens that produced each AST node. In my prototype, the C and C++ ASTs are derived from PASTA.
Syntex has already exceeded the capabilities of open-source and/or publicly available alternatives, such as Semgrep and weggli. Syntex isn’t “done,” though. The next step is to develop Syntex so that it searches through source code text that doesn’t quite exist. One of the most powerful features of the C++ language is its templates: they allow programmers to describe the shape of generic data structures and the computations involving them. These templates are configured with parameters that are substituted with concrete types or values at compile time. This substitution, called “template instantiation,” creates variants of code that were never written. In future versions of Syntex, we plan to make C++ template instantiations syntax-searchable. Our vision for this feature relies on Clang’s ability to pretty print AST nodes back to source code, which will provide us with the code needed for our grammar-building process.
Last but not least, I would like to thank Trail of Bits for providing the opportunity to tackle such an interesting research project during my internship. And I would like to thank Peter Goodman for the project idea and for mentoring me throughout the process.