
Look out! Divergent representations are everywhere!
Trail of Bits recently published a blog post about a signed integer overflow in certain versions of SQLite that can enable arbitrary code execution and result in a denial of service. While working on proof-of-concept exploits for that vulnerability, we noticed that the compiler’s representation of an important integer variable is semantically different in different parts of the program. These differences result in inconsistent interpretations of the variable when it overflows, which we call “divergent representations.” Once we found an example, we tried to find more—and discovered that divergent representations are actually quite common in compiled C code.
This blog post examines divergent representations of the same source code variable produced by compiler optimizations. We’ll attempt to define divergent representations and look at the SQLite vulnerability we discovered, which was made easier to exploit by the divergent representation of a source code variable (one exhibiting undefined behavior). We’ll then describe the binary and source code analyses that we used to find more divergent representations in existing open-source codebases. Finally, we’ll share some suggestions for eliminating the risk that a program will be compiled with divergent representations.
A simple example
Here’s a simple example of a real-life code pattern that can result in divergent representations:
int index_of(char *buf, char target) {
int i;
for (i=0; buf[i] != target; i++) {}
return i;
}The index_of function receives a character array as input, loops through the array and increments i until it encounters the first target character, and returns the index of that target character. One might expect that buf[index_of(buf, target)] == target, but the evaluation of that statement can depend on the compiler’s optimization level. More specifically, it can depend on the compiler’s handling of undefined behavior when the value of i exceeds the maximum positive int value (INT_MAX, i.e., 0x7fffffff).
If the target character appears in the first INT_MAX bytes of the buffer, the function will exhibit well-defined behavior, assuming that the platform uses 32-bit integers. If the function scans the first INT_MAX bytes of the array without finding the target character, i will be incremented beyond the maximum representable positive value for the int type, which is undefined behavior.
So how would the compiler handle that code—that is, code that could exhibit a signed integer overflow at runtime? Of course, because signed integer overflows are undefined behavior, the compiler could choose to do anything at all, including producing “nasal demons.” This is a question about expectations, then: What would we expect a reasonable compiler to do? If i were incremented beyond INT_MAX, where would we expect index_of to try to read a character from memory?
We might expect the compiler to make one of two seemingly reasonable choices:
- Represent
ias a signed 32-bit value, causingito wrap fromINT_MAX(a positive value represented as0x7fffffff) toINT_MIN(a negative value represented as0x80000000), in which case the function would read the next byte from buf[INT_MIN] as a negative array index - Represent
ias an unsigned 64-bit value, causingito increment to the unsigned value0x80000000and the function to read the next byte frombuf[0x80000000ul], which is the next contiguous byte in memory
In either case, if the next character read were the target byte, the index_of function would return (int) 0x80000000, which is INT_MIN (a negative number). However, in case 2, the memory location checked for the target character would not be buf[INT_MIN]. In other words, the expression buf[index_of(buf, target)] == target would not be true if the compiler chose to represent i as an unsigned 64-bit value—and that is exactly how Clang compiles index_of at optimization level -O1 and above:
index_of(char*, char): # @index_of(char*, char)
mov eax, -1
.LBB0_1: # =>This Inner Loop Header: Depth=1
inc eax
lea rcx, [rdi + 1]
cmp byte ptr [rdi], sil
mov rdi, rcx
jne .LBB0_1
retThis is an example of a divergent representation of the same source code variable, i. The value of i returned by the function is represented by addition (inc) on the 32-bit eax register, while the value of i used to access the array buffer is represented by addition (lea) on the 64-bit rdi register. The source code makes no distinction between these two versions of i, as the programmer likely expected that the value used to index into the buffer would be the same one returned by the function. As we’ve shown, though, that is not the case.
How do divergent representations appear?
A compiler can apply optimizations to a program to improve the program’s performance. Compilers must ensure the correctness of operations over well-defined inputs, but they can take arbitrary liberties to speed up the execution of undefined behavior. For example, to optimize code on a 64-bit platform, a compiler can replace 32-bit addition with 64-bit addition, because the defined behavior of addition on a 32-bit platform is also defined behavior on a 64-bit platform.
A divergent representation occurs when a compiler applies program optimizations that cause a single source variable to be represented with different semantics in the output program. The instances of divergent representations that we’ve observed all result from undefined behavior (particularly signed integer overflows). Since programmers shouldn’t write programs with undefined behavior, one could argue that divergent representations are a non-issue. However, we assert that programs ought to have consistent interpretations of the same value even in cases of undefined behavior.
