
Multi-Party Computation on Machine Learning
During my internship this summer, I built a multi-party computation (MPC) tool that implements a 3-party computation protocol for perceptron and support vector machine (SVM) algorithms.
MPC enables multiple parties to perform analyses on private datasets without sharing them with each other. I defveloped a technique that lets three parties obtain the results of machine learning across non-public datasets. It is now possible to perform data analytics on private datasets that was previously impossible due to data privacy constraints.
MPC Primer
For MPC protocols, a group of parties, each with their own set of secret data, xi, share an input function, f, and each is able to obtain the output of f(x1,…,xn) without learning the private data of other parties.
One of the first demonstrations of MPC was Yao’s Millionaire Problem, where two people want to determine who has more money without revealing the specific amounts they each have. Each person has a private bank account balance, xi, and they want to compute f(x1,x2) = x1 > x2. Yao demonstrated how to securely compute this, along with any other function, using garbled circuits.
Each person may infer some information about the other’s data via the MPC function’s output. The leaked information is limited to whether the other party’s amount is greater or less than their own; the exact amount is never disclosed.
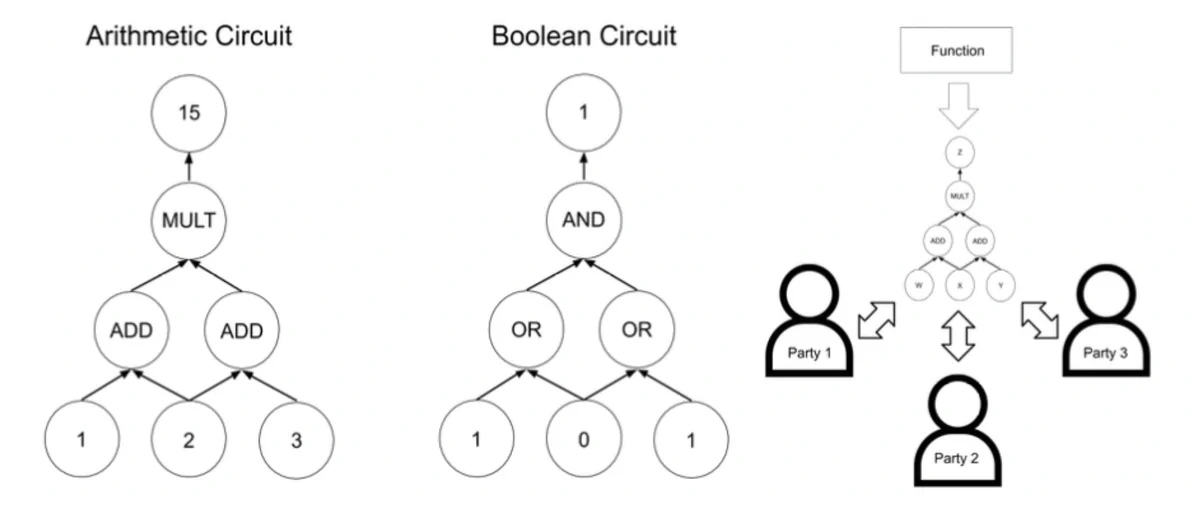
Boolean and arithmetic circuits are used by MPC protocols to compute arbitrary functions (see Figure 1). Any computable function can be represented as a combination of Boolean (AND/OR) and/or arithmetic (ADD/MULT) gates. Thus, a secure MPC protocol is established through a series of secure MPC addition and multiplication protocols. In practice, we want to convert a function into a circuit and then run MPC protocols on that circuit.
MPC protocols must also operate in a finite field, so many MPC tools are designed to operate over the integers modulo a prime p (a finite field). This makes machine learning applications difficult and, at times, incompatible, because they require fixed-point arithmetic. Almost all of these tools require a synthesis tool to convert a program (typically a C program) into its corresponding arithmetic circuit representation.
Here are several challenges that make MPC machine learning hard.
- Fixed-point arithmetic and truncation protocols are not well-suited for the finite fields that MPC protocols operate in.
- The circuit size can be as large as the input data. When functions are evaluated as circuits, all input values must be loaded into the circuit. The circuit will have input gates for every input value, which makes the input layer of the circuit as large as the dataset.
- Storing the circuit and intermediate values requires a significant amount of memory.
- Machine learning introduces loops whose exit conditions depend on intermediate values; however, each party must share its circuit with the other parties at the start of the protocol. They can’t depend on intermediate values.
The goal of my project was to create a novel MPC tool that can train machine learning models from secret data held by multiple parties. We wanted to implement a more-than-two-party computation protocol that included fixed-point arithmetic for arbitrary precision for machine learning. We also wanted to provide an alternative to circuit synthesis as a way of performing MPC with complex functions.
