
PrivacyRaven: Implementing a proof of concept for model inversion
Originally published August 3, 2021
During my Trail of Bits winternship and springternship, I had the pleasure of working with Suha Hussain and Jim Miller on PrivacyRaven, a Python-based tool for testing deep-learning frameworks against a plethora of privacy attacks. I worked on improving PrivacyRaven’s versatility by adding compatibility for services such as Google Colab and expanding its privacy attack and assurance functionalities.
What is PrivacyRaven?
PrivacyRaven is a machine-learning assurance and research tool that simulates privacy attacks against trained machine-learning models. It supports model extraction and label-only membership inference attacks, with support for model inversion currently in development.
In a model extraction attack, a user attempts to steal or extract a trained deep-learning model that outputs either a probability vector corresponding to each class or a simple classification. For instance, consider a classifier that detects particular emotions in human faces. This classifier will return either a vector specifying the likelihood of each emotion or simply the most likely emotion as its classification. Importantly, the user will have only black-box query access to the classifier and will not receive any other information about it.
To perform a model extraction attack, the user first queries the model with random unlabeled data to identify all of the classifications returned by the model. This information can then be used to approximate the target classifier. Specifically, the attacker uses a public data source to obtain synthetic data (i.e., similar data such as a dataset of facial images and emotion classifications) and trains a substitute fixed-architecture model on that data.
If successful, such an attack could have drastic consequences, especially for services that hide their actual models behind a paid API; for example, an attacker, for a low cost, could approximate a service’s model with a small decrease in accuracy, thereby gaining a massive economic advantage over the victim service. Since PrivacyRaven operates under the most restrictive threat model, simulating attacks in which the user has only query access, model extraction is also a critical component of PrivacyRaven’s other attacks (i.e., membership inference attacks).
I worked on implementing support for a model inversion attack aimed at recovering private data used to train a target model. The model inversion attack uses model extraction to secure white-box access to a substitute classifier that faithfully approximates the target.
What is model inversion?
In a model inversion attack, a malicious user targets a classifier that predicts a vector of confidence values for each class; the user then attempts to recover its training data to compromise its privacy
It turns out that a user with background knowledge about the model may actually be able to obtain a reasonable approximation of the target model’s training data. (For an example of such an approximation, see the image recovered from a facial recognition system in the figure below.) This is the core idea of several papers, including “Adversarial Neural Network Inversion via Auxiliary Knowledge Alignment,” by Ziqi Yang et al., which formed the basis of my implementation of model inversion.

Model inversion attacks based on background knowledge alignment have plenty of use cases and consequences in the real world. Imagine that a malicious user targeted the aforementioned facial emotion classifier. The user could construct his or her own dataset by scraping relevant images from a search engine, run the images through the classifier to obtain their corresponding confidence values, and construct probability vectors from the values; the user could then train an inversion model capable of reconstructing approximations of the images from the given vectors.
An inversion model is designed to be the inverse of the target model (hence the use of “inversion”). Instead of inputting images and receiving an emotion classification, the attacker can supply arbitrary emotion-prediction vectors and obtain reconstructed images from the training set.
Using the above example, let’s walk through how the user would run a model inversion attack in greater detail. Assume that the user has access to an emotion classifier that outputs confidence values for some of its classes and knows that the classifier was trained on images of faces; the user therefore has background knowledge on the classifier.
The user, via this background knowledge on the model, creates an auxiliary dataset by scraping images of faces from public sites and processing them. The user also chooses an inversion model architecture capable of upscaling the constructed prediction vectors to a “reconstructed” image.
To train the inversion model, the user queries the classifier with each image in the auxiliary dataset to obtain the classifier’s confidence values for the images. That information is used to construct a prediction vector. Since this classifier might output only the top confidence values for the input, the inversion process assumes that it does in fact truncate the prediction vectors and that the rest of the entries are zeroed out. For example, if the classifier is trained on 5 emotions but outputs only the top 2, with confidence values of 0.5 and 0.3, the user will be able to construct the vector (0.5, 0, 0.3, 0, 0) from those values.
The user can then input the prediction vector into the inversion model, which will upscale the vector to an image. As a training objective, the user would like to minimize the inversion model’s mean squared error (MSE) loss function, which is calculated pixelwise between images in the auxiliary set and their reconstructions outputted by the model; the user then repeats this training process for many epochs.
An MSE close to 0 means that the reconstructed image is a sound approximation of the ground truth, and an MSE of 0 means that the reconstructed and ground truth images are identical. Once the model has been sufficiently trained, the user can feed prediction vectors into the trained inversion model to obtain a reconstructed data point representative of each class.
Note that the model inversion architecture itself is similar to an autoencoder, as mentioned in the paper. Specifically, the classifier may be thought of as the encoder, and the inversion network, as the decoder, with the prediction vector belonging to the latent space. The key differences are that, in model inversion, the classifier is given and fixed, and the training data of the classifier is not available to train the inversion network.
My other contributions to PrivacyRaven
While I focused on implementing model inversion support in PrivacyRaven, in the first few weeks of my internship, I helped improve PrivacyRaven’s documentation and versatility. To better demonstrate certain of PrivacyRaven’s capabilities, I added detailed example Python scripts; these include scripts showcasing how to mount attacks and register custom callbacks to obtain more thorough information during attack runs. I also added Docker and Google Colab support, which allows users to containerize and ship attack setups as well as to coordinate and speed up an attack’s development.
Caveats and room to grow
PrivacyRaven is designed around usability and is intended to abstract away as much of the tedium of data and neural network engineering as possible. However, model inversion is a relatively fragile attack that depends on fine-tuning certain parameters, including the output dimensionality of both the classifier and inversion model as well as the inversion model’s architecture. Thus, striking a balance between usability and model inversion fidelity proved to be a challenge.
Another difficulty stemmed from the numerous assumptions that need to be satisfied for a model inversion attack to produce satisfactory results. One assumption is that the user will be able to recover the number of classes that the target classifier was trained on by querying it with numerous data points.
For example, if the user were trying to determine the number of classes that an object recognition classifier was trained on, the user could query the classifier with a large number of images of random objects and add the classes identified in that process to a set. However, this might not always work if the number of training classes is large; if the user isn’t able to recover all of the classes, the quality of the inversion will likely suffer, though the paper by Yang et al. doesn’t analyze the extent of the impact on inversion quality.
In addition, Yang et al. were not explicit about the reasoning behind the design of their classifier and inversion model architectures. When conducting their experiments, the authors used the CelebA and MNIST datasets and resized the images in them. They also used two separate inversion architectures for the datasets, with the CelebA inversion architecture upscaling from a prediction vector of length 530 to a 64 x 64 image and the MNIST inversion architecture upscaling from a prediction vector of length 10 to a 32 x 32 image. As you can imagine, generalizing this attack such that it can be used against arbitrary classifiers is difficult, as the optimal inversion architecture changes for each classifier.
Finally, the authors focused on model inversion in a white-box scenario, which isn’t directly adaptable to PrivacyRaven’s black-box-only threat model. As previously mentioned, PrivacyRaven assumes that the user has no knowledge about the classifier beyond its output; while the general model inversion process remains largely the same, a black-box scenario requires the user to make many more assumptions, particularly on the dimensions of the training data and the classifier’s output. Each additional assumption about dimensionality needs to be considered and addressed, and this inherent need for customization makes designing a one-size-fits-all API for model inversion very difficult.
Next steps
PrivacyRaven does not yet have a fully stable API for model inversion, but I have completed a proof-of-concept implementation of the paper. Some design decisions for the model inversion’s API still need to mature, but the plan is for the API to support both white-box and black-box model inversion attacks and to make the model inversion and extraction parameters as customizable as possible without sacrificing usability. I believe that, with this working proof of concept of model inversion, the development of the model inversion API should be a relatively smooth process.
