
High-fidelity build instrumentation with blight
TL;DR: We’re open-sourcing a new framework, blight, for painlessly wrapping and instrumenting C and C++ build tools. We’re already using it on our research projects, and have included a set of useful actions. You can use it today for your own measurement and instrumentation needs:

Why would you ever want to wrap a build tool?
As engineers, we tend to treat our build tools as monoliths: gcc, clang++, et al. are black boxes that we shove inputs into and get outputs out of.
We then encapsulate our build tools in even higher-level build systems (Make, Ninja) or build system generators (CMake) to spare ourselves the normal hassles of C and C++ compilation: linking individual outputs together, maintaining consistent flags between invocations, supplying the correct linker and including directories, etc.
This all works well enough for everyday development, but falls short for a few specific use cases. We’ll cover some of them below.
Caching
Most build systems have their own caches and intermediate management mechanisms (with varying degrees of soundness). What normal build systems can’t do is cache intermediates between separate projects: Each project’s build is hermetic, even when two projects build nearly identical source dependencies.
That’s where tools like ccache and sccache come in: both supply a global intermediate cache by wrapping individual build tools and diverting from a normal tool invocation if a particular input’s output already exists1.
Static analysis
Modern C and C++ compilers support a variety of language standards, as well as customization flags for allowing or disallowing language features. Static analysis tools like clang-tidy need to be at least partially aware of these parameters to provide accurate results; for instance, they shouldn’t be recommending snprintf for versions of C prior to C99. Consequently, these tools need an accurate record of how the program was compiled.
clang-tidy and a few other tools support a Compilation Database format, which is essentially just a JSON-formatted array of “command objects,” each of contains the command-line, working directory, and other metadata associated with a build tool invocation. CMake knows how to generate these databases when using its Make generator; there’s also a tool called Bear that does the same through some LD_PRELOAD trickery.
Similarly: LLVM is a popular static analysis target, but it can be difficult to generically instrument pre-existing build systems to emit a single LLVM IR module (or individual bitcode units) in lieu of a single executable or object intermediates. Build tool wrappers like WLLVM and GLLVM exist for precisely this purpose.
Performance profiling
C and C++ builds get complicated quickly. They also tend to accumulate compilation performance issues over time:
- Expensive standard headers (like
<regex>) get introduced and included in common headers, bloating compilation times for individual translation units. - Programmers get clever and write complex templates and/or recursive macros, both of which are traditional sore points in compiler performance.
- Performance-aiding patterns (like forward declarations) erode as abstractions break.
To fix these performance problems, we’d like to time each individual tool invocation and look for sore points. Even better, we’d like to inject additional profiling flags, like -ftime-report, into each invocation without having to fuss with the build system too much. Some build systems allow the former by setting CC=time cc or similar, but this gets hairy with multiple build systems tied together. The latter is easy enough to do by modifying CFLAGS in Make or add_compile_options /target_compile_options in CMake, but becomes similarly complicated when build systems are chained together or invoke each other.
Build and release assurance
C and C++ are complex languages that are hard, if not impossible, to write safe code in.
To protect us, we have our compilers add mitigations (ASLR, W^X, Control Flow Integrity) and additional instrumentation (ASan, MSan, UBSan).
Unfortunately, build complexity gets in our way once again: when stitching multiple builds together, it’s easy to accidentally drop (or incorrectly add, for release configurations) our hardening flags2. So, we’d like a way to predicate a particular build’s success or failure on the presence (or absence) of our desired flags, no matter how many nested build systems we invoke. That means injecting and/or removing flags just like with performance profiling, so wrapping is once again an appealing solution.
Build tools are a mess
We’ve come up with some potential use cases for a build tool wrapper. We’ve also seen that a useful build tool wrapper is one that knows a decent bit about the command-line syntax of the tool that it’s wrapping: how to reliably extract its inputs and outputs, as well as correctly model a number of flags and options that change the tool’s behavior.
