
Un-bee-lievable Performance: Fast Coverage-guided Fuzzing with Honeybee and Intel Processor Trace
Today, we are releasing an experimental coverage-guided fuzzer called Honeybee that records program control flow using Intel Processor Trace (IPT) technology. Previously, IPT has been scrutinized for severe underperformance due to issues with capture systems and inefficient trace analyses. My winter internship focused on working through these challenges to make IPT-based fuzzing practical and efficient.
IPT is a hardware feature that asynchronously records program control flow, costing a mere 8-15% overhead at record time. However, applying IPT as a fuzzing coverage mechanism isn’t practical except for highly experimental binary-only coverage solutions, since source code instrumentation typically provides far better performance. Honeybee addresses this limitation and makes IPT significantly faster to capture and hundreds of times faster to analyze. So now we have coverage-guided fuzzing—even if source code is unavailable—at performances competitive with, and sometimes faster than, source-level coverage instrumentation. Here, I will describe the development process behind Honeybee and a general overview of its design.
How it started…
IPT is an Intel-specific processor feature that can be used to record the full control flow history of any process for minutes at a time with a minimal performance penalty. IPT drastically improves on Intel’s older hardware tracing systems such as Branch Trace Store, which can have a performance penalty exceeding 100%. Even better, IPT supports the granular selection of the trace target by a specific process or range of virtual addresses.
A hardware mechanism like IPT is especially alluring for security researchers because it can provide code coverage information for closed-source, unmodified target binaries. A less appreciated fact is that not only can IPT be much faster than any existing black-box approaches (like QEMU, interrupts, or binary lifting), IPT should also be faster than inserting source-level instrumentation.
Coverage instrumentation inhibits run-time performance by thrashing various CPU caches via frequent, random writes into large coverage buffers. Source-level instrumentation also inhibits many important compile-time optimizations, like automatic vectorization. Further, due to the multi-threaded nature of most programs, instrumentation code needs to operate on bitmaps atomically, which significantly limits pipeline throughput.
IPT should work on both closed source and open source software with no change in coverage generation strategy and incur only a minimal 8-15% performance penalty. Jaw-dropping, I tell you!
How it’s going…
Unfortunately, the 8-15% performance penalty doesn’t tell the whole story. While IPT has low capture overhead, it does not have a low analysis overhead. To capture long traces on commodity hardware, IPT uses various techniques to minimize the amount of data stored per trace. One technique is to only record control flow information not readily available from static analysis of the underlying binary, such as taken/not-taken branches and indirect branch targets. While this optimization assumes the IPT decoder has access to the underlying program binary, this assumption is often correct. (See Figure 1 for example.)
IPT is a very dense binary format. To showcase what information is stored, I’ve converted it to a more readable format in Figure 1. The packet type is in the left column and the packet payload is on the right.
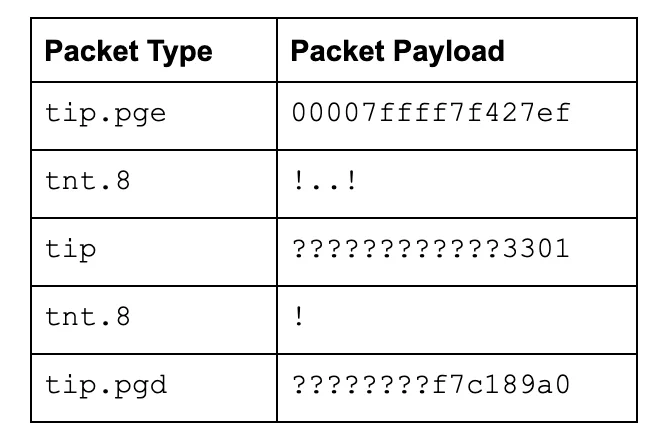
- Tracing starts while the program executes at 0x7ffff7f427ef.
- The program hits a conditional branch and accepts it. (The first ! in line 2.)
- The program hits two conditional branches and does not accept them. (The . . in line 2.)
- The program hits a conditional branch and does not accept it. (The last ! in line 2.)
- The program hits a conditional branch and accepts it. (Line 4.)
- The program hits an indirect branch, at which point it jumps to the last instruction pointer with the lower two bytes replaced with 0x3301.
- The program hits a conditional branch and accepts it.
- The program continued with no other conditional/indirect branches until the last four bytes of the instruction pointer were 0xf7c189a0 at which point tracing stopped because the program either exited or another piece of code that did not match the filters began executing.
