
Reverse Taint Analysis Using Binary Ninja
We open-sourced a set of static analysis tools, KRFAnalysis, that analyze and triage output from our system call (syscall) fault injection tool KRF. Now you can easily figure out where and why, KRF crashes your programs.
During my summer internship at Trail of Bits, I worked on KRF, a fuzzer that directly faults syscalls to cause crashes. KRF works extremely well and pumps out core dumps like nobody’s business. However, it is difficult to determine which faulted syscall caused a particular crash since there could be hundreds of faulted syscalls in a single run. Manually tracing the cause of the crash through the source or disassembled binary is tedious, tiring, and prone to errors.
I set out to solve this problem using a technique I call Reverse Taint Analysis, and implemented my solution using the Binary Ninja API. The script gives a short list of possible causes of the crash, drastically limiting the amount of manual work required. Here, I describe the process I went through to create the algorithm and script, and give a brief overview of the additional tools built to ease its use.
Human in the Loop
How can we reliably determine the source of a crash? Well, how would a human determine the cause of a crash? First, we would look at the stack trace and figure out where the crash occurred. Let’s take a look at this vulnerable example program:
#include
#include
void fillBuffer(char * string, unsigned len) {
for (unsigned i = 0; i < len; ++i) {
string[i] = 'A'; // if string = NULL, segfaults on invalid write
}
}
int main() {
char *str;
// Memory allocated