The divergent representations that we’ve found occur in code that fits the following pattern:
- A signed integer variable is declared outside of a loop.
- The variable is incremented or decremented in the loop and is allowed to overflow.
- The variable is used in the loop to access an array.
- The variable is used outside of the loop.
A 2011 discussion on the LLVM developers mailing list provides fascinating insight into the representation of variables that may overflow, along with the effect that an overflow has on optimizations.
A wild divergent representation appears
We discovered our first divergent representation while we were trying to develop a proof-of-concept exploit for CVE-2022-35737, a vulnerability that we discovered in SQLite. We noticed that our proof-of-concept exploit behaved differently when executed with a debug build of libsqlite3.so (compiled without optimizations) and with the optimized release version of libsqlite3.so; we found that curious, as it seemed to imply that the optimizations had produced semantically different compilations of the same library.
We dug deeper by disassembling the two versions of the library and analyzing the code near the vulnerability. The differences in the compiled code stem from the source code, specifically the sqlite3_str_vappendf function:
806 int i, j, k, n, isnull;
...
824 k = precision;
825 for(i=n=0; k!=0 && (ch=escarg[i])!=0; i++, k--){
826 if( ch==q ) n++;
827 if( flag_altform2 && (ch&0xc0)==0xc0 ){
828 while( (escarg[i+1]&0xc0)==0x80 ){ i++; }
829 }
830 }The figure below shows the disassembled version of the optimized binary:
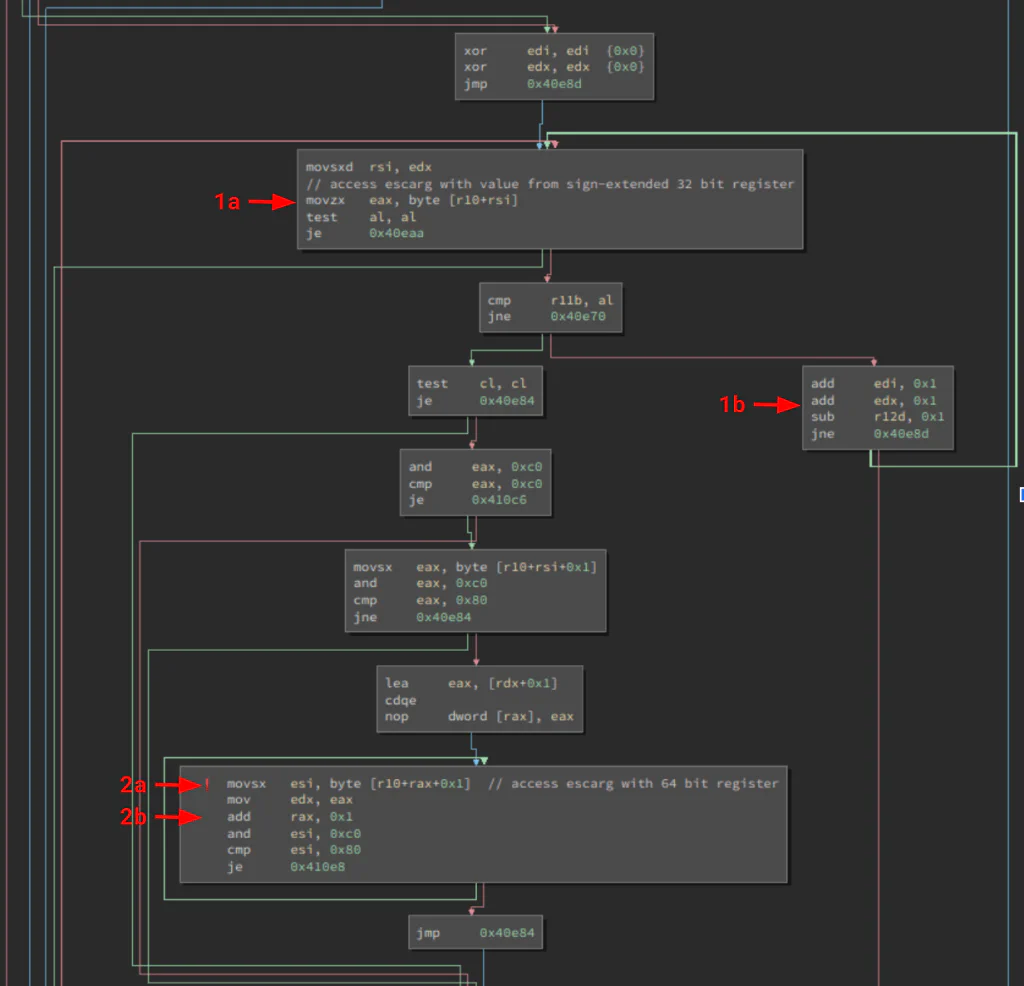
In that code snippet, a user input buffer (escarg) is scanned for quotation marks and Unicode characters. At instruction [1a], r10 contains the address of escarg, and rsi is used to index into the buffer to fetch a value from it; the rsi register is set in the previous instruction, which sign-extends the 32-bit edx register. This indexing operation corresponds to the escarg[i] expression on line 825 of the source code. With each loop iteration, edx is incremented at instruction [1b]; thus, the source code variable i is represented as a signed 32-bit integer and can be used as a negative index into escarg.
