
Porting the Solana eBPF JIT compiler to ARM64
During my summer internship at Trail of Bits, I worked on the fork of the RBPF JIT compiler that is used to execute Solana smart contracts. The RBPF JIT compiler plays a critical role on the Solana blockchain, as it facilitates the execution of contracts on validator nodes by default.
Before my work on this project, RBPF supported JIT mode only on x86 hosts. An increasing number of developers are using ARM64 machines, but are unable to run their test in JIT mode. My primary goal was to add support in RBPF for the ARM64 architecture, mainly by updating the register map, calling convention, and all of the subroutines and instruction translations to emit ARM64 instructions. I also aimed to implement support for Windows in the RBPF x86 JIT compiler.
The work is live and can be found in two pull requests on Solana’s GitHub page. However, a caveat: it is currently behind a feature-gate ('jit-aarch64-not-safe-for-production') and is not ready for production until it has received a thorough peer review.
Background
Smart contracts that run on the Solana blockchain are compiled from Rust (or C, if you like bugs) to eBPF, an extended version of the Berkeley Packet Filter. The eBPF virtual machine’s architecture is fairly simple, with a minimal set of 32- and 64-bit integer operations (including multiplication and division) and memory and control flow instructions. BPF programs have their own address space, which in RBPF consists of code, stack, heap, and input data sections located at fixed addresses.
The version of BPF supported by RBPF was designed to work with programs compiled using the LLVM BPF back end. The official Linux documentation for eBPF shows that there are a few differences between RBPF and eBPF—most notably, RBPF has to support an indirect call (callx) instruction.
Furthermore, RBPF’s “verifier” is much simpler than that of eBPF. In the Linux kernel, the eBPF verifier validates certain safety properties of BPF programs before JITing and executing them. In RBPF, Solana programs pass through a much simpler verifier before being JITed. The verifier checks for instructions that try to divide by a constant zero, jump to a clearly invalid address, or read or write to an invalid register, among other errors. Notably, the RBPF verifier does not perform any CFG analysis or attempt to track the range of values held by each register. The full list of errors that the RBPF verifier checks for can be found in the RBPF verifier source.
RBPF internals
RBPF verifies then translates an entire program, instruction by instruction, into the target architecture before finally calling into the emitted code. This involves an eBPF instruction decoder and a partial instruction encoder for the target architecture (before the summer of 2022, only x86 was supported). RBPF also provides an interpreter capable of executing eBPF Solana programs, but the JITed translations are the default for performance reasons.
Memory and address translation
BPF programs are executed in their own memory space, and there is a mapping between this address space and the host address space. Memory regions are set up (using mmap and mprotect) for each program that is to be executed; the BPF code, stack, heap, and input data have their own regions, located at fixed addresses in BPF address space. The locations of these mappings in the host address space are not fixed.
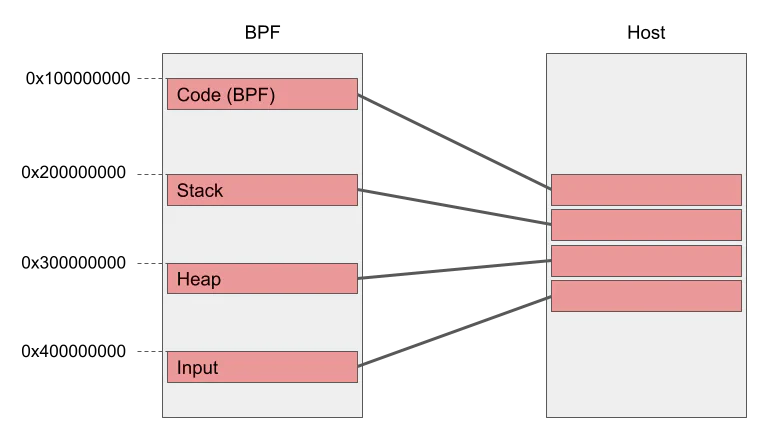
To handle eBPF load and store instructions, the address must first be translated into the host address space. RBPF includes a translate_memory_address assembly routine, which is responsible for looking up the region that contains the address being accessed and for translating the BPF address into a host address. This translation logic is invoked every time a BPF load or store instruction is executed, as shown in the example instruction translations later in this post.