Inversion results
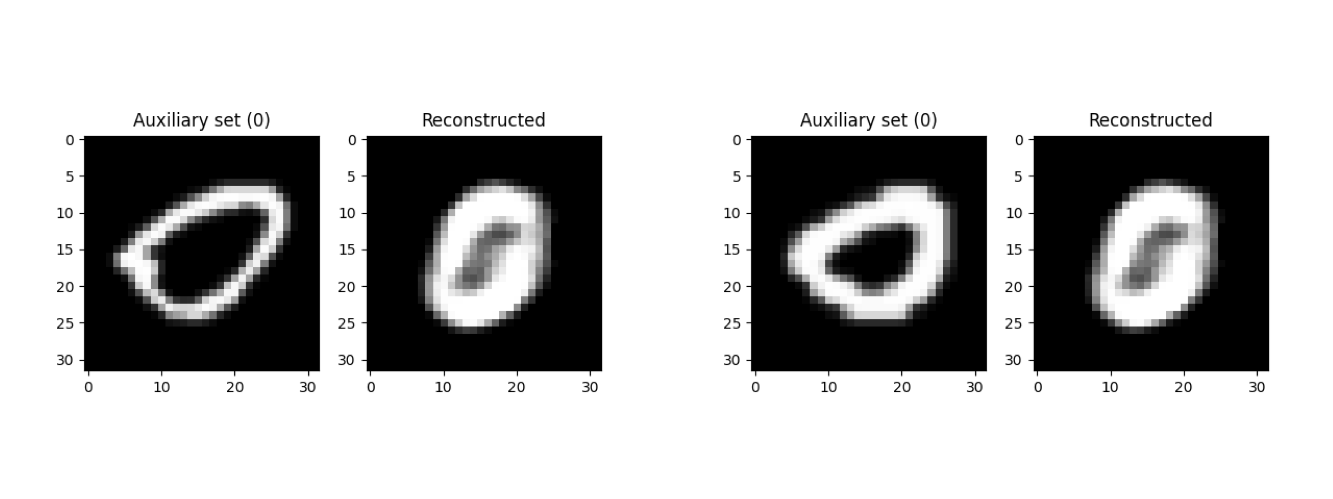
The inversion results produced by the proof of concept are displayed below. This attack queries an MNIST-trained victim classifier with extended-MNIST (EMNIST) data to train a substitute model that can then be used to perform a white-box inversion attack. The model inversion-training process was run for 300 epochs with batch sizes of 100, producing a final MSE loss of 0.706. The inversion quality changed substantially depending on the orientation of the auxiliary set images. The images on the left are samples of the auxiliary set images taken from the MNIST set, with their labels in parentheses; their reconstructions are on the right.
Images of a 0, for example, tended to have fairly accurate reconstructions:
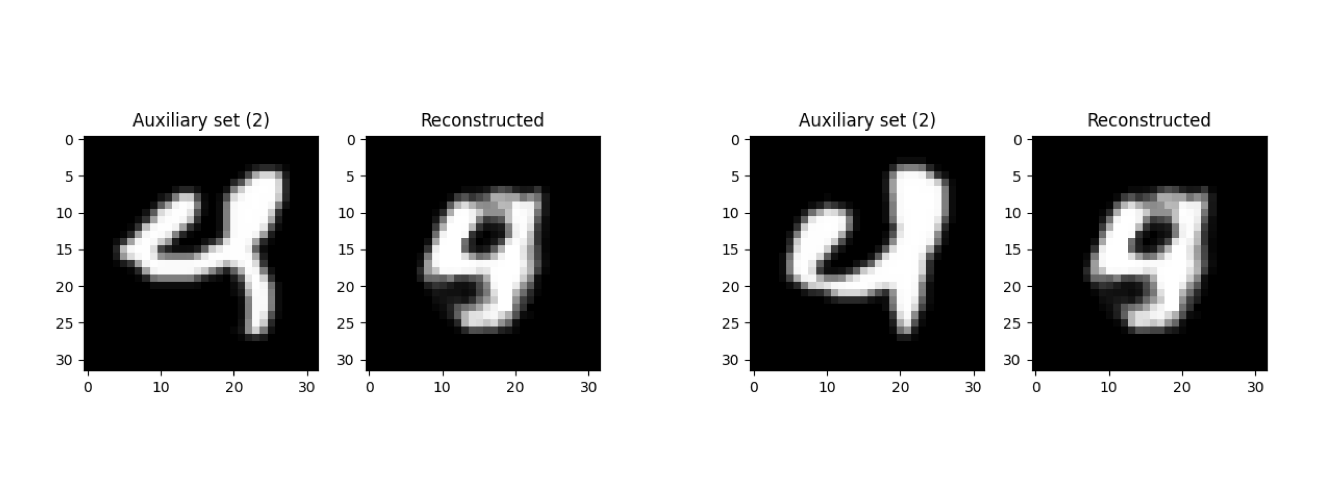
Other auxiliary set images had reconstructions that looked similar to them but contradicted their labels. For example, the below images appear to depict a 4 but in reality depict a 2 rotated by 90 degrees.
Other images also had poor or ambiguous reconstructions, such as the following rotated images of an 8 and 9.
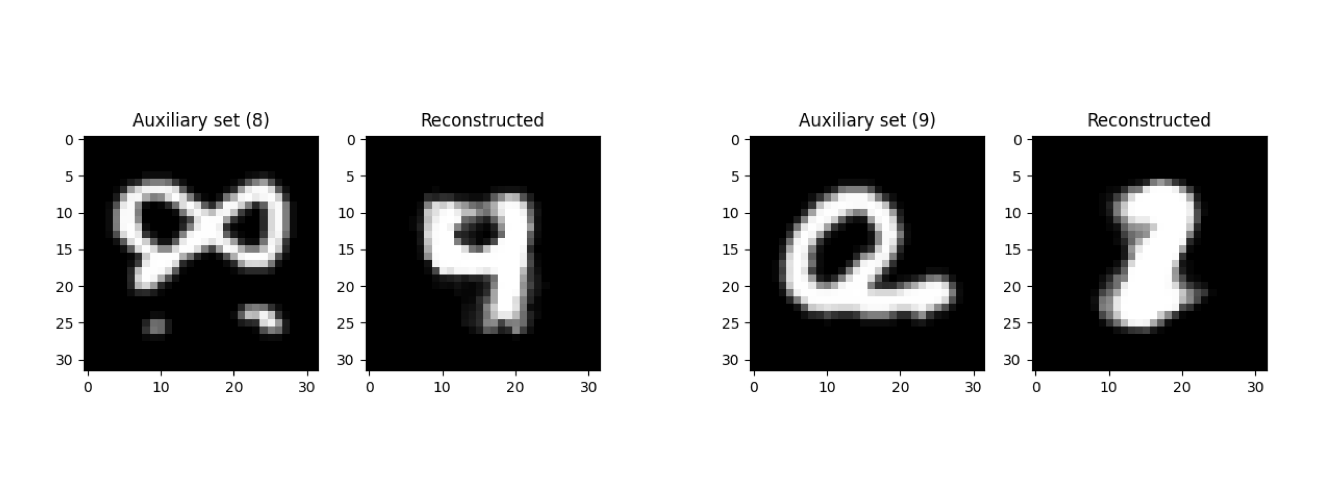
Overall, these results demonstrate that model inversion is a fragile attack that doesn’t always produce high-quality reconstructions. However, one must also consider that the above inversion attack was conducted using only black-box queries to the classifier. Recall that in PrivacyRaven’s current model inversion pipeline, a model extraction attack is first executed to grant the user access to a white-box approximation of the target classifier. Since information is lost during both model extraction and inversion, the reconstruction quality of a black-box model inversion attack is likely to be significantly worse than that of its white-box counterpart. As such, the inversion model’s ability to produce faithful reconstructions for some images even under the most restrictive assumptions does raise significant privacy concerns for the training data of deep-learning classifiers.
Takeaways
I thoroughly enjoyed working on PrivacyRaven, and I appreciate the support and advice that Jim and Suha offered me to get me up to speed. I am also grateful for the opportunity to learn about the intersectionality of machine learning and security, particularly in privacy assurance, and to gain valuable experience with deep-learning frameworks including PyTorch. My experience working in machine-learning assurance kindled within me a newfound interest in the field, and I will definitely be delving further into deep learning and privacy in the future.