
Binary symbolic execution with KLEE-Native
KLEE is a symbolic execution tool that intelligently produces high-coverage test cases by emulating LLVM bitcode in a custom runtime environment. Yet, unlike simpler fuzzers, it’s not a go-to tool for automated bug discovery. Despite constant improvements by the academic community, KLEE remains difficult for bug hunters to adopt. We’re working to bridge this gap!
My internship project focused on KLEE-Native, a fork of KLEE that operates on binary program snapshots by lifting machine code to LLVM bitcode.
What doesn’t kill you makes you stronger
KLEE’s greatest strength is also its biggest weakness: It operates on LLVM bitcode. The most apparent strength of operating on bitcode is that KLEE can run on anything that the Clang compiler toolchain can compile: C, C++, Swift, Rust, etc. However, there is a more subtle benefit to KLEE’s approach that is often overlooked. Operating on bitcode means the “supporting code” or “runtime” can be implemented in C or C++, compiled to bitcode, linked against the system under test (SUT), and then subjected to the same symbolic path exploration as the SUT itself.
This provides flexibility and power. For example, a KLEE runtime can implement I/O-related system calls (read, write, etc.) as plain old C functions. These functions are subject to symbolic exploration, just like the SUT, and contribute to code coverage. This allows KLEE to “see into” the OS kernel, and explore paths that might lead to tricky corner cases.
Now for the downside of operating in bitcode. Typically, KLEE is used on programs where source code is available, but getting bitcode from source code is not easy because of the difficulties created by build systems, configurations, and dependencies. Even when bitcode is available, a vulnerability researcher may have to manually inject KLEE API calls into the source code, link in the KLEE runtime, and possibly stub out or manually model external library dependencies. These tasks become daunting when dealing with large code bases and complicated build systems. McSema is a black-box option when source code is not available, but the limitations of binary control-flow graph recovery and occasional inaccuracies may not produce acceptable results.
KLEE-Native runs on binary program snapshots
First, we focused on getting bitcode for any program, and the approach we took was to operate on bitcode lifted from machine code, as opposed to compiled source. Using a dynamic approach based on snapshots like with GRR, we can start KLEE-Native deep into a program’s execution, which isn’t possible with mainline KLEE.
Snapshotting
By default, the KLEE-Native snapshotter captures the program’s memory and register state right before the first instruction is executed. This means KLEE-Native needs to emulate pre-main code (e.g., loading shared libraries), which isn’t ideal. To avoid emulating that type of deterministic setup, we implemented a feature that works by injecting an INT3 breakpoint instruction at a user-specified virtual address, via ptrace.
In this mode, the target process executes natively until the breakpoint instruction is hit. Once it’s hit, the snapshotter reclaims control of the target and subsequently dumps the target process memory and a register state structure compatible with Remill into a “workspace” directory. Memory mappings of the original process can then be recreated from this workspace.
$ klee-snapshot-7.0 --workspace_dir ws --breakpoint 0x555555555555 --arch amd64 -- ./a.out
For address-space layout randomization (ASLR) binaries, the --dynamic flag instructs the snapshotter to interpret the breakpoint address as an offset within the main program binary. To do this, we use a neat trick of parsing the /proc/[pid]/maps file for the target process to discover the base virtual address of the loaded program. Do some arithmetic and voila, we have our breakpoint location!
$ klee-snapshot-7.0 --workspace_dir ws --dynamic --breakpoint 0x1337 --arch amd64_avx -- ./a.out
Side note: One interesting side effect involves CPU feature testing. Libc checks for available CPU features using the CPUID instruction and uses it to determine whether to use specialized versions of some functions (e.g., a hand-coded, SSE4-optimized memset). If a snapshot is taken after CPUID is executed natively, then you must specify an AVX option for the architecture of the snapshot. Otherwise those kinds of instructions might not lift.
Dynamically lifting machine code to bitcode
Now that we have our snapshot, we can ask KLEE-Native to dynamically lift and execute the program. We can do this with the following command:
$ klee-exec-7.0 --workspace_dir ws
The following diagram shows the control flow of klee-exec.
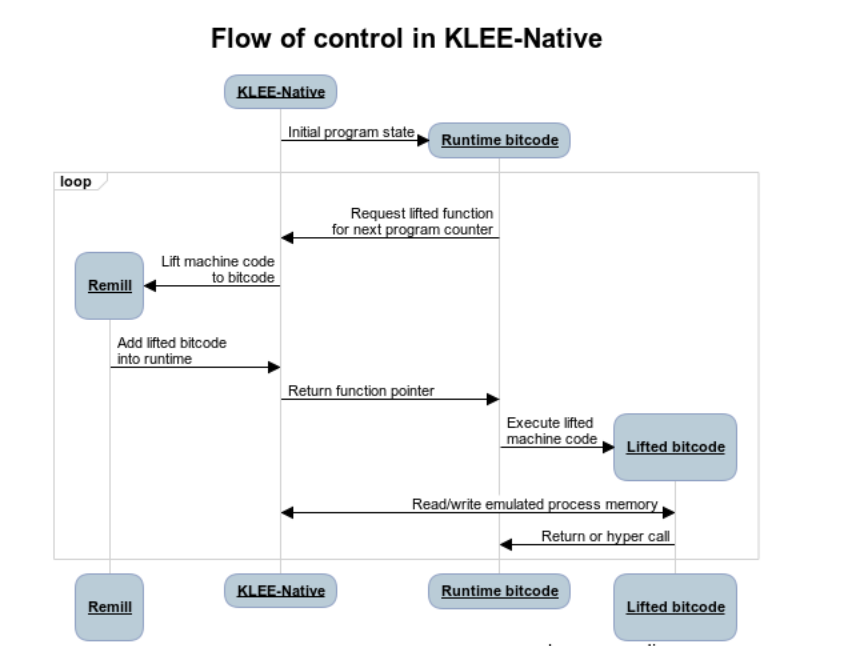
At a high level, KLEE-Native just-in-time decodes and lifts traces, which are simply LLVM function objects that contain a logical segment of the lifted machine code. Traces contain LLVM instructions emulating machine code and calls to Remill intrinsics and other lifted traces.
Intrinsic calls may be handled by KLEE’s “special function handler” capability, which allows for runtime bitcode to have direct access to KLEE’s executor and state. For example, Remill’s memory read-and-write intrinsics use the special function handler to interact with the snapshotted address space.
When emulating a function like malloc, traces are created from libc’s implementation, and execution is able to continue smoothly. All is good in the world. We see the light and everything makes sense…
… Just kidding!
brk and mmap come along, and now we have to execute a system call. What do we do?
The runtime is the kernel and the machine
KLEE-Native lifts all machine code down to the raw system call instructions. Using Remill, system call instructions are handled by a call to the intrinsic function __remill_async_hyper_call in the runtime bitcode. Remill doesn’t specify the semantics of this function, but the intent is that it should implement any hardware- or OS-specific functionality needed to carry out a low-level action.
In our case, KLEE-Native implements the __remill_async_hyper_call function, so it passes execution from lifted bitcode back into the runtime bitcode, where each Linux system call wrapper is implemented.
System call wrappers are parameterized by an Application Binary Interface (ABI) type, which finds the system call number and arguments and stores the return value. Here is an example the SysOpen function, which wraps the POSIX open system call implemented by KLEE’s runtime.