str = (char *) malloc(16); // if malloc fails, str = NULL
fillBuffer(str, 16); // str not checked for malloc errors!
free(str);
return 0;
}Running KRF against this program caused a fault. In this case, we can easily guess why the crash occurred—a faulted brk or mmap caused malloc to return NULL, which produced a segfault when fillBuffer tried to write to NULL. But let’s figure out the cause of the crash for certain, acting as if we didn’t have access to the source code.
First, let’s open up the core dump’s stack trace with gdb and see what caused the crash:
(gdb) bt
#0 0x00005555555546a8 in fillBuffer ()
#1 0x00005555555546e1 in main ()Next, let’s take a look at our memory maps for the process so we can find the instruction in the binaries:
(gdb) info proc mappings
Mapped address spaces:
Start Addr End Addr Size Offset objfile
0x555555554000 0x555555555000 0x1000 0x0 /vagrant/shouldve_gone_for_the_head
[output truncated]Now, cross-referencing the address from the stack trace, we see that the instructions of the top stack frame, at 0x555555554000, are in the binary /vagrant/shouldve_gone_for_the_head. We can calculate the instruction pointer’s offset in the binary by subtracting its location in the mapped address space from the beginning of the memory-mapped objfile and adding the offset:
0x00005555555546a8 - 0x555555554000 + 0x0 = 0x6a8.
Great! Now we can examine the binary itself in our disassembler of choice (Binary Ninja) and see what went wrong.
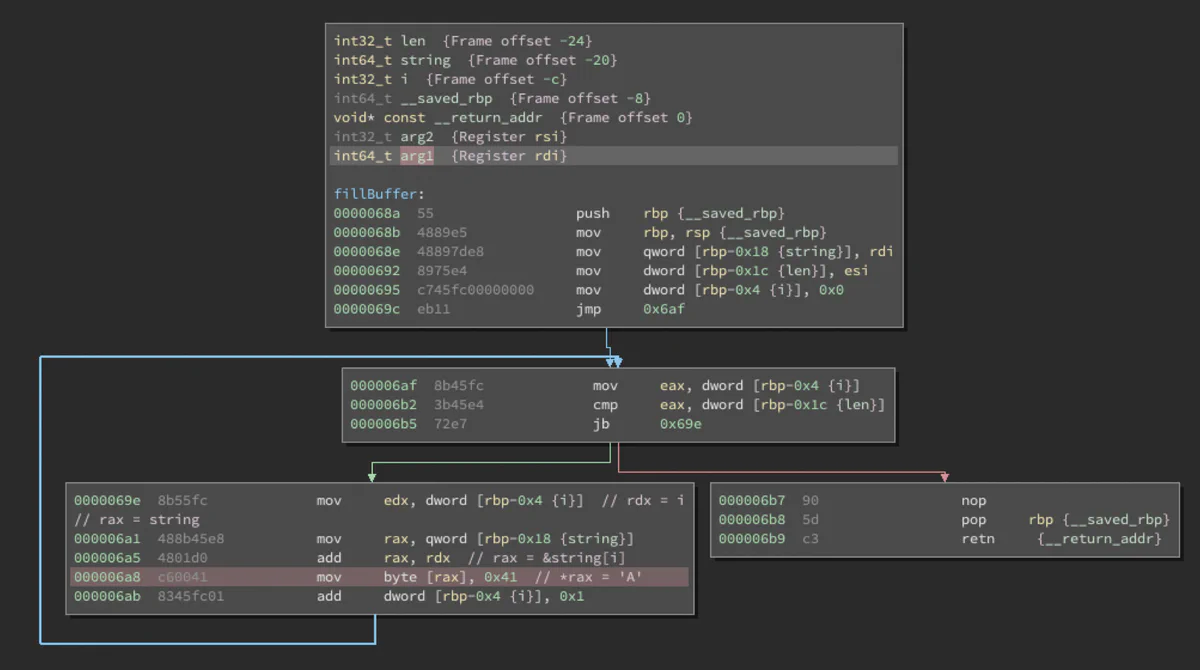