Despite all the trace data provided, there is still a surprising amount of information that is omitted. The trace provides its beginning virtual address, eventual conditional branches, and whether they are taken. However, unconditional and unquestionable control flow transfers (i.e. call and jmp instructions) and conditional branch destinations are not provided. This reduces the trace size, because 1) non-branching code is never recorded, 2) conditional branches are represented as a single bit, and 3) indirect branches are only represented by changes to the instruction pointer.
So how is the real control flow reconstructed from this partial data? An IPT decoder can pair trace data with the underlying binary and “walk” through the binary from the trace start address. When the decoder encounters a control flow transfer that can’t be trivially determined, like a conditional branch, it consults the trace. Data in the trace indicates which branches were taken/not taken and the result of indirect control flow transfers. By walking the binary and trace until the trace ends, a decoder can reconstruct the full flow.
But herein lies the gotcha of IPT: although capture is fast, walking through the code is ostensibly not, because the decoder must disassemble and analyze multiple x86-64 instructions at every decoding step. While overhead for disassembly and analysis isn’t a problem for debugging and profiling scenarios, it severely hampers fuzzing throughput. Unfortunately, such expensive analysis is fundamentally unavoidable as traces cannot be decoded without analyzing the original program.
But…is this the end? Was it the beautiful promise of IPT fuzzing just…a dream? A mere illusion? Say it ain’t so!
Making IPT faster
While profiling Intel’s reference IPT decoder, libipt, I noticed that over 85% of the CPU time was spent decoding instructions during a trace analysis. This is not surprising given that IPT data must be decoded by walking through a binary looking for control flow transfers. An enormous amount of time spent during instruction decoding, however, is actually good news.
Why? A fuzzer needs to decode a multitude of traces against the same binary. It may be reasonable to continuously analyze instructions for a single trace of one binary, but re-analyzing the same instructions millions of times for the same binary is extraordinarily wasteful. If your “hey we should probably use a cache” sense is tingling, you’re totally right! Of course, the importance of instruction decode caches is not a novel realization.
An open-source decoder that claims to be the fastest IPT decoder (more on that later) named libxdc tries to solve this issue using a fast runtime cache. Using a runtime cache and other performance programming techniques, libxdc operates 10 to 40 times faster than Intel’s reference decoder, which demonstrates that caching is very important.
I thought I could do better though. My critique of libxdc was that its dynamic instruction cache introduced unnecessary and expensive overhead in two ways. First, a dynamic cache typically has expensive lookups, because it needs to calculate the target’s hash and ensure that the cache is actually a hit. This introduces more overhead and complexity to one of the hottest parts of the entire algorithm and cannot be overlooked.
Second, and frankly much worse, is that a dynamic cache is typically expected to fill and evict older results. Even the best cache eviction strategy will cause future work: Any evicted instructions will eventually need to be re-decoded because a fuzzer never targets code just once. This creates duplicated effort and decoder performance penalties with every single cache eviction
My idea was to introduce a static, ahead-of-time generated cache that holds all data IPT decoding that could conceivably require. The cache would be shared between multiple threads without penalty and could be accessed without expensive hashing or locking. By entirely eliminating binary analysis and cache access overhead, I could decode traces significantly faster than libxdc, because my decoder would simply be doing less work.
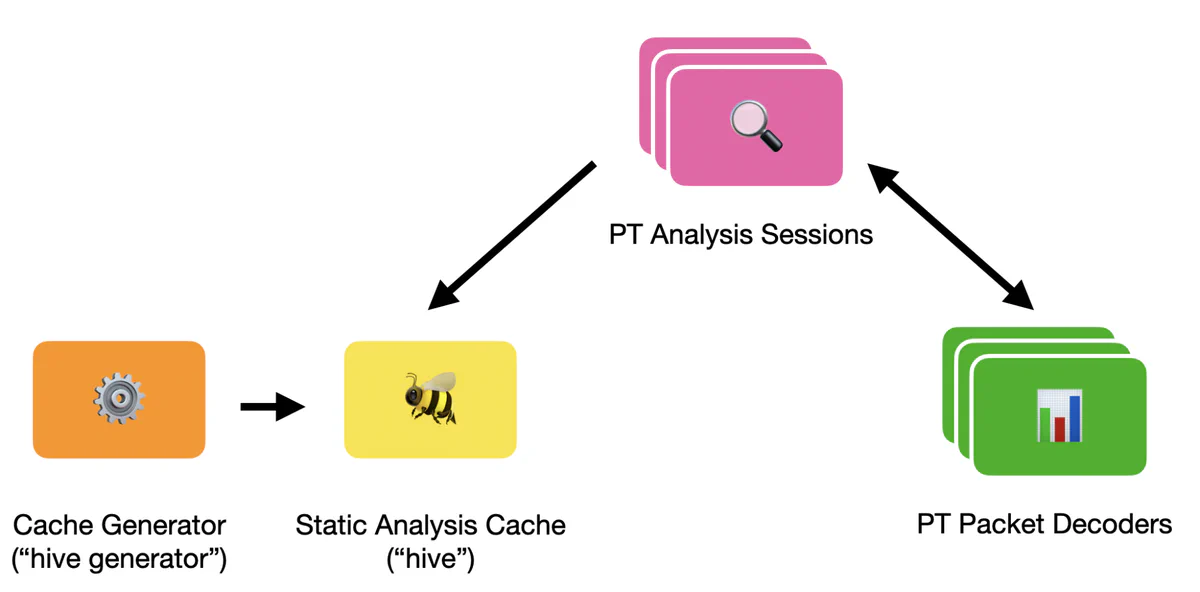
Keeping with the theme of Honeybee, I named these static, ahead-of-time generated caches “hives” since they require work to create but only need to be made once. To make the hives, I created hive_generator, which consumes an ELF executable and captures information that may be needed to decode a trace. The hive_generator searches for all control flow instructions and generates an extremely compact encoding of all basic blocks and where code execution could continue. There are two important features of this new design worth discussing. (Full details are available on Github.)
First, this encoding is data cache-friendly, because not only are blocks the size of cache lines, encoded blocks are stored in the same order as the original binary, which is a small important detail. It means that Honeybee’s decoder can take full advantage of the original binary’s cache locality optimization since compilers generally put relevant basic blocks close to each other. This is not generally possible in dynamic caches, like in libxdc, since the cache’s hash function by design will send neighboring blocks to random locations. This is harmful to performance because it evicts meaningful data from the CPU’s data cache.
The other important feature is that blocks are encoded in a bitwise-friendly format, so Honeybee can process the compacted blocks using exclusively high-throughput ALU operations. This design makes several critical operations completely branchless — like determining whether a block ends in a direct, indirect, or conditional branch. Combining this with high-throughput ALU operations avoids many costly branch mispredictions and pipeline purges.
These changes seemed relatively trivial, but I hoped that they would combine to a respectable performance boost over the current state of the art, libxdc.
Honeybee decoder benchmarks
To compare the performance of Honeybee’s decoder with Intel’s reference decoder, I ran traces ranging from tens of kilobytes up to 1.25 GB among binaries of sizes of 100 kb to 45 MB. Tests were performed 25 times, and I verified that both decodes traveled identical control flow paths for the same trace files.
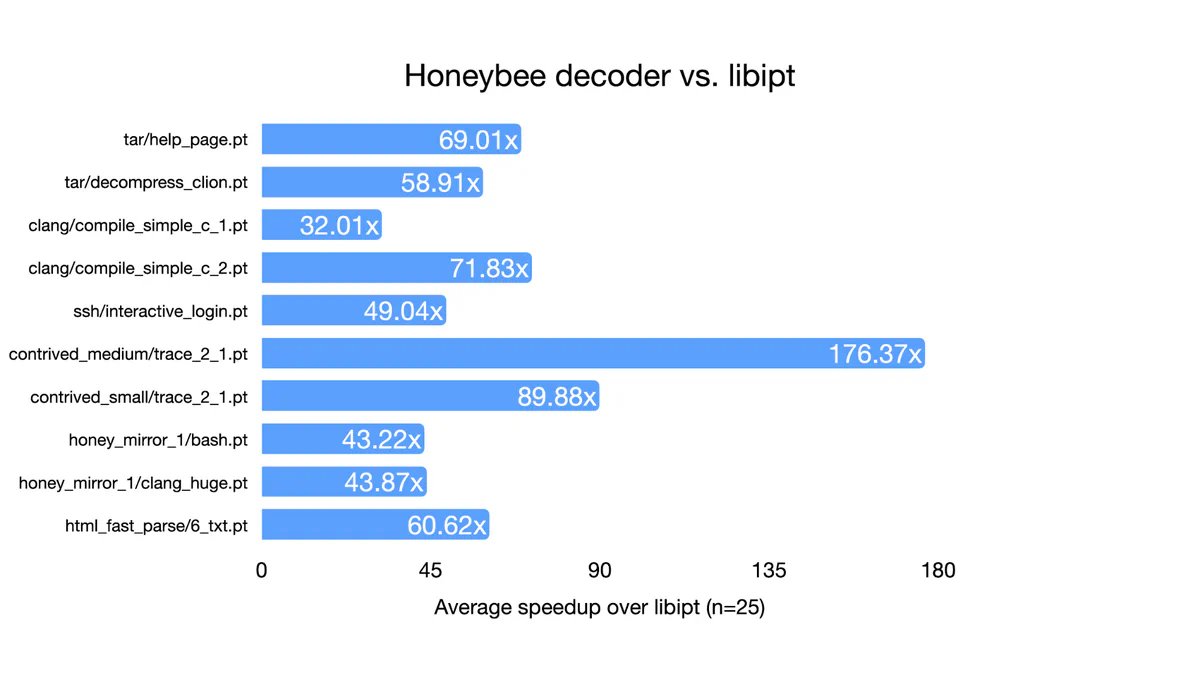
These tests showed promising results (Figure 3). On large programs like clang, Honeybee outperformed Intel’s reference decode and libxdc by an order of magnitude (and two orders of magnitude in one case).
For context, the largest trace in this test suite, “honey_mirror_1/clang_huge.pt,” is 1.25GB and originates from a trace of a complicated static analysis program that disassembled the entire 35MB clang binary.
Honeybee takes only 3.5 seconds to do what Intel’s reference decoder does in two-and-a-half minutes, which is a 44x improvement! This is the difference between stepping away while the trace decodes and being able to take a sip of water while you wait.
This difference is even more pronounced on small traces, which are more similar to fuzzing loads like “html_fast_parse/6_txt.pt.” In this case, Honeybee needed only 6.6 microseconds to finish what Intel’s reference coder took 451 microseconds to do. An order of magnitude improvement!
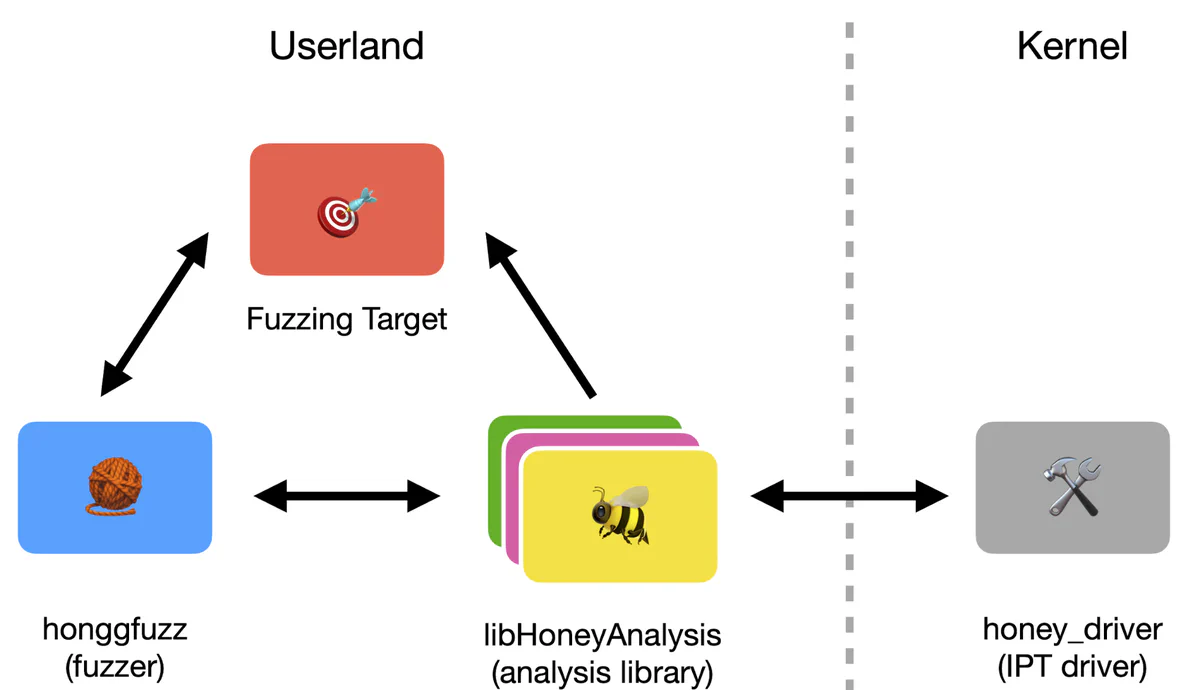
Now to actually integrate this new coverage mechanism into a fuzzer. I chose Google’s honggfuzz since it’s modular and, notably, because it actually already has another slow and partially broken version of IPT-based coverage that uses Intel’s reference decoder. My plan was to simply rip out Intel’s decoder, bolt Honeybee in place, and get a wonderful speedup. However, this was more complicated than I expected.