Unfortunately, this is easier said than done:
GCC, historically the dominant open-source C and C++ compiler, has thousands of command-line options, including hundreds of OS- and CPU-specific options that can affect code generation and linkage in subtle ways. Also, because nothing in life should be easy, the GCC frontends have no less than four different syntaxes for an option that takes a value:
-oVALUE(examples:-O{,0,1,2,3},-ooutput.o,-Ipath)-flag VALUE(examples:-o output.o,-x c++)-flag=VALUE(examples:-fuse-ld=gold,-Wno-error=switch,-std=c99)-Wx,VALUE(examples:-Wl,--start-group,-Wl,-ereal_main)
Some of these overlap consistently, while others only overlap in a few select cases. It’s up to the tool wrapper to handle each, at least to the extent required by the wrapper’s expected functionality.
Clang, the (relative) newcomer, makes a strong effort to be compatible with the
gccandg++compiler frontends. To that end, most of the options that need to be modeled for correctly wrapping GCC frontends are the same for the Clang frontends. That being said,clangandclang++add their own options, some of which overlap in functionality with the common GCC ones. By way of example: Theclangandclang++frontends support-Ozfor aggressive code size optimization beyond the (GCC-supported)-Os.Finally, the weird ones: There’s Intel’s ICC, which apparently likewise makes an effort to be GCC-compatible. And then there’s Microsoft’s
cl.exefrontend for MSVC which, to the best of my understanding, is functionally incompatible3.
Closer inspection also reveals a few falsehoods that programmers frequently believe about their C and C++ compilers:
“Compilers only take one input at a time!”
This is admittedly less believed: Most C and C++ programmers realize early on that these invocations…
cc -c -o foo.o foo.c
cc -c -o bar.o bar.c
cc -c -o baz.o baz.c
cc -o quux foo.o bar.o baz.o…can be replaced with:
cc -o quux foo.c bar.c baz.cThis is nice for quickly building things on the command-line, but is less fruitful to cache (we no longer have individual intermediate objects) and is harder for a build tool wrapper to model (we have to suss out the inputs, even when interspersed with other compiler flags).
“Compilers only produce one output at a time!”
Similar to the above: C and C++ compilers will happily produce a single intermediate output for every input, as long as you don’t explicitly ask them for a single executable output via -o:
cc -c foo.c bar.c baz.c…produces foo.o, bar.o, and baz.o. This is once again nice for caching, but with a small bit of extra work. To correctly cache each output, we need to transform each input’s filename into the appropriate implicit output name. This ought to be as simple as replacing the source extension with .o, but it isn’t guaranteed:
- Windows hosts (among others) use
.objrather than.o. Annoying. - As we’ll see, not all source inputs are required to have an extension.
Yet more work for our tool wrapper.
“cc only compiles C sources and c++ only compiles C++ sources!”
This is a popular misconception: that cc and c++ (or gcc and g++, or …) are completely different programs that happen to share a great deal of command-line functionality.
In reality, even if they’re separate binaries, they’re usually just thin shims over a common compiler frontend. In particular, c++ corresponds to cc -x c++ and cc corresponds to c++ -x c:
# compile a C++ program using cc
cc -x c++ -c -o foo.o foo.cppThe -x <language> option enables one particularly annoying useful feature: being able to compile files as a particular language even if their suffix doesn’t match. This comes in handy when doing, say, code generation:
# promise the compiler that junk.gen is actually a C source file
cc -x c junk.gen“Compilers only compile one language at a time!”
Even with the above, programmers assume that each input to the compiler frontend has to be of the same language, i.e., that you can’t mix C and C++ sources in the same invocation. But this just isn’t true:
# compile a C source and a C++ source into their respective object files
cc -c -x c foo.c -x c++ bar.cppYou don’t even need the -x <language> modifiers when the frontend understands the file suffixes, as it does for .c and .cpp:
# identical to the above
cc -c foo.c bar.cppNot every build tool is a compiler frontend
We’ve omitted a critical fact above: Not every build tool shares the general syntax of the C and C++ compiler frontends. Indeed, there are five different groups of tools that we’re interested in:
- “Compiler tools” like
ccandc++, normally overriden withCCandCXX. We’re focusing our efforts on C and C++ for the time being; it’s common to see similar variables for Go (GO), Rust (RUSTC), and so forth. - The C preprocessor (
cpp), normally overriden withCPP. Most builds invoke the C preprocessor through the compiler frontend, but some invoke it directly. - The system linker (
ld), normally overriden withLD. Like the preprocessor, the linker is normally interacted with through the frontend, but occasionally makes an appearance of its own when dealing with custom toolchains and linker scripts. - The system assembler (
as), normally overriden withAS. Can be used via the frontend like the preprocessor and linker, but is also seen independently. - The system archiver (
ar), normally overriden withAR. Unlike the last three, the archiver is not integrated into the compiler frontend for, e.g., static library construction; users are expected to invoke it directly.