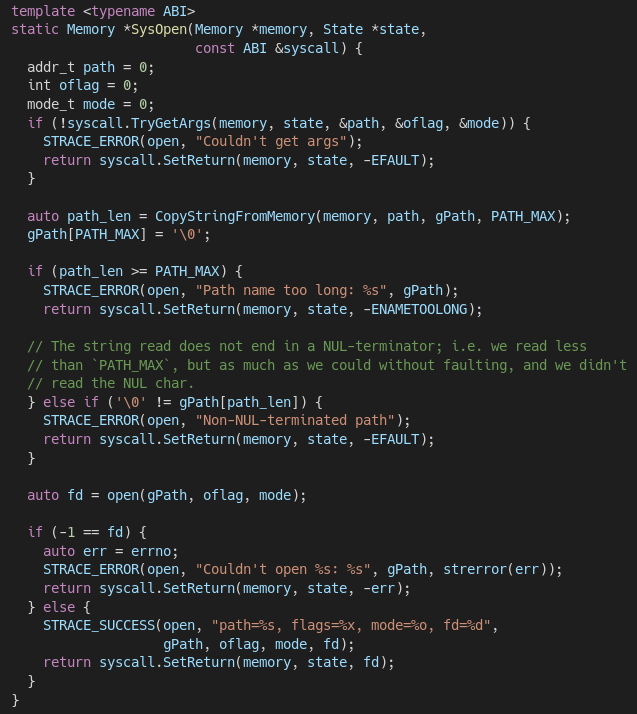
Snippet of emulated open system call
This wrapper performs some of the error checking that the actual OS kernel would do. (i.e., making sure the file path name can be read from the snapshotted address space, checking the path length, etc.) Here is where we play to KLEE’s strengths: All of these error-checking paths are subject to symbolic exploration if any of the data being tested is symbolic.
We have now dynamic-lifted machine code to bitcode, and we’ve emulated system calls. That means we can run the lifted machine code and have it “talk” to KLEE’s own runtime the same way that bitcode compiled from source might do.
Our call to malloc continues executing and allocating a chunk of memory. Life is good again, but things are starting to get slow. And boy, do I mean sloooooooow.
Recovering source-level abstractions with paravirtualization
Operating on machine code means that we must handle everything. This is problematic when translating seemingly benign libc functions. For example, strcpy, strcmp, and memset require significant lifting effort, as their assembly is comprised of SIMD instructions. Emulating the complex instructions that form these functions ends up being more time consuming than if we had emulated simplistic versions. This doesn’t even address the sheer amount of state forking that can occur if these functions operate on symbolic data.
We paravirtualized libc to resolve this issue. This means we introduced an LD_PRELOAD-based library into snapshotted programs that lets us interpose and define our own variants of common libc functions. In the interceptor library, our paravirtualized functions are thin wrappers around the POSIX originals, and executing them results in the original POSIX functions being called before the snapshot.
Their purpose is to be a single point of entry that we find and patch during the snapshot phase. In the following example, the snapshotter will patch over a JMP with a NOP instruction so that malloc ends up invoking INT 0x81 when it is emulated by KLEE-Native.

LD_PRELOAD malloc interceptor
When an interrupt is hit during emulation, we check the interrupt vector number and hook to a corresponding paravirtualized libc runtime function. Sometimes our paravirtualized versions of the libc functions cannot handle all cases, so we support a fallback mechanism, where we give control to the original libc function. To do this, we increment the emulated program counter by one and jump over the RETN instruction, which leads to the original function being executed.
Here are the libc functions that our LD_PRELOAD library currently intercepts. Each of the numbers (e.g., malloc’s 0x81) is the interrupt vector number that corresponds with the paravirtualized version of that function.
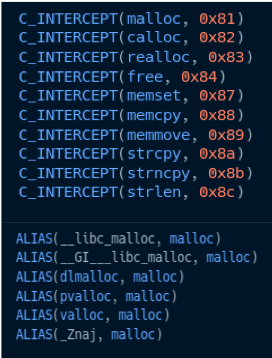
libc functions with paravirtualized equivalents
Wonderful! Our call to malloc has, instead, hit an interrupt, and we are able to hook to its paravirtualized version in KLEE. What exactly are we doing with it, and why do we care?
Modeling heap memory with libc interceptors
A call to mmap or brk during an emulated malloc will layout memory for allocations. While this is an accurate representation of the lifted machine code instructions, it is not a productive model for finding bugs. The problem: mmaps are very coarse grained.
Every access to memory can be seen, but it is unclear where a given allocation begins or ends. As a result, it is difficult to do things like bounds checks to detect overflows and underflows. Furthermore, there is no oversight on bug classes like double frees and use-after-frees, when allocations are opaque blobs.
That’s why we have interposed on malloc and other allocation routines to formulate a crystalline memory model that demarcates memory allocations. This approach makes it trivial for KLEE-Native to classify and report heap vulnerabilities. What’s unique about this approach is that we have invented a totally new address format for allocations to make our lives easier. It contains metadata about each allocation, which makes it simple to locate in our memory model.
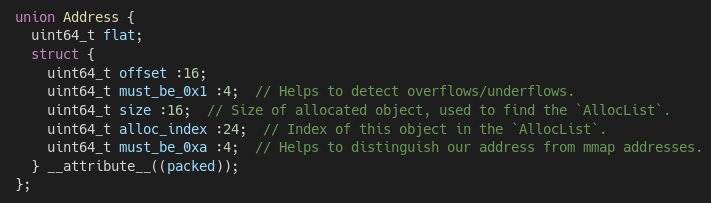
Union showing the components of our custom address encoding
Allocations backed by our paravirtualized malloc don’t truly “exist” in a traditional address space. Instead, they exist within allocation lists. These are structures that allow individual allocations to coexist so that they’re easy to access, track, and manipulate, which makes bounds checks, double-free detection, and overflow/underflow detection extremely transparent. Furthermore, allocation lists give us the flexibility to recover from issues like heap-based buffer overflows by expanding the backing “allocation” in place.
Huzzah! We’ve achieved a clear-cut representation of the target’s allocated memory using allocation lists. But wait. Isn’t this supposed to be a symbolic execution engine? All of this is really only concrete execution. What’s going on?
Eager concretization for an improved forking model
Our approach to symbolic execution is a departure from the typical scheduling and forking model used by KLEE. Where KLEE is a “dynamic symbolic executor,” KLEE-Native is closer to SAGE, a static symbolic executor.
KLEE-Native’s approach to forking favors eager concretization and depth-first exploration. The kick is that we can do it without sacrificing comprehensiveness. Meaning, it is always possible to go to a prior point in execution and request the next possible concretization, if that is our policy. This is different than something like KLEE or Manticore, which eagerly fork (i.e., generate a multitude of feasible states, and then defer to a scheduler to choose them over time).
The mechanism we created to enable eager concretization, without sacrificing forking potential, is implemented using state continuations. State continuations are like Python generators. In KLEE-Native, they package up and hold on to a copy of the execution state prior to any forking, as well as any meta-data needed in order to produce the next possible concretization (thus giving us comprehensiveness). The executor can then request the next possible forked state from a given continuation. Thus, each request gives us back a new execution state, where some condition has been concretized (hence the term “eager concretization”).
For now, we store state continuations on a stack. The result is that KLEE-Native “goes deep” before it “goes wide.” This is because at each point where the state could be forked, we create a continuation, get the first state from that continuation, and push it onto the stack. When a state is done executing (e.g. it exits, or an unrecoverable error is encountered), we look at the last continuation on the stack and ask for its next state. This process continues until a continuation is exhausted. If that happens, it is popped off and we go to the next continuation on the stack. In the future, we will explore alternative strategies.
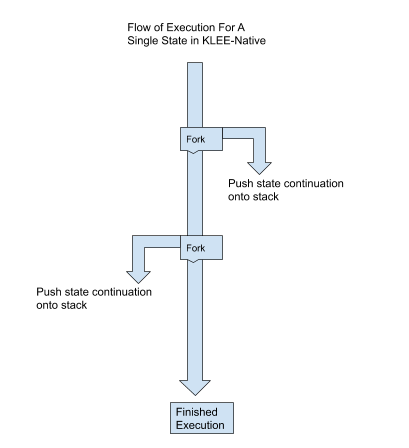
How to fork when eagerly concretizing
Our approach was motivated by a need to handle symbolic memory addresses. We started adding symbols, but couldn’t always get KLEE to explore all paths. KLEE was concretizing memory addresses, but not in a comprehensive way. This was honestly expected, because symbolic memory is a hard problem.
Implementing concrete memory is easy, because there is essentially a map of addresses to byte values. However, what does it mean when an address could take on many values? We decided the best policy was to create a generic mechanism to concretize the address immediately without throwing away all the other possibilities, and then leave it up to policy handlers to make more substantive approaches. Examples of more substantive policies could be sampling, min/max, etc.
Wonderful! We can now explore the program’s state space. Let’s go hunting.
Applying KLEE-Native in the real world
Because we have control over emulated address space and memory allocations, classifying different types of memory corruption vulnerabilities becomes easy with KLEE-Native, and vulnerability triaging is a fantastic use case for this. Furthermore, our eager concretization strategy ensures we will stick to the code path of interest.
Here is CVE-2016-5180 from the Google fuzzer-test-suite. It is a one-byte-write heap buffer overflow in c-ares that was used in a ChromeOS exploit chain.
We first snapshot the program at main with a dynamic breakpoint:
$ klee-snapshot-7.0 --workspace_dir ws_CVE --dynamic --breakpoint 0xb33 --arch amd64_avx -- ./c_ares
And simply run the klee-exec command:
$ klee-exec-7.0 --workspace_dir ws
Here we get KLEE-Native detecting a one-byte heap overflow.
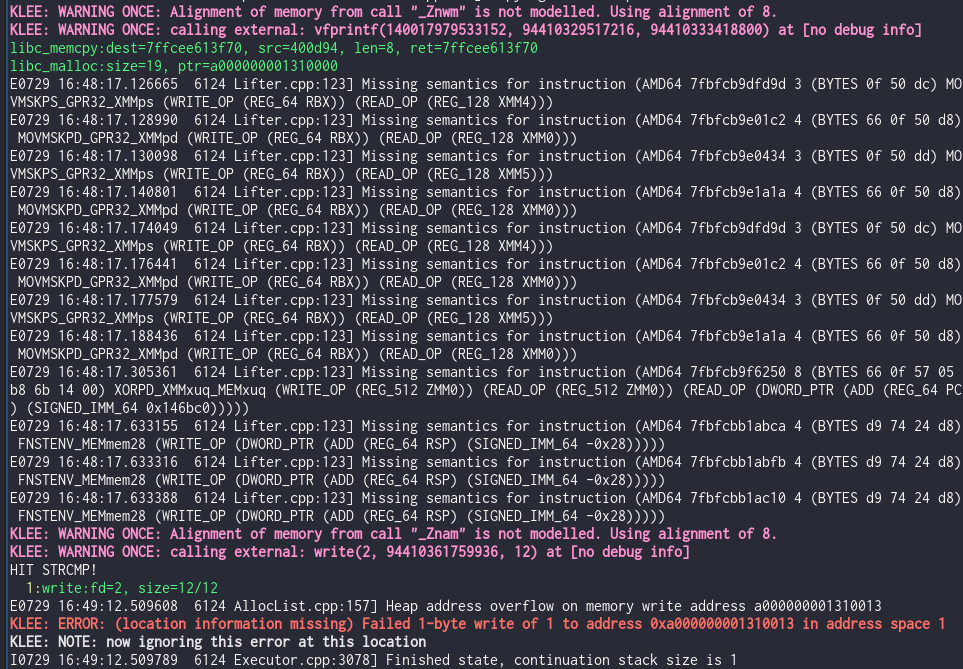
So what makes KLEE-Native special compared to AddressSanitizer or Valgrind? This is where our policy handler comes in. One policy to handle memory access violations like this one is replacing overflow bytes with symbolic ones. As execution continues, we could potentially diagnose the severity of the bug by reporting the range of symbolic overflow bytes at the end. This could let a vulnerability researcher distinguish states that allow limited possibility for an overflow from ones that could potentially allow a write-what-where primitive.
In KLEE-Native, undefined behavior can be the new source for symbolic execution. This enables vulnerability triaging without prior knowledge of your threat model and the need for tedious reverse engineering.
Au revoir!
My internship produced KLEE-Native; a version of KLEE that can concretely and symbolically execute binaries, model heap memory, reproduce CVEs, and accurately classify different heap bugs. The project is now positioned to explore applications made possible by KLEE-Native’s unique approaches to symbolic execution. We will also be looking into potential execution time speed-ups from different lifting strategies. As with all articles on symbolic execution, KLEE is both the problem and the solution.