The challenge is how Linux typically collects IPT data, which is meant to be fairly simple since the mainline kernel actually has support for IPT built right into perf. But I discovered that the complex and aggressive filtering mechanisms that Honeybee needs to clean up IPT data expose stability and performance issues in perf.
This was problematic. Not only was perf not terribly fast to begin with, but it was highly unstable. Complex configurations used by Honeybee triggered serious bugs in perf which could cause CPUs to be misconfigured and require a full system reboot to recover from lockup. Understandably, both of these issues ultimately made perf unusable for capturing IPT data for any Honeybee-related fuzzing tasks.
But, as my mother says, if you want something done right, sometimes you just need to do it yourself. Following in her footsteps, I wrote a small kernel module for IPT named “honey_driver” that was specifically optimized for fuzzing. While this new kernel module is certainly less featureful than perf and a likely security hazard, honey_driver is extremely fast and enables a user-space client to rapidly reconfigure tracing and analyze the results with little overhead.
And so, with this small constellation of custom code, honggfuzz was ready to roll with IPT data from Honeybee!
Fuzzer benchmarks
Fuzzer performance measurement is complex and so there are many more reliable and definitive means to measure performance. As a rough benchmark, I persistently fuzzed a small HTML parser using four different coverage strategies. Then, I allowed honggfuzz to fuzz the binary using the chosen coverage technique before recording the average number of executions over the test period.
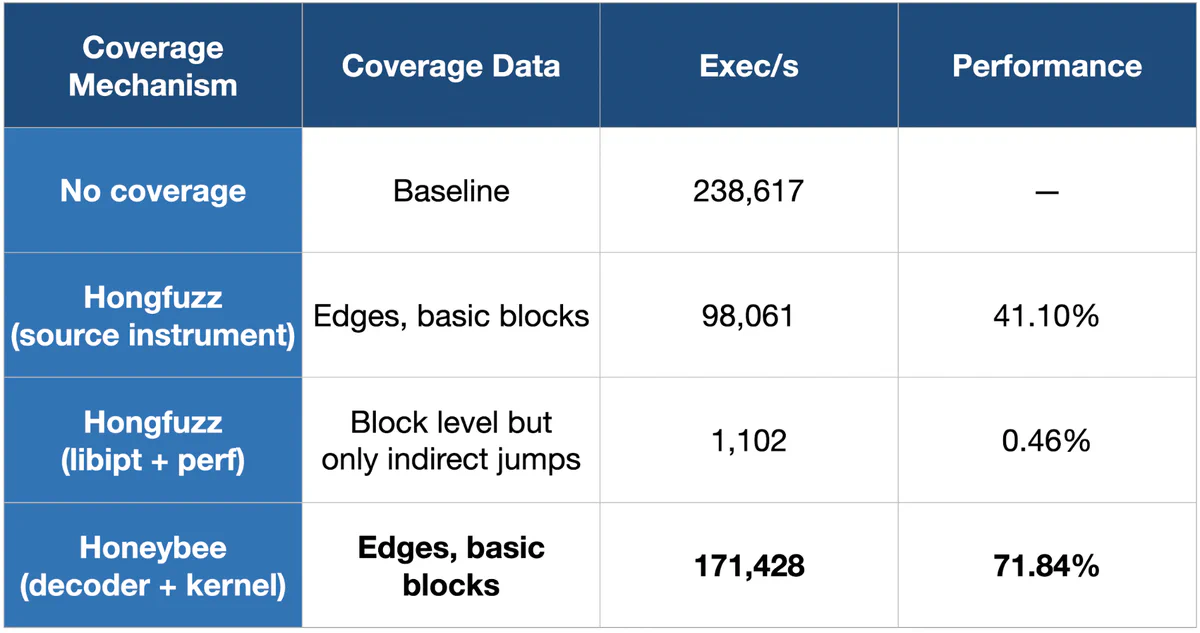
The first contender in the experiment was no coverage whatsoever. I considered this to be the baseline since it’s essentially as fast as honggfuzz can run on this binary by feeding random input into the test program. In this configuration, honggfuzz achieved an average of 239K executions per second. In the context of my system, this is decently fast but is still certainly limited by the fuzzing target’s CPU performance.