blight’s architecture
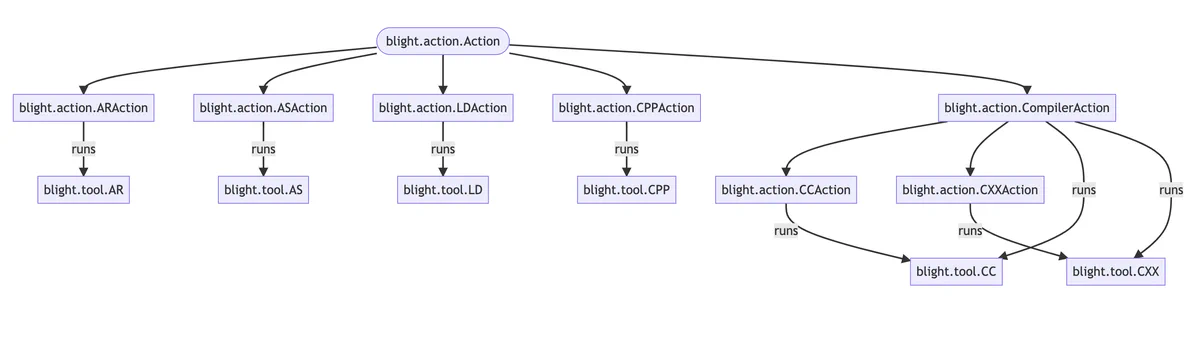
We’ve seen some of the complexities that arise when wrapping and accurately modeling the behavior of a build tool. So now let’s take a look at how blight mitigates those complexities.
Like most (all?) build tool wrappers, blight’s wrappers take the place of their wrapped counterparts. For example, to run a build with blight’s C compiler wrapper:
# -e tells make to always give CC from the environment precedence
CC=blight-cc make -eSetting each CC, CXX, etc. manually is tedious and error-prone, so the blight CLI provides a bit of shell code generation magic to automate the process:
# --guess-wrapped searches the $PATH to find a suitable tool to wrap
eval "$(blight-env --guess-wrapped)"
make -eUnder the hood, each blight wrapper corresponds to a concrete subclass of Tool (e.g., blight.tool.AS for the assembler), each of which has at least the following:
- The argument vector (
args) that the wrapped tool will be run with. - The working directory (
cwd) that the wrapped tool will be run from. - A list of
Actions, each of which can register two separate events on each tool run:before_run(tool)—Run before each tool invocation.after_run(tool)—Run after each successful tool invocation.