Secure MPC Protocols
For three parties, each party will split their data into “secret shares” and send them to the others. Secret shares must only reveal secret value information when they are all combined, otherwise all secret values must remain hidden. This property is formally defined as privacy, and is illustrated by the following:
Let n=3 parties. The parties agree to use the integers mod p, Zp, with p=43, a random small prime. Party 1 has x1=11 and wants to create secret shares for this value. Party 1 will then generate two random values in Zp, say r2=21 and r3 = 36, and send r2 to Party 2 and r3 to Party 3. Each party then stores the following values as their secret shares:
share1 = (x1 – r2 – r3) mod 43 = 40 mod 43
share2 = r2 = 21 mod 43
share3 = r3 = 36 mod 43
Notice that any one or combination of two secret shares reveal information about x1. This is where the strength of secret sharing lies.
After creating secret shares for all their private data, the parties can begin to perform secure addition or multiplication on their inputs. The protocols for both operations depend on the method of secret sharing used. I will demonstrate how we can add and multiply for the specific secret sharing scheme used above.
Let’s build the secure addition and multiplication primitives for MPC.
Addition
Consider the case of n=3, using field Zp and p=43. Here, we will take the three input values to be x1 = 11, x2 = 12, x3 = 13. Each party generates and distributes random values to obtain the following secret shares. Again, notice that:
(share1,i + share2,i + share3,i) mod 43 = xi mod 43:
Party 1 shares: share1,1 = 40 share1,2 = 13 share1,3 = 8
Party 2 shares: share2,1 = 21 share2,2 = 2 share2,3 = 17
Party 3 shares: share3,1 = 36 share3,2 = 40 share3,3 = 31
To securely add the values x1, x2, and x3, the three parties simply add their shares of each of those values.
Party 1: share+,1 = share1,1 + share1,2 + share1,3 = 40 + 13 + 8 = 18 (mod 43)
Party 2: share+,2 = share2,1 + share2,2 + share2,3 = 21 + 2 + 17 = 40 (mod 43)
Party 3: share+,3 = share3,1 + share3,2 + share3,3 = 36 + 40 + 31 = 21 (mod 43)
That’s it! Now, each party has a secret share for the value:
x1 + x2 + x3 = 11 + 12 + 13 = (18 + 40 + 21) mod 43 = 36.
Scalar Addition and Multiplication
Scalar addition and multiplication refer to adding/multiplying a secret value by a public value. Suppose each party has secret shares of some value z and they want to obtain shares of say 5 + z or 5z. This actually turns out to be easy as well. To perform addition, Party 1 adds 5 to their share and the rest of the parties do nothing, and now they all have secret shares of 5 + z. To perform multiplication, all of the parties simply multiply their shares of z by 5, and they have all obtained secret shares of 5z. You can easily check that these hold in general for any public integer.
Multiplication
Secure multiplication is more complicated than addition, because all of the parties must interact. This slows down performance when computing non-trivial functions that require several multiplications, especially if the parties are operating on a high-latency network. Therefore, the goal of most of these schemes is to minimize the amount of communication required to securely multiply.
Using Beaver Triples is a well-known method for multiplication that breaks the operation into a series of secure addition, scalar addition, and scalar multiplication. In more concrete terms, this method takes advantage of the following property:
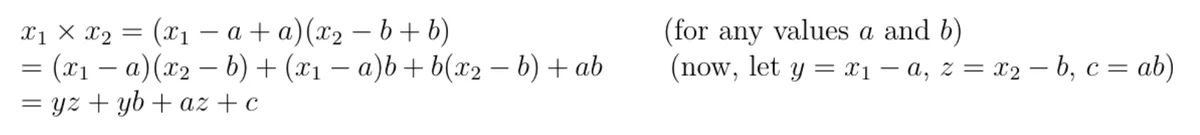
Secret shares of Beaver Triples are created along with secret shares of the input values. Beaver Triples are two random values, a and b, along with their product, ab = c. Secret shares for each of these values are sent to the other parties, so each party has secret shares for x1, x2, a, b, and c.
To compute x1 ✕ x2, every party first computes shares of (x1 – a) and (x2 – b) to be broadcast to the other parties. The share of (x1 – a) are obtained by scalar multiplying by -1 and adding the result to x1. The same is done for (x2 – b). Once those shares are computed and broadcast, everyone can now compute yz. In the final step, parties obtain shares for yb and az through scalar multiplication, leaving everyone with the value yz and the secret shares for yb, az, and c.
Secure addition is used on the shares for yb, az, and c, in order to obtain secret shares of (yb + az + c). Then, they perform a scalar addition with yz and their shares of (yb + az + c). Now, the shares for (yz + yb + az + c) = x1 ✕ x2 are obtained, and the protocol is completed.
Optimization
A major bottleneck in MPC is the communication between parties due to multiplication, which cannot typically be done in parallel. To optimize, the choices are to either reduce the communication exchanges and/or reduce the number of multiplications needed for a function. My work focused on the latter.
Integer comparison is difficult for arithmetic circuits, and if the transformation from function to circuit isn’t clever enough, comparisons may be very inefficient. But in fact, all arithmetic circuits can be represented by a polynomial in the input values.
Let’s consider the polynomial representing f(x1,x2) = x1 < x2, where the number of zeros is half the input space and proportional to the field size. Since this function is not constant zero, the polynomial degree is proportional to the number of zeroes. So the arithmetic circuit that is computing this has as many multiplication gates as the size of the field. Incredibly inefficient!But we can actually obtain an exponentially smaller arithmetic circuit by breaking everything down into building blocks using the methodologies from Octavian Catrina and Sebastiaan de Hoogh’s paper. The major building block needed is an efficient protocol for truncation, and they develop this via a modular remainder protocol that is built from other sub-protocols. What’s important is that instead of circuits needing to be proportional to the field itself, they allow us to use circuits proportional to the bit-size of the field, making them exponentially smaller.
Results
I chose to implement the MPC protocol from Araki, et. al., including their methods for secret sharing, addition, and multiplication. I also developed the specialized secure comparison and truncation protocols, as well as a dot product protocol. Combining complex protocols with addition and multiplication is known as the hybrid model of secure computation. This hybrid model gives us really compact, intuitive circuits that can even be written by hand! (see figures 2 and 3)
I applied this MPC protocol to both perceptron and SVM algorithms, which requires converting them into the building block operations. The SVM algorithm can be manually synthesized into a compact, hybrid circuit using complex building blocks of comparison and dot product operations. Specifically, one iteration of each algorithm only requires around 15 gates. For comparison, synthesizing AES using a synthesis tool will result in thousands of addition and multiplication gates.
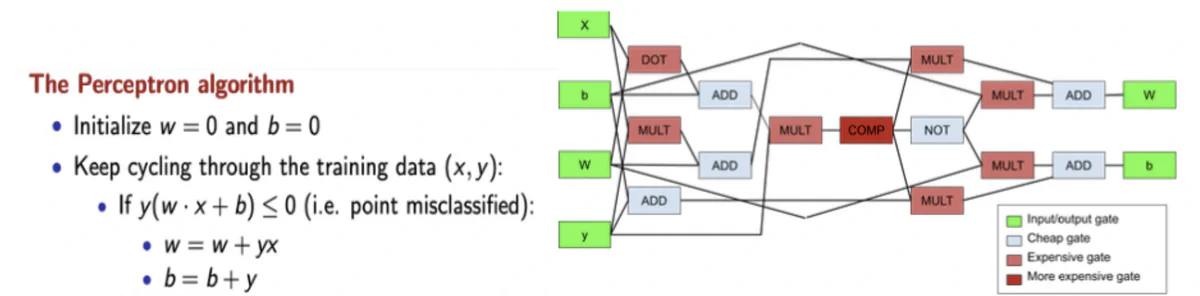
To avoid massive circuits, proportional to the dataset, I only synthesized circuits for one iteration of each protocol. This avoided having to deal with loops and yielded a very compact circuit that can be reused for any dataset. Lastly, using one iteration gives flexibility on how to handle the convergence of our protocol. This approach provides three options:
- the parties agree on a fixed number of iterations beforehand,
- the parties reveal an epsilon value publicly, or
- the parties compute a convergence check according to another MPC.
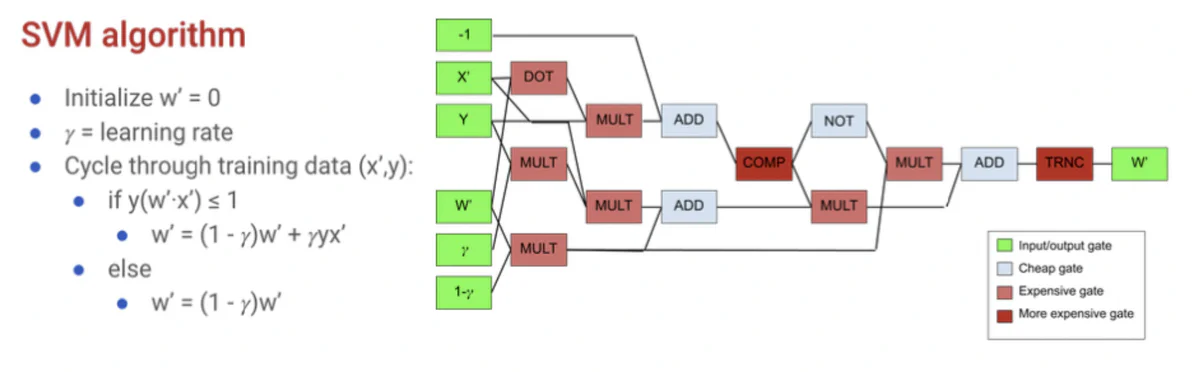
Once the hybrid circuits were manually synthesized, I performed the algorithms on test datasets and achieved arbitrary fixed-point precision. The classification accuracy was also the same as the raw algorithms. Therefore, this tool can be used to train secret data using either perceptron or SVMs with arbitrary precision.
Concluding Thoughts
I spent the summer tackling several difficulties related to MPC with machine learning. By the end of the summer, I had an efficient solution to each of these problems and was able to run two different machine learning algorithms securely across three parties. I enjoyed working on this project. Before interning at Trail of Bits, I had just completed the second year of my Ph.D. I initially thought the transition from school to industry would be drastic. But I quickly noticed that in this internship, my project would be very similar to Ph.D. research, which is one of the many things that makes Trail of Bits such a great place to work.