Next, I tested honggfuzz’s source-level software instrumentation by compiling my target using the instrumenting compiler with no other features enabled. This led to an average of 98K executions per second or a 41% drop in efficiency compared to the no coverage baseline, which is a generally accepted and expected penalty when fuzzing due to missed compiler optimizations, many function calls, expensive locking, and cache thrashing due to essentially random writes into coverage bitmaps.
After software instrumentation, we get into the more interesting coverage techniques. As mentioned earlier, honggfuzz has support for processor trace using libipt for analysis and unfiltered perf data for IPT capture. However, honggfuzz’s existing IPT support does not generate full or even possibly correct coverage information, because honggfuzz only extracts indirect branch IPs from the trace and completely ignores any conditional branches. Additionally, since no filtering is employed using perf, honggfuzz generates coverage for every piece of code in the process, including uninteresting libraries like libc. And this leads to bitmap pollution.
Even with these shortcuts, honggfuzz’s existing IPT can only achieve an average of 1.1K executions per second (roughly half of a percent of the theoretical max). Due to the inaccurate coverage data, a true comparison cannot be made to software instrumentation, because it is possible that it found a more difficult path sooner. Realistically, however, the gap is so enormous that such an issue is unlikely to account for most of the overhead given the previously established performance issues of both perf and libipt.
Lastly, we have Honeybee with its custom decoder and capture system. Unlike the existing honggfuzz implementation, Honeybee decodes the entire trace and so it is able to generate a full, correct basic block and edge coverage information. Honeybee achieved an average of 171K executions per second, which is only a 28% performance dip compared to the baseline.
This shouldn’t come as a shock, since IPT only has an 8-15% record time overhead. This leaves 14-21% of the baseline’s total execution time to process IPT data and generate coverage. Given the incredible performance of Honeybee’s decoder and its ability to quickly decode traces, it is entirely reasonable to assume that the total overhead of Honeybee’s data processing could add up to a 29% performance penalty.
I analyzed Honeybee’s coverage and confirmed that it was operating normally and processing all the data correctly. As such, I’m happy to say that Honeybee is (at least in this case) able to fuzz both closed and open-source software faster and more efficiently than even conventional software instrumentation methods!
What’s next?
While it is very exciting to claim to have dethroned an industry-standard fuzzing method, these methods have not been rigorously tested or verified at a large scale or across a large array of fuzzing targets. I can attest, however, that Honeybee has been either faster or at least able to trade blows with software instrumentation while fuzzing many different large open source projects like libpcap, libpng, and libjpegturbo.
If these patterns apply more generally, this could mean a great speedup for those who need to perform source-level fuzzing. More excitingly, however, this is an absolutely wonderful speedup for those who need to perform black-box fuzzing and have been relying on slow and unreliable tools like QEMU instrumentation, Branch Trace Store (BTS), or binary lifting, since it means they can fuzz at equal or greater speeds than if they had source without making any serious compromises. Even outside fuzzing, however, Honeybee is still a proven and extraordinarily fast IPT decoder. This high-performance decoding is useful outside of fuzzing because it enables many novel applications ranging from live control flow integrity enforcement to more advanced debuggers and performance analysis tools.
Honeybee is a very young project and is still under active development in its home on GitHub. If you’re interested in IPT, fuzzing, or any combination thereof please feel free to reach out to me over on Twitter where I’m @ezhes_ or over email at allison.husain on the berkeley.edu domain!
Acknowledgments
As mentioned earlier, IPT has caught many researchers’ eyes and so, naturally, many have tried to use it for fuzzing. Before starting my own project, I studied others’ research to learn from their work and see where I might be able to offer improvements. I’d first like to acknowledge the authors behind PTrix (PTrix: Efficient Hardware-Assisted Fuzzing for COTS Binary) and PTfuzz (PTfuzz: Guided Fuzzing With Processor Trace Feedback) as they provided substantial insight into how a fuzzer could be structured around IPT data. Additionally, I’d like to thank the team behind libxdc as their fast IPT packet decoder forms the basis for the packet decoder in Honeybee. Finally, I’d like to give a big thank you to the team at Trail of Bits, and especially my mentors Artem Dinaburg and Peter Goodman, for their support through this project and for having me on as an intern this winter!