Individual subclasses of Tool are specialized using a mixin pattern. For example, blight.tool.CC…
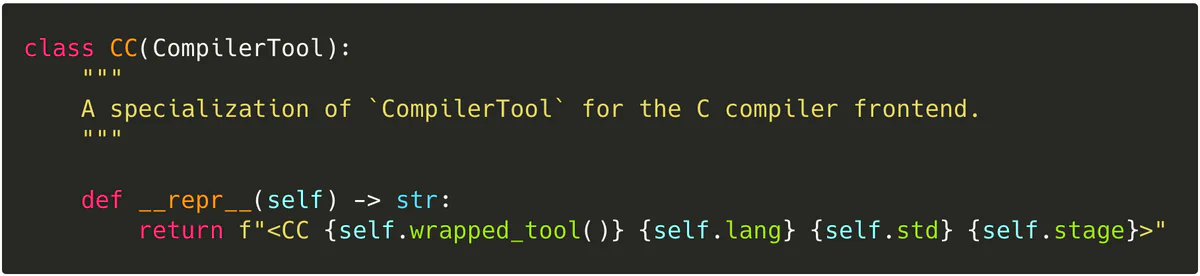
…specializes CompilerTool, which is a doozy of mixins:
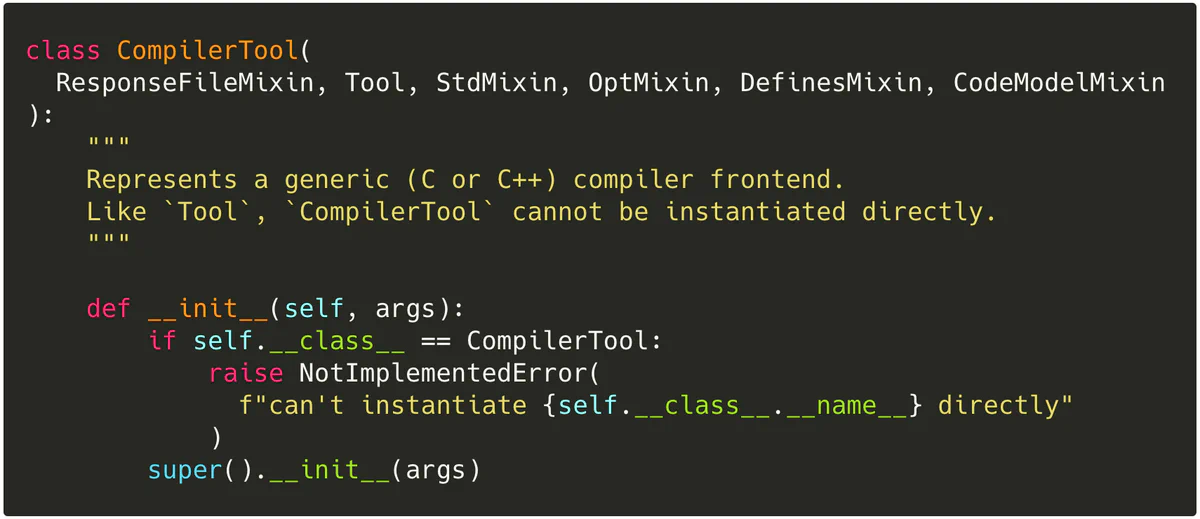
Each mixin, in turn, provides some modeled functionality common between one or more tools.
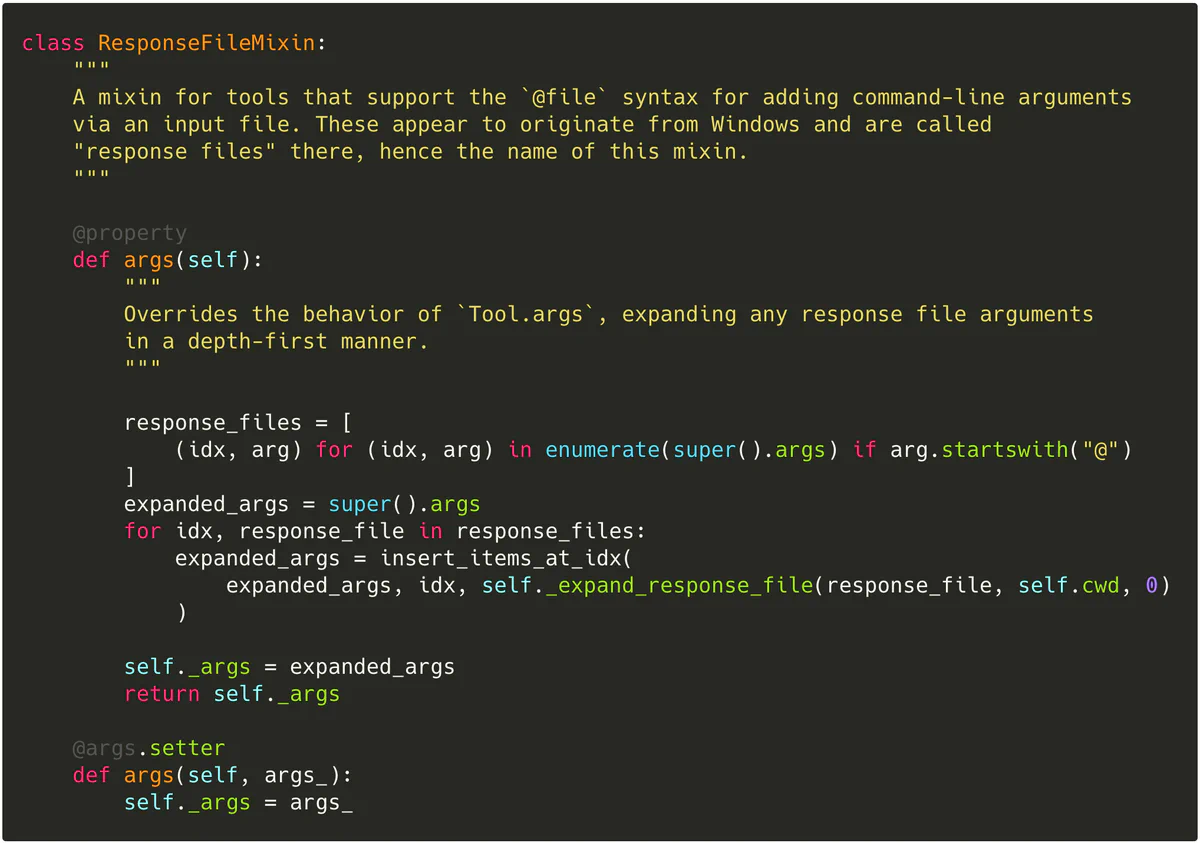
ResponseFileMixin, for example, specializes the behavior of Tool.args for tools that support the @file syntax for supplying additional arguments via an on-disk file (in particular, CC, CXX, and LD):
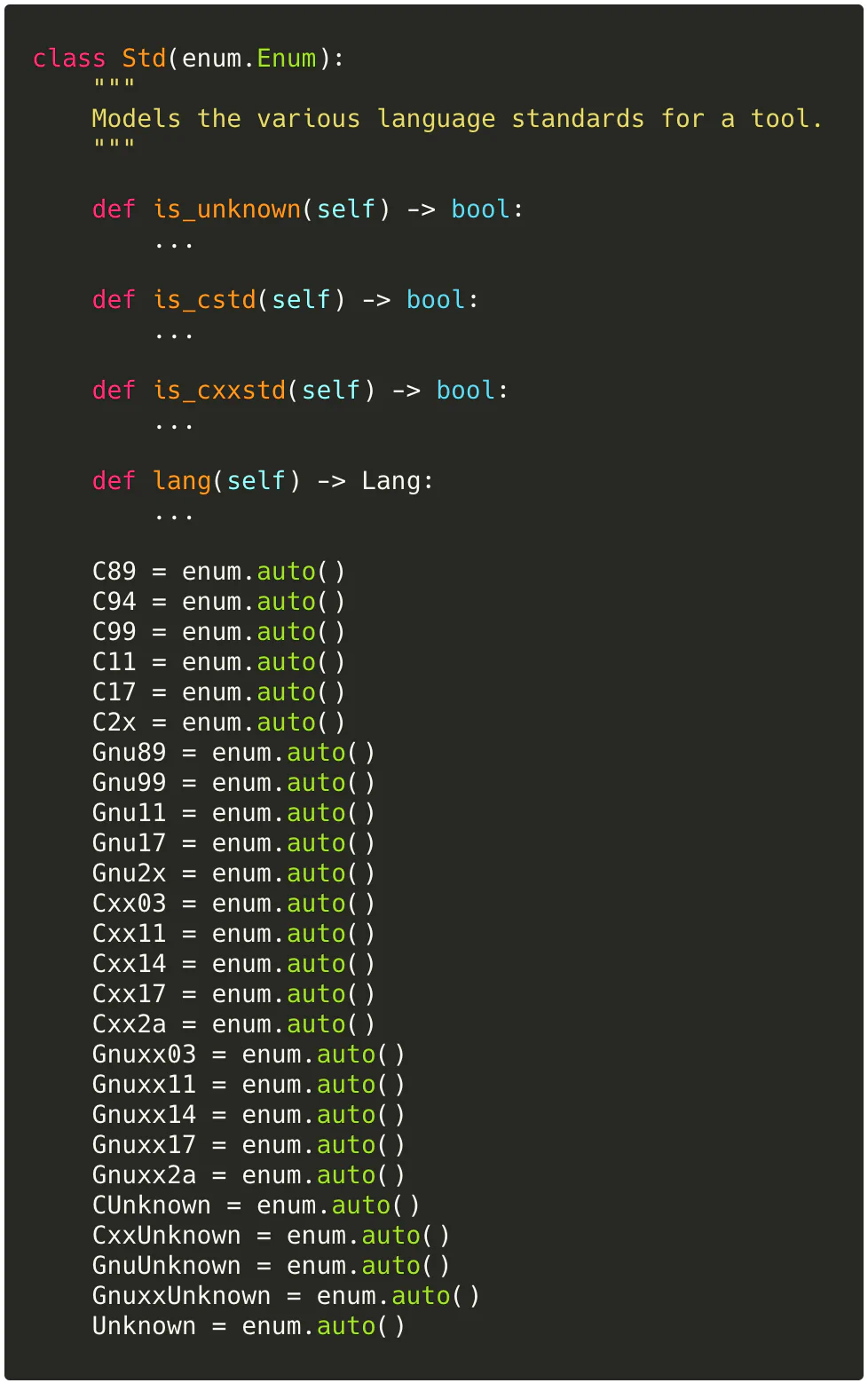