Here, we can see the disassembly of the fillBuffer() function, with the instruction that causes the segfault highlighted in red. This instruction sets the byte pointed to by rax to the character code for A. So, the issue must be an invalid value of rax. Looking back, we see that rax = rax + rdx, which are both previously set to the local variables string and i, respectively. We can see in the instruction at 0x68e that string was originally stored in rdi, which is the first argument to the function. i is initialized to zero and is only incremented, so we can ignore it, since we know it could not have been tainted by a function call or the function’s arguments.
Knowing that the first argument to fillBuffer() is tainted, we can go to the next frame in the stack trace and see what happened. We perform the same subtraction with the memory map to the address in the stack trace, 0x00005555555546e1, and get the actual address:
0x00005555555546e1 - 0x555555554000 + 0x0 = 0x6e1.
This address is going to be one instruction after the function call to fillBuffer() since it is the return address. So, we want to examine the instruction directly before the one at 0x6e1. Let’s open it up in Binary Ninja!
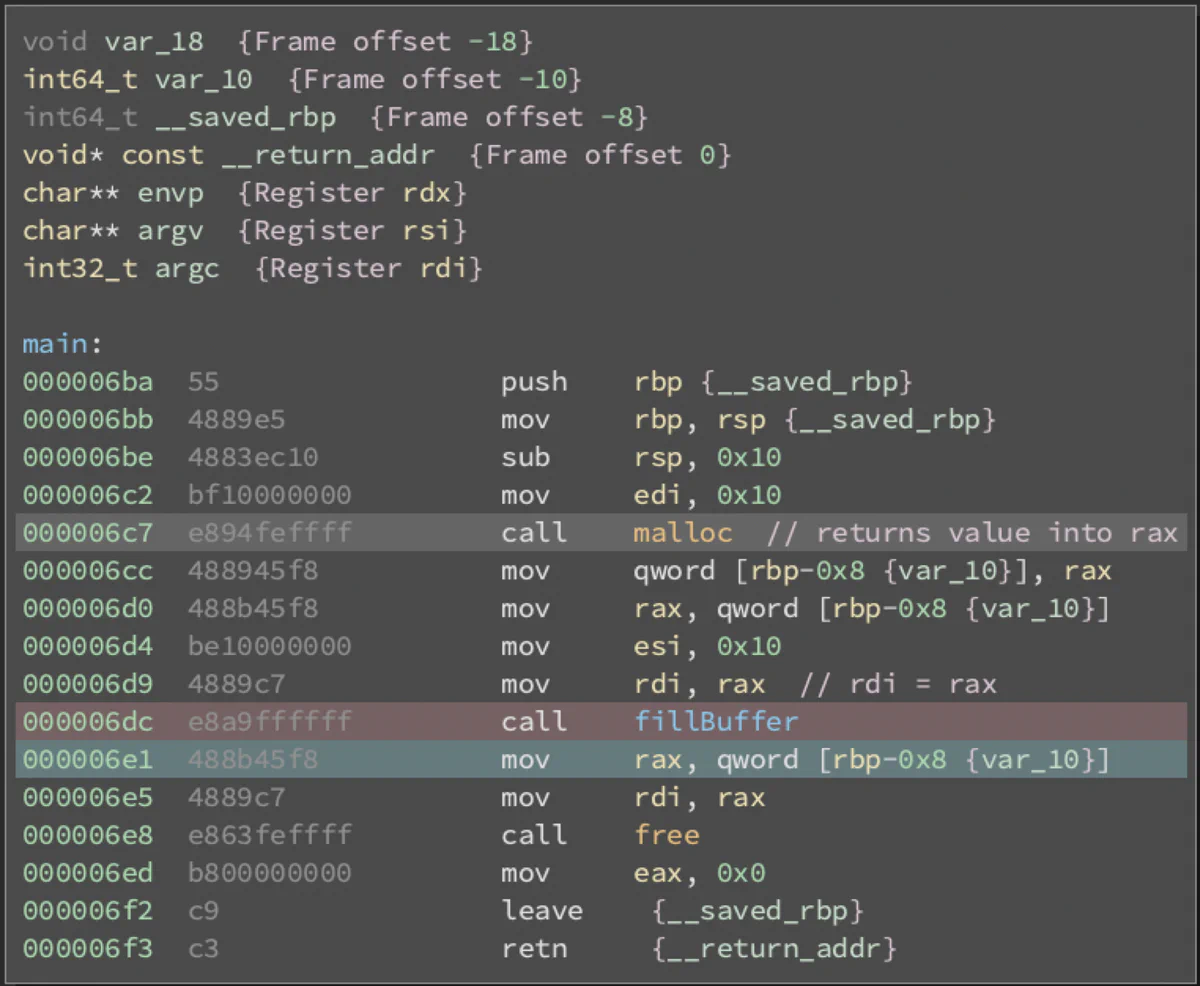
Here, we have the instruction at 0x6e1 highlighted in blue, and the previous instruction highlighted in red. We know from our manual analysis of fillBuffer that the first parameter is stored in rdi, so we should track the data being stored in rdi. In the instruction before, we see that rdi is set to rax, and above that, there is a call to malloc, which stores its return value in rax.