However, instruction [2a] shows something different: r10 still contains the address of escarg, but rax+1 is used to index into the buffer in the inner loop that scans for Unicode characters (in the escarg[i+1] expression on line 828 of the source code). Instruction [2b] increments rax as a 64-bit value—and with no 32-bit sign extension—before looping back to [2a]. This version of i is represented as a 64-bit unsigned integer, so when i exceeds the maximum 32-bit signed integer value (0x7fffffff), its next memory access will be at escarg+0x80000000.
The exploit worked by leveraging the different semantics for i on line 828; these semantics cause i to wrap to a specific small positive value upon an overflow, so it will not be used as a negative index into the escarg buffer on line 825. Details on the exploit are provided in our blog post about the vulnerability and in our proof-of-concept exploits.
Searching for more divergent representations
After finding a divergent representation in a popular codebase, we started wondering, “Is it a one-off? Can we find divergent representations in other projects?” We tried two approaches to identifying other potential divergent representations and found more examples in SQLite and libxml2.
Bottom-up (compiled binary) search
In our first attempt to find more divergent representations, we took a “bottom-up” approach, looking directly at compiled binaries. We wrote a Binary Ninja script that models the compiled patterns of divergent representations and leverages the abstractions provided by Binary Ninja’s Medium Level Intermediate Language (MLIL) Static Single Assignment (SSA) form. We scanned all instructions in each function’s MLIL representation for any Phi nodes that do the following:
- Use a variable that is defined by the Phi node’s defined variable (indicating that the node may affect a loop-control variable)
- Define a variable that is used in a downcasting operation (and is thus represented elsewhere as a narrower value)
- Use a variable that is assigned multiple sizes (i.e., a variable that may be represented as either 64 bit or 32 bit)
- Define a variable that is used in a subsequent 64-bit operation
If a Phi node matched all of those criteria, we marked it as a potential source of a divergent representation and printed it to the Binary Ninja console terminal for investigation.
Our script found additional potential divergent representations in both SQLite and libxml2, including in the libxml2 nodes below:
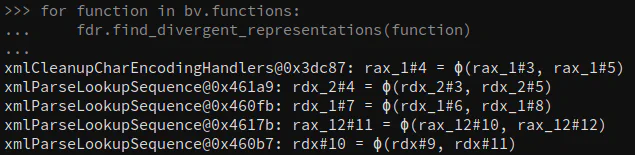
The script also identified the following Phi node not pictured above:
xmlBuildURI@0x7b6c0: rax_33#51 = ϕ(rax_33#50, rax_33#52)The addr2line utility indicates that this portion of the binary corresponds to libxml2/uri.c:2085 in the xmlBuildURI function:
2084 while (bas->path[cur] != 0) {
2085 while ((bas->path[cur] != 0) && (bas->path[cur] != '/'))
2086 cur++;
2087 if (bas->path[cur] == 0)
2088 break;
2089
2090 cur++;
2091 while (out < cur) { 2092 res->path[out] = bas->path[out];
2093 out++;
2094 }
2095 }This code pattern appears to be similar to that in the original SQLite code. Note, though, that code compiled with divergent representations will not necessarily be reachable, even with undefined inputs. For example, if there is no way to advance the integer cur beyond the acceptable values for a 32-bit integer, the semantics of the integer in the above code snippet will not diverge.
Unsurprisingly, when we ran our script on a version of the libraries compiled without optimizations (level -O0), we did not find any divergent representations. That outcome validated our understanding of divergent representations as caused by compiler optimizations.