Other mixins make heavy use of Python 3’s Enum class to strictly model the expected behavior of common tool flags, like -std=STANDARD…

…where Std:
Taking action
By default, blight does absolutely nothing: it’s just a framework for wrapping build tools. The magic happens when we begin to inject actions before and after each tool invocation.
Internally, the actions API mirrors the tool API: Each tool has a corresponding class under blight.action (e.g., CC → CCAction):
To add an action, you just specify its name in the BLIGHT_ACTIONS environment variable. Multiple actions can be specified with : as the delimiter, and will be executed in a left-to-right order. Only actions that “match” a particular tool are run, meaning that an action with CCAction as its parent will never (incorrectly) run on a CXX invocation.
To bring the concepts home, here’s blight running with two stock actions: IgnoreWerror and InjectFlags:

In this case, IgnoreWerror strips any instances of –Werror that it sees in compiler tools (i.e., CC and CXX), while InjectFlags injects a configurable set of arguments via a set of nested variables. We’ll see how that configuration works in a bit.
For example, here’s InjectFlags:
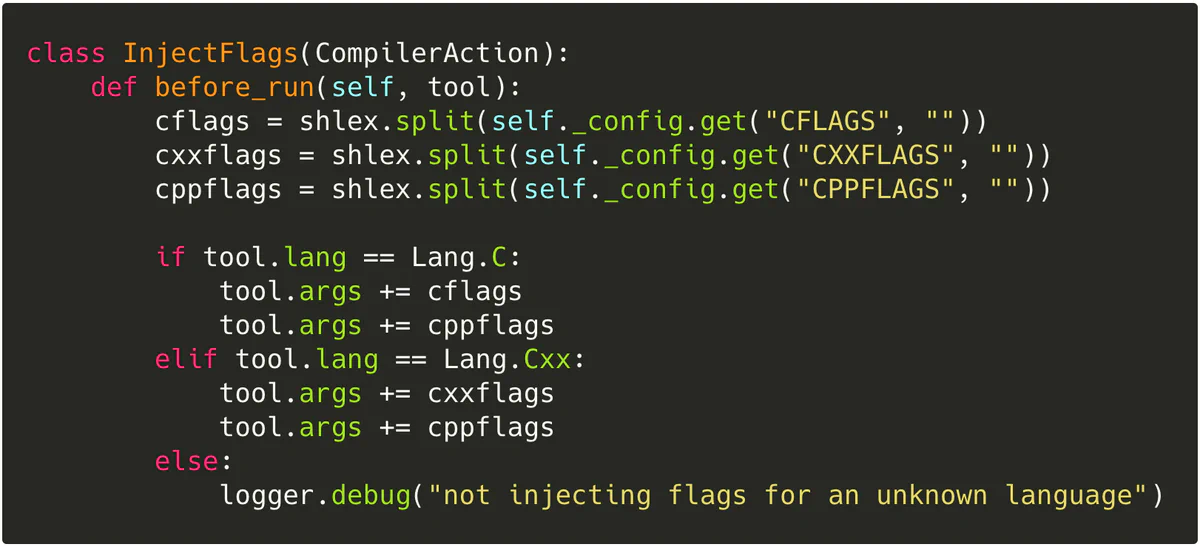
In particular, note that InjectFlags is a CompilerAction, meaning that its events (in this case, just before_run) are only executed if the underlying tool is CC or CXX.