Great! Now we know that the output of malloc gets passed into fillBuffer, where it causes the segfault. We’ve figured it out! But that was really annoying. If only there were a better way…
Enter MLIL Static Single Assignment
Well, it turns out there is a better way! Binary Ninja can decompile code into something called Medium Level IL (MLIL), which is a more human-readable form of assembly. It can then convert that MLIL into a form called Static Single Assignment (SSA), where every variable is assigned exactly once. This becomes really useful, because we don’t need to worry about things changing a variable other than its definition. As an example of SSA, consider this pseudocode function:
def f(a):
if a < 5:
a = a * 2
else:
a = a - 5
return aIn SSA form is:
def f(a0):
if a0 < 5:
a1 = a0 * 2
else:
a2 = a0 - 5
a3 = Φ(a1, a2) // meaning “a3 is either a1 or a2”
return a3So, let’s look at our same example again through the lens of SSA MLIL. Here’s fillBuffer in SSA MLIL:
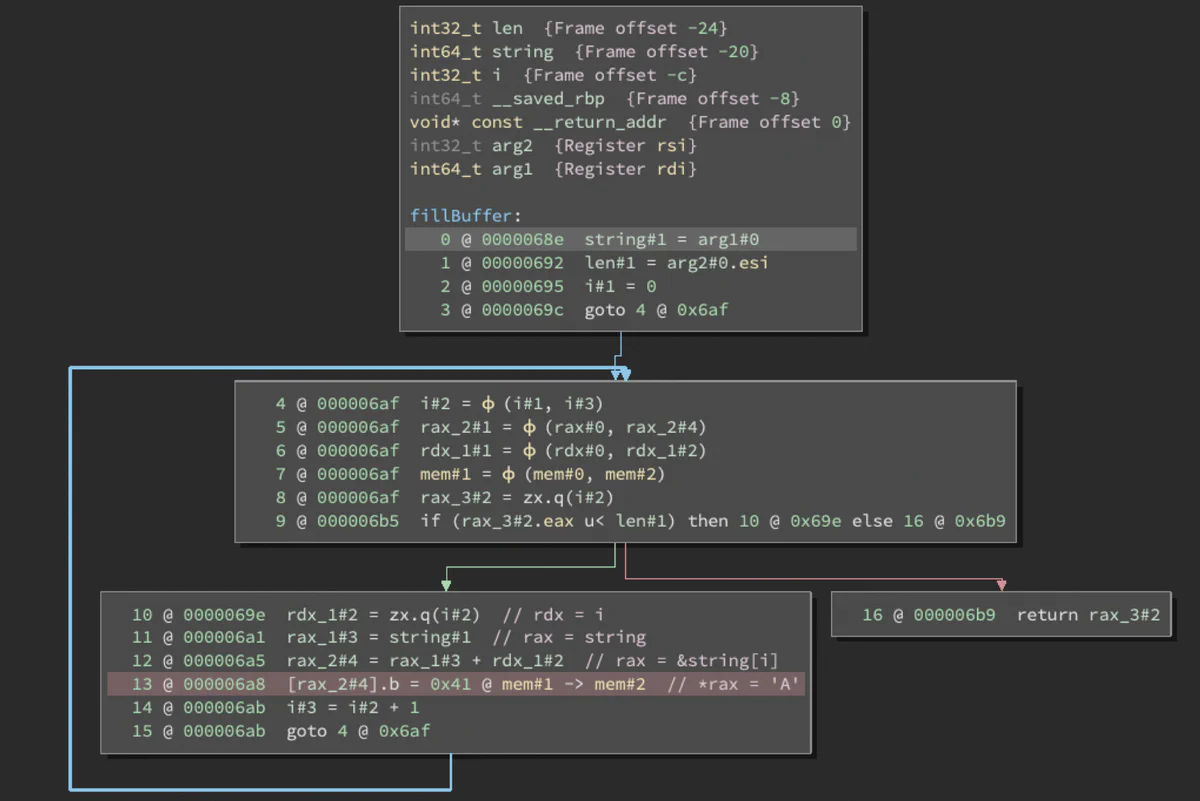
Here, we can easily trace rax_2#4 to rax_1#3 + rdx_1#2, then trace rax_1#3 to string#1, which we see is arg1. We can also easily trace back i and see that it is set to 0. We have once again discovered that the first argument to fillBuffer is the source of the crash. So now, let’s look at main.
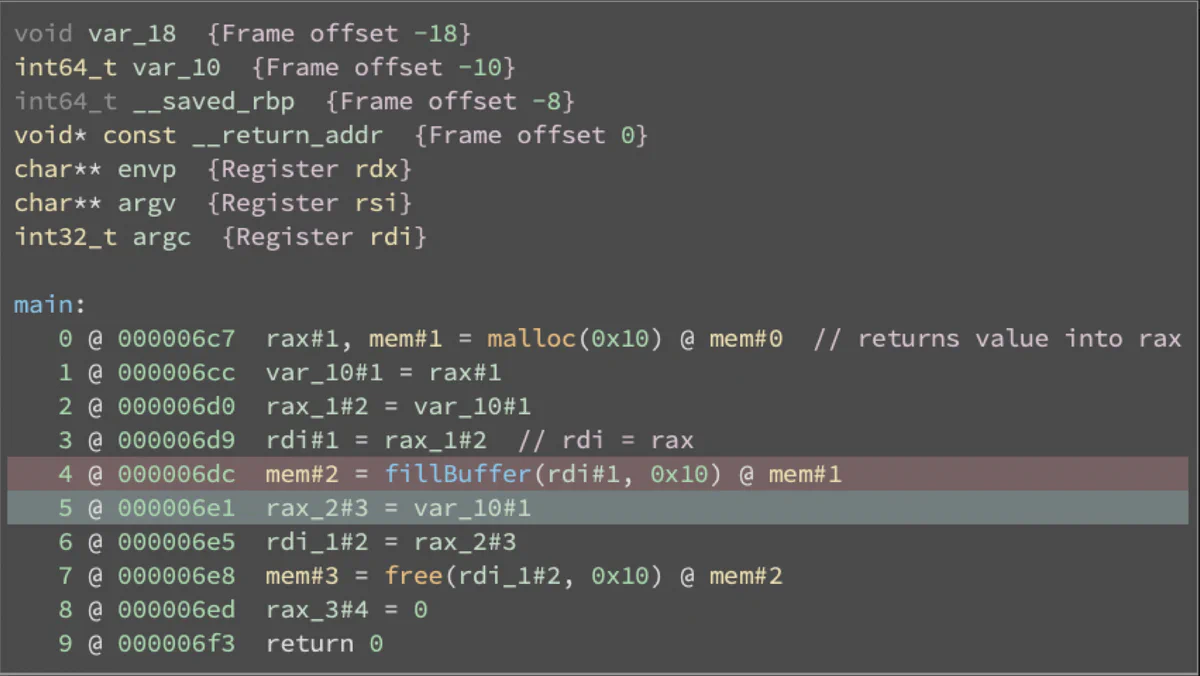
This is where we really see the benefits of SSA MLIL over regular disassembly. It lets us see what arguments are passed into fillBuffer, and what values are returned by malloc, making the analysis much easier. By tracing the sources of rdi#1 backwards, we again see that malloc is tainting the first argument of fillBuffer and, therefore, causing the crash.