Top-down (source code) search
We also performed a “top-down” search for source code patterns that could produce divergent representations when compiled with optimizations.
We used CodeQL to create source code queries. These queries identify source code in which the following conditions hold:
- A variable is declared outside of a loop.
- The variable is incremented in the loop body.
- The variable is used to access memory in a statement in the loop body.
- The variable is used again after the loop, outside of the loop body.
We also ran CodeQL with an additional optional condition, querying for cases in which the variable is used to access memory in a conditional statement in the loop, rather than just in its body. That cut down on the number of false positives by eliminating cases in which a loop condition prevents the variable from overflowing. (For example, if i is used in the loop condition i < 10, it won’t overflow, but if the loop condition is buf[i] != x, i may overflow.)
CodeQL found 20 code patterns that could produce divergent representations in libxml2, two of which (in xmlBuildURI) were also identified by Binary Ninja.
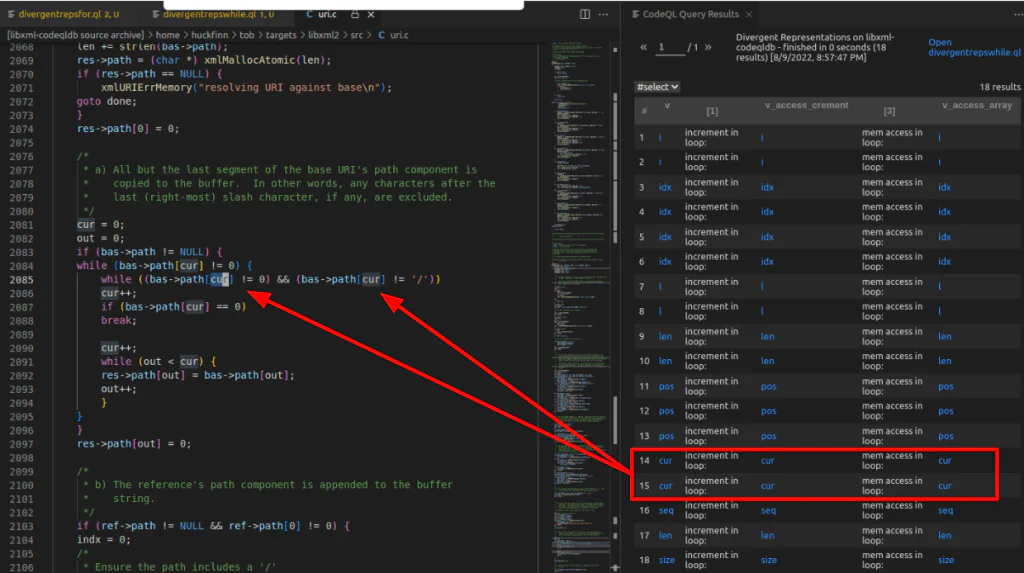
Note that our top-down and bottom-up searches identified code in which divergent representations may exist; an actual divergence in the program semantics would still require input that caused undefined behavior.
Preventing divergent representations in compiled programs
The best way to prevent a divergent representation is to avoid including undefined behavior in a program. That’s not particularly actionable advice, though. It would be even less helpful for us to suggest that programmers avoid writing for and while loops that use variables declared outside of the loop.
Instead, programmers should use data types that cannot overflow for variables used to count or access arrays (e.g., size_t or uintptr_t instead of int). They should also avoid a practice that is unfortunately common among C programmers: tying error conditions to int functions’ negative return values (e.g., using a return value of -1 to indicate a failure); assuming a larger-scale refactoring is not possible, we recommend using ssize_t instead of int in those cases. Finally, programmers should avoid making any assumptions whatsoever about what a program will do in response to undefined behavior.
Conclusion
We cannot make a blanket statement assessing the risks associated with divergent representations. Some, basically unreachable, can be seen as curiosities of undefined behavior—a source of C programming trivia questions that will stump your friends. Others may be more consequential, turning otherwise benign integer overflows into exploitable vulnerabilities, as in the case of our SQLite vulnerability. Our hope is that by describing the phenomena and enabling programmers to identify divergent representations when they appear, we can help the community accurately gauge their severity.
I’d like to thank my mentor, Peter Goodman, for his expert guidance in the pursuit of vulnerabilities and weird compiler behaviors during my summer internship with Trail of Bits.