Writing and configuring your own actions
Writing a new action is straightforward: They live in the blight.actions module, and all inherit from one of the specializations of blight.action.Action.
For example, here’s an action that prints a friendly message before and after every invocation of tool.AS (i.e., the standard assembler)…
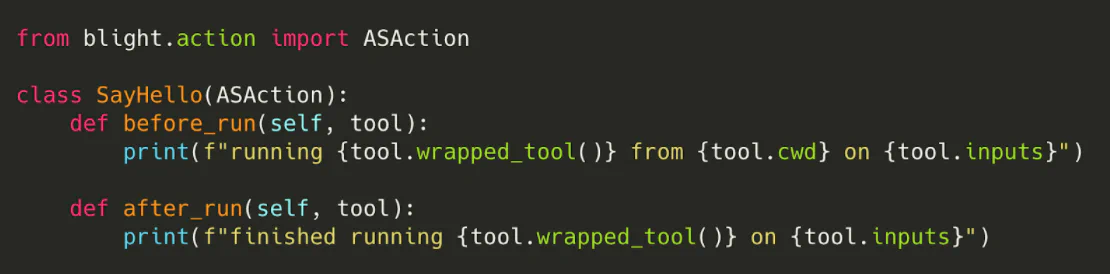
…and blight will take care of the rest—all you need to do is specify SayHello in BLIGHT_ACTIONS!
Configuration
What about actions that need to be configured, such as a configurable output file?
Remember the InjectFlags action above: Every loaded action can opt to receive configuration settings via the self._config dictionary, which the action API parses behind the scenes from BLIGHT_ACTION_ACTIONNAME where ACTIONNAME is the uppercase form of the actual action name.
How is that environment variable parsed? Very simply:

Spelled out, the configuration string is split according to shell lexing rules, and then once again split from KEY=VALUE pairs.
This should be a suitable base for most configuration needs. However, because blight’s actions are just plain old Python classes, they can implement their own configuration approaches as desired.
A new paradigm for build instrumentation
blight is the substrate for a new generation of build wrapping and instrumentation tools. Instead of modeling the vagaries of a variety of tool CLIs themselves, new wrapping tools can rely on blight to get the modeling right and get directly to their actual tasks.
Some ideas that we’ve had during blight’s development:
- An action that provides real-time build statistics via WebSockets, allowing developers to track the progress of arbitrary builds.
- A rewrite of tools like WLLVM and GLLVM, enabling higher-fidelity tracking of troublesome edge cases (e.g., in-tree assembly files and builds that generate explicit assembly intermediates).
- A feedback mechanism for trying performance options. Choosing between optimization flags can be fraught, so a
blightaction that parametrizes builds across a matrix of potential options could help engineers select the appropriate flags for their projects.
We’ve already written some actions for our own use cases, but we believe blight can be useful to the wider build tooling and instrumentation communities. If you’re interested in working with us on it or porting your existing tools to blight’s framework, contact us!
- This, it turns out, is nontrivial: Compilation flags can affect the ABI, so a sound compilation cache must correctly model the various flags passed to the compiler and only hit the intermediate cache if two (likely different) sets of flags from separate invocations are not incompatible.↩︎
- Another use case: Companies usually want to strip their application binaries of all symbol and debug information before release, to hamper reverse engineering. Doing so is usually part of a release checklist and should be enforced by the build system, and yet companies repeatedly manage to leak debug and symbol information. A build tool wrapper could provide another layer of assurance.↩︎
- In a rare divergence for Microsoft,
cl.exedoes allow you to use-optinstead of/optfor all command-line options. Unfortunately, most ofcl.exe’s options bear no resemblance to GCC or Clang’s, so it doesn’t make much of a difference.↩︎