We’re in the endgame now
So now that we’ve realized (for the second time) that malloc is the cause of our issues, let’s write out the process we’ve been applying, so we can easily convert it to code:
1. Make an empty stack.
2. Push the crashing instruction to the stack.
3. While the stack is not empty:
4. Pop an instruction off the stack.
5. If it is a MLIL function call instruction:
6. The return value of that function call may be cause of crash
7. Otherwise:
8. For each SSA variable used in the MLIL instruction:
9. If it’s not assigned in this function:
10. # It’s a function argument
11. We will have to go another frame up our stack trace.
12. # The same as going to main after finding arg1 was tainted
13. Otherwise:
14. Add the instruction assigning SSA variable to the stack.This is going to be easy! We just have to write it out in Python using the Binary Ninja API. We need to write a function that takes our instruction’s address and a BinaryView (a class holding information on the binary), and prints out the taint sources of the instruction.
def checkFunction(self, inst_addr, bv):
# Get MLILFunction obj for the function containing the instruction
func = bv.get_functions_containing(inst_addr)[0].medium_level_il
# Get the MLILInstruction obj for instruction at inst_addr
inst = func[func.get_instruction_start(inst_addr)].ssa_form
# Convert MLILFunction to SSA form
func = func.ssa_form
# Keep track of what is seen
visited_instructions = set()
# Variables we are interested in
var_stack = []
# Add the vars used by first instruction to stack
for v in inst.vars_read:
var_stack.append(v)
# Continuously run analysis while elements are in the stack
while len(var_stack) > 0:
var = var_stack.pop()
if var not in visited_instructions:
# Add to list of things seen
visited_instructions.add(var)
# Get variable declaration
decl = func.get_ssa_var_definition(var)
# Check if its an argument
if decl is None:
print("Argument " + var.var.name + " tainted from function call")
continue
# Check if its a function call
if decl.operation == MediumLevelILOperation.MLIL_CALL_SSA:
# If direct call
if decl.dest.value.is_constant:
# Get MLILFunction object of callee from address
func_called = bv.get_function_at(decl.dest.value.value)
print("Tainted by call to", func_called.name, "(" + hex(decl.dest.value.value) + ")")
else:
# Indirect calls
print("Tainted by indirect call at instruction", hex(decl.address))
continue
# If not an argument or call, add variables used in instruction to the stack. Constants are filtered out
for v in decl.vars_read:
var_stack.append(v)The power of SSA is used in the vars_read and get_ssa_var_definition methods. MLIL makes detecting calls easy using decl.operation == MediumLevelILOperation.MLIL_CALL_SSA.
Extending the script
We can expand on a lot here with error handling, edge cases, automatically analyzing the frame above in the stack trace, automatically extracting information from the stack trace, etc. Thankfully, I’ve already done some of that with a set of python scripts.
python3 main.py binary coredump1 [coredump2] …
Automatically extracts the needed information from the core dumps, then inserts that information and binaries into a tarball to be copied to another computer, including libraries that are called in the stack trace.
gdb.py
Uses GDB Python API to extract data from each core dump. It’s called by main.py, so they must be in the same directory.
python3 analyze.py tarball.tar.gz
Takes a tarball output by main.py and automatically runs reverse taint analysis on each core dump in it, automatically cascading tainted arguments to the next frame. It uses krf.py to run the analysis, so they must be in the same directory.
krf.py contains the analysis code, which is a more featured version of the script written in this blog post. (Requires the Binary Ninja API.)
Let’s try them on our test binary:
$ # Linux VM with KRF
$ python3 main.py shouldve_gone_for_the_head core
Produced tar archive krfanalysis-shouldve_gone_for_the_head.tar.gz in /vagrant
$ # Machine with Binary Ninja
$ python3 analyze.py krfanalysis-shouldve_gone_for_the_head.tar.gz
Analyzing binary shouldve_gone_for_the_head
Done
Analyzing crash krfanalysis-shouldve_gone_for_the_head/cores/core.json
Tainted by call to malloc (0x560)
All paths checkedConclusion
Writing this analysis script has shown me the Binary Ninja API is amazing. The versatility and automatic analysis it allows is incredible, especially considering it acts directly on binaries, and its intermediate languages are easy to use and understand.
I’d also like to mention LLVM, another framework for static analysis, which has a very similar API to Binary Ