
A Year in the Life of a Compiler Fuzzing Campaign
In the summer of 2020, we described our work fuzzing the Solidity compiler, solc. So now we’d like to revisit this project, since fuzzing campaigns tend to “saturate,” finding fewer new results over time. Did Solidity fuzzing run out of gas? Is fuzzing a high-stakes project worthwhile, especially if it has its own active and effective fuzzing effort?
The first bugs from that fuzzing campaign were submitted in February of 2020 using an afl variant. Since then, we’ve submitted 74 reports. Sixty-seven have been confirmed as bugs, and 66 of those have been fixed. Seven were duplicates or not considered to be true bugs.
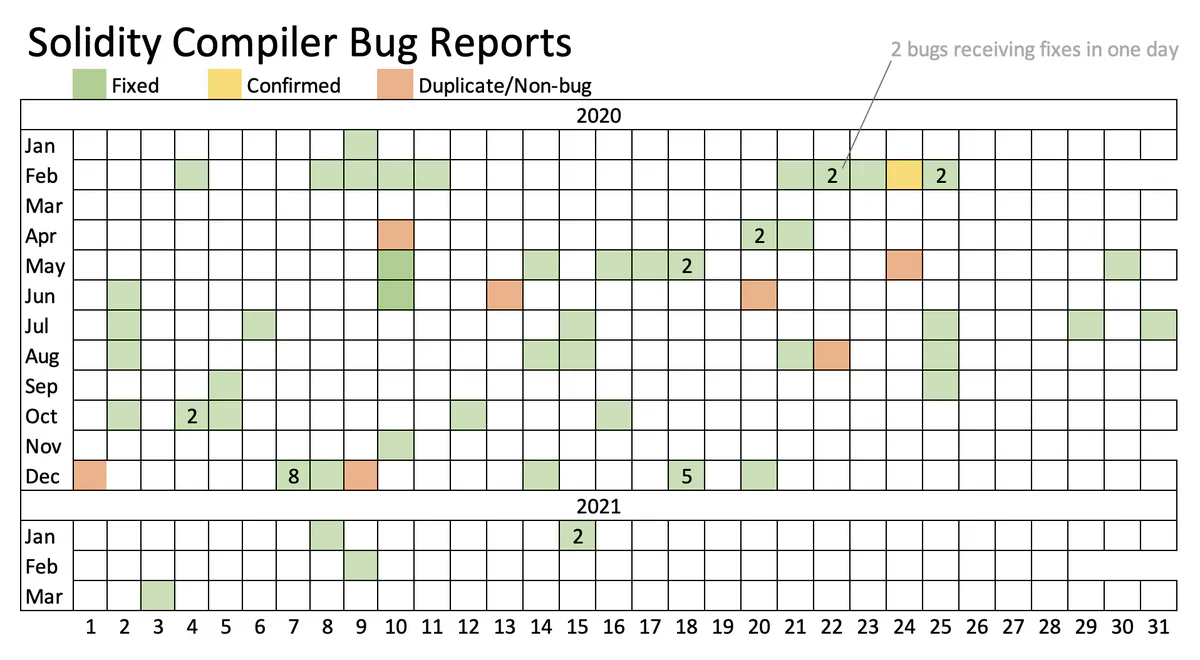
Given that 21 of these bugs were submitted since last December, it’s fair to say that our fuzzing campaign makes a strong case for why independent fuzzing is still important and can find different bugs, even when OSSFuzz-based testing is also involved.
Why is it useful to keep fuzzing such a project perhaps indefinitely? The answer has three parts. First, more fuzzing covers more code execution paths and long fuzzing runs are especially helpful. It would be hard to get anywhere near path-coverage saturation with any fuzzer we know of. Even when running afl for 30 or more days, our tests still find new paths around every 1-2 hours and sometimes find new edges. Some of our reported bugs were discovered only after a month of fuzzing.
A production compiler is fantastically complex, so fuzzing in-depth is useful. It takes time to generate inputs such as the most recent bug we found fuzzing the Solidity level of solc:
pragma experimental SMTChecker;
contract A {
function f() internal virtual {
v();
}
function v() internal virtual {
}
}
contract B is A {
function f() internal virtual override {
super.f();
}
}
contract C is B {
function v() internal override {
if (0==1)
f();
}
}This code should compile without error, but it didn’t. Until the bug was fixed, it caused the SMT Checker to crash, throwing a fatal “Super contract not available” error, due to incorrect contract context used for variable access in virtual calls inside branches.
Compilers should undergo fuzz testing for long stretches of time because of their complexity and number of possible execution paths. A rule of thumb is that afl hasn’t really started in earnest on any non-trivial target until it hits one million executions, and compilers likely require much more than this. In our experience, compiler runs vary anywhere from less than one execution per second to as many as 40 executions per second. Just getting to one million executions can take a few days!
The second reason we want to fuzz independently alongside OSSFuzz is to approach the target from a different angle. Instead of strictly using a dictionary- or grammar-based approach with traditional fuzzer mutation operators, we used ideas from any-language mutation testing to add “code-specific” mutation operators to afl, and rely mostly (but not exclusively) on those, as opposed to afl’s even more generic mutations, which tend to be focused on binary format data. Doing something different is likely going to be a good solution to fuzzer saturation.
Finally, we keep grabbing the latest code and start fuzzing on new versions of solc. Since the OSSFuzz continuous integration doesn’t include our techniques, bugs that are hard for other fuzzers but easy for our code-mutation approach will sometimes appear, and our fuzzer will find them almost immediately.
But we don’t grab every new release and start over, because we don’t want to lose the ground that was gained with our long fuzzing campaigns. We also don’t continually take up where we left off since the tens of thousands of test corpora that afl can generate are likely full of uninteresting paths that might make finding bugs in the new code easier. We sometimes resume from an existing run, but only infrequently.
Finding bugs in a heavily-fuzzed program like solc is not easy. The next best independent fuzzing effort to ours, that of Charalambos Mitropoulos, also mentioned by the solc team in their post of the OSSFuzz fuzzing, has only discovered 8 bugs, even though it’s been ongoing since October 2019.
Other Languages, Other Compilers
Our success with solc inspired us to fuzz other compilers. First, we tried fuzzing the Vyper compiler—a language intended to provide a safer, Python-like, alternative to Solidity for writing Ethereum blockchain smart contracts. Our previous Vyper fuzzing uncovered some interesting bugs using essentially a grammar-based approach with the TSTL (Template Scripting Testing Language) Python library via python-afl. We found a few bugs during this campaign, but chose not to go to extremes, because of the poor speed and throughput of the instrumented Python testing.
In contrast, my collaborator, Rijnard van Tonder at Sourcegraph, had much greater success fuzzing the Diem project’s Move language—the language for the blockchain formerly known as Facebook’s Libra. Here, the compiler is fast and the instrumentation is cheap. Rijnard has reported 14 bugs in the compiler, so far, all of which have been confirmed and assigned, and 11 of which have been fixed. Given that the fuzzing began just two months ago, this is an impressive bug haul!
Using Rijnard’s notes on fuzzing Rust code using afl.rs, I tried our tools on Fe, a new smart contract language supported by the Ethereum foundation. Fe is, in a sense, a successor to Vyper, but with more inspiration from Rust and a much faster compiler. I began fuzzing Fe on the date of its first alpha release and submitted my first issue nine days later.
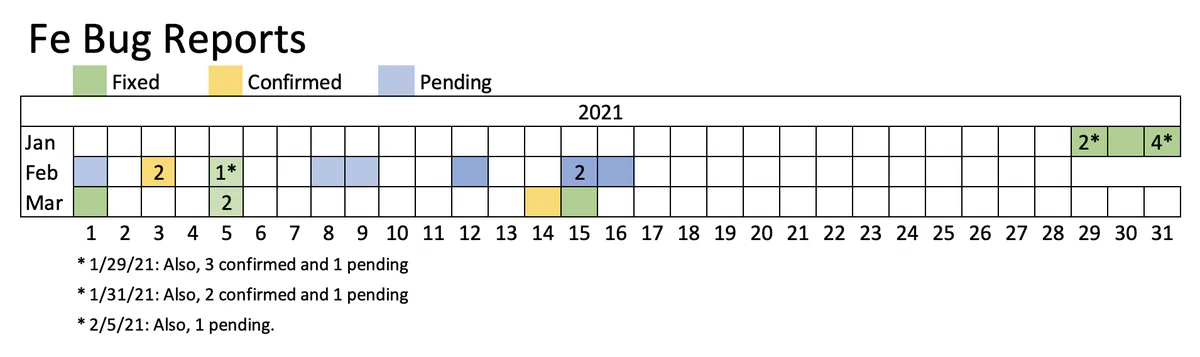
To support my fuzzing campaign, the Fe team changed failures in the Yul backend, which uses solc to compile Yul, to produce Rust panics visible to afl, and we were off to the races. So far, this effort has produced 31 issues, slightly over 18% of all GitHub issues for Fe, including feature requests. Of these, 14 have been confirmed as bugs, and ten of those have been fixed; the remaining bugs are still under review.
We didn’t just fuzz smart contract languages. Rijnard fuzzed the Zig compiler—a new systems programming language that aims at simplicity and transparency and found two bugs (confirmed, but not fixed).
The Future of Our Fuzzing Campaigns
We uncovered 88 bugs that were fixed during our afl compiler fuzzing campaign, plus an additional 14 confirmed, but not yet fixed bugs.
What’s interesting is that the fuzzers aren’t using dictionaries or grammars. They know nothing about any of these languages beyond what is expressed by a modest corpus of example programs from the test cases. So how can we fuzz compilers this effectively?
The fuzzers operate at a regular-expression level. They don’t even use context-free language information. Most of the fuzzing has used fast C string-based heuristics to make “code-like” changes, such as removing code between brackets, changing arithmetic or logical operators, or just swapping lines of code, as well as changing if statements to while and removing function arguments. In other words, they apply the kind of changes a mutation testing tool would. This approach works well even though Vyper and Fe aren’t very C-like and only Python’s whitespace, comma, and parentheses usage are represented.
Custom dictionaries and language-aware mutation rules may be more effective, but the goal is to provide compiler projects with effective fuzzing without requiring many resources. We also want to see the impact that a good fuzzing strategy can have on a project during the early stages of development, as with the Fe language. Some of the bugs we’ve reported highlighted tricky corner cases for developers much earlier than might have otherwise been the case. We hope that discussions such as this one will help produce a more robust language and compiler with fewer hacks made to accommodate design flaws detected too late to easily change.
We plan to keep fuzzing most of these compilers since the solc effort has shown that a fuzzing campaign can remain viable for a long time, even if there are other fuzzing efforts targeting the same compiler.
Compilers are complex and most are also rapidly changing. For example, Fe is a brand-new language that isn’t really fully designed, and Solidity is well-known for making dramatic changes to both user-facing syntax and compiler internals.
We’re also talking to Bhargava Shastry, who leads the internal fuzzing effort of Solidity, and applying some of the semantic checks they apply in their protobuf-fuzzing of the Yul optimization level ourselves. We started directly fuzzing Yul via solc’s strict-assembly option, and we already found one amusing bug that was quickly fixed and incited quite a bit of discussion! We hope that the ability to find more than just inputs that crash solc will take this fuzzing to the next level.
The issue at large is whether fuzzing is limited to the bugs it can find due to the inability of a compiler to detect many wrong-code errors. Differential comparison of two compilers, or of a compiler with its own output when optimizations are turned off, usually requires a much more restricted form of the program, which limits the bugs you find, since programs must be compiled and executed to compare results.
One way to get around this problem is to make the compiler crash more often. We imagine a world where compilers include something like a testing option that enables aggressive and expensive checks that wouldn’t be practical in normal runs, such as sanity-checks on register allocation. Although these checks would likely be too expensive for normal runs, they could be turned on for both some fuzzing runs, since the programs compiled are usually small, and, perhaps even more importantly, in final production compilation for extremely critical code (Mars Rover code, nuclear-reactor control code — or high-value smart contracts) to make sure no wrong-code bugs creep into such systems.
Finally, we want to educate compiler developers and developers of other tools that take source code as input, that effective fuzzing doesn’t have to be a high-cost effort requiring significant developer time. Finding crashing inputs for a compiler is often easy, using nothing more than some spare CPU cycles, a decent set of source code examples in the language, and the afl-compiler-fuzzer tool!
We hope you enjoyed learning about our long-term compiler fuzzing project, and we’ve love to hear about your own fuzzing experiences on Twitter @trailofbits.