Register allocation
BPF has 11 registers (10 general purpose registers and the frame pointer), each of which maps to a distinct register in the host architecture. On x86_64, which has 16 registers, four of the remaining registers are used for specific purposes (RSP cannot be repurposed, since the original host call stack will be maintained), described below:
// Special registers:
// ARGUMENT_REGISTERS[0] RDI BPF program counter limit (used by instruction meter)
// CALLER_SAVED_REGISTERS[8] R11 Scratch register
// CALLER_SAVED_REGISTERS[7] R10 Constant pointer to JitProgramArgument (also scratch register for exception handling)
// CALLEE_SAVED_REGISTERS[0] RBP Constant pointer to initial RSP - 8
Source: Line 224 of jit.rs in solana-labs
Instruction translation
Translating instructions in RBPF is a fairly straightforward process:
- Registers in the eBPF virtual machine are mapped to a unique register in the host architecture.
- Each opcode is translated to one or more instructions in the host architecture (via this large match statement).
Two example translations are displayed below:

RBPF includes subroutines that are emitted once to handle shared logic (such as address translation, which is performed by translating the load instruction above). Sometimes these subroutines include calls back into Rust code to handle more complicated operations (e.g., tracing, “syscalls”) or to update certain externally visible states (e.g., the instruction meter). There is also a prologue (e.g., to set up the stack, handle exceptions, etc.) and an epilogue (e.g., to handle cases in which the execution reaches the last instruction in the program and does not exit, which is normally done by calling an exit function).

Control flow
Every BPF instruction is a valid target address for a jump or call. eBPF instructions are 8 bytes, with one exception: load double word (LDDW), which is 16 bytes. This means that, with this one exception, every 8-byte boundary in the BPF code address space is a valid jump target.
Relative jumps can always be resolved before runtime; they can either be resolved at translation-time (for backward jumps) or be ‘fixed up’ after all instructions have been emitted (for forward jumps). Indirect calls, however, must be resolved at runtime. Therefore, RBPF keeps a mapping from the instruction index to the host address so that the location of the already-translated target instruction can be looked up when an indirect call occurs.
The instruction meter
Solana programs are designed to run with a specific ‘compute budget’, which is essentially the number of eBPF instructions that can be executed before the program exits. In order to enforce this limit (on potentially non-terminating programs), the JIT compiler emits additional logic to track the number of instructions that have been executed. The instruction meter is best described in this comment, but it can be summarized as follows:
- The source of each branch is instrumented to account for the instructions that were executed in the linear sequence since the last update and to record the branch target (the beginning of the next linear sequence of instructions to execute).
- If a conditional branch is not actually taken, the updates to the instruction meter are undone.
- Additional instruction meter checks are inserted at certain thresholds in long linear sequences of instructions.
The instruction meter has been the source of multiple bugs in the past (e.g., check out pull request 203 and pull request 263).
Calls and “syscalls”
For regular eBPF calls within the same program, RBPF keeps a separate stack from the host (currently using fixed-size stack frames), tracks the current call depth, and exits with an error if the call depth exceeds its budget. Solana programs in particular also need to invoke other contracts and interact with certain blockchain states. RBPF has a mechanism called “syscalls” by which eBPF programs can make calls into Solana-specific helper functions implemented in Rust.
Exceptions
The JIT compiler may exit early if it encounters a number of unrecoverable runtime conditions (such as division by zero or invalid memory access). Since the verifier does not attempt to track register content, most exceptions are caught at runtime rather than at verification time. Exception handlers are designed to record the current exception information into an EbpfError enum and then proceed to the exit the subroutine (which returns back into Rust code).
Security mitigations
RBPF contains a few features that fall under the category of “machine code diversification” and serve to somewhat harden the JIT compiler against exploitation. Two of the features (introduced last year) are constant sanitization and instruction address randomization.
Constant sanitization changes how immediates are loaded into registers in the emitted code. Rather than emitting a typical x86 MOVABS instruction, which would contain the unmodified bytes of the immediate, the immediate is instead offset by a randomly generated key. At runtime, this key is fetched from memory in a subsequent instruction and added so that the destination register contains the originally desired immediate.
Instruction address randomization adds no-op instructions at random locations throughout the emitted code. Both of these mitigations are intended to make code-reuse attacks more difficult.
Porting RBPF to ARM64
Calling convention and register allocation
The JIT compiler needs to be able to call into Rust code, which will follow the host’s calling convention. Luckily, most platforms follow the ARM software standard for the calling convention. Both Apple and Microsoft publish their own ABI documentation, but they mostly follow the standard ARM64 documentation. I tested my implementation on M1 running macOS and on an emulated ARM64 virtual machine through QEMU.
Note that ARM64’s additional registers mean that even after mapping each eBPF register to a host register, there is a substantial number of extra unused host registers. I used some of these extra registers to hold additional “scratch” values during the translation of more complex instructions. Additional scratch values are often helpful since only load and store instructions can access memory in ARM64, which often results in longer translations with more temporary values.
Instruction-by-instruction translation
I wrote translations to ARM64 for each of the eBPF instructions, modeled closely after their x86 translations. The following is an example of the existing x86 and the new translated ARM64 code for two variants of the eBPF ADD instruction.


Note that ARM64’s fixed instruction size of 4 bytes means that you can’t encode every 32-bit immediate in a single instruction, and ARM64 ALU instructions can encode only a very limited range of immediate values. So some simple eBPF instructions require multiple ARM64 instructions (e.g., emit_load_immediate64 may emit more than one instruction to move the immediate into the scratch register), even if they require only a single x86 instruction.
Some surprises
The ARM64 ABI has a required stack alignment of 16-bytes at the time of any SP-relative access; this alignment is supposed to be enforced by hardware. QEMU does not enforce this alignment by default, but the Apple M1 does.
The subroutines (which are responsible for exception handling, address translation, resolving indirect calls, etc.) each have slightly different conventions for their inputs and outputs, and these conventions are not well documented. Rewriting these subroutines correctly in ARM64 was, by far, the most time-consuming part of this process. I did eventually document many of my assumptions about these subroutines. These subroutines are also responsible for some quite complex logic, including address translation and instruction meter accounting.
When I published the ARM64 port, I made sure it was behind a feature-gate, jit-aarch64-not-safe-for-production. This is an intern project aimed to allow developers to use the JIT compiler, and it is not ready for production until it has received a thorough peer review.
My ARM64 port of RBPF is currently available through the Trail of Bits fork or this pull request.
Winapi
The Windows virtual memory APIs use VirtualAlloc and VirtualProtect in lieu of mmap and mprotect. For our purposes, these are nearly drop-in replacements—I just had to pick the permission and allocation options that correspond most closely to those used in mmap and mprotect.
Calling convention
The Windows x64 calling convention designates different registers as caller and callee-save; it also has an additional “shadow space” requirement in which callers are responsible for leaving 32 bytes of space on the stack before the call (after any stack-resident arguments have been pushed).
As with ARM64, Windows support is behind a feature flag, jit-windows-not-safe-for-production.
A small, unexploitable bug
My ARM64 port of RBPF did uncover a small, unexploitable uninitialized memory bug that was present even in the existing x86 JIT compiler. VTCAKAVSMoACE pointed out some warnings when running my ARM64 branch under the LLVM memory sanitizer (MSAN). I investigated these warnings and found the culprit to be this function:
fn emit_set_exception_kind<E: UserDefinedError>(jit: &mut JitCompiler, err: EbpfError<E>) {
let err = Result::<u64, EbpfError<E>>::Err(err);
let err_kind = unsafe { *(&err as *const _ as *const u64).offset(1) };
...
emit_ins(jit, X86Instruction::store_immediate(OperandSize::S64, R10, X86IndirectAccess::Offset(8), err_kind as i64));
}This function takes an EbpfError value as the second argument, moves it into a Result, and then uses unsafe code to grab bytes 8 through 16 out of the Result. These bytes correspond to the integer discriminant that determines which variant (error type) the EbpfError is. No guarantees are made by the Rust compiler about the size or layout of enums, unless you add a repr attribute to the enum (like #[repr(u64)]).
The Rust compiler had decided that the EbpfError enum discriminant would be only a u8, so the enum that is passed to emit_set_exception_kind actually had 7 bytes of uninitialized stack memory that was being written into the JIT code region. Uninitialized (potentially attacker-controlled) bytes that are written into an executable region is not a bug on its own, but they partially defeat the purpose of the code-reuse mitigations discussed above.
I opened a pull request that adds #[repr(u64)]. Since the JIT compiler makes an additional assumption about enum layouts (i.e., for Result in the Rust standard library), I also added tests that should detect whether the compiler ever changes the location or size of the enum discriminant on certain types.
Conclusion
Given how important the RBPF JIT compiler is to the Solana blockchain, we felt that it was important for the widest range of developers to use it on whatever machine they are using for development. Now, it’s possible for developers using either M1 and Windows machines to also use the JIT compiler during testing. While the work still needs a peer review, it can be found in two pull requests on GitHub. Feel free to try it out!
Thanks to Anders Helsing for the fantastic guidance as I explored the internals of RBPF, and learned the finer points of both the ARM64 and Windows x64 ABI.
This work shows how Trail of Bits is rooted in solving Solana’s security challenges, building upon the deep Solana expertise we’ve used to build tools we have already released to the public. Not only do we aim to make Solana as secure as possible, we want to make the tools engineers use with Solana equally as secure. Our ultimate goal with these efforts is to raise the security level for all of the Solana projects that will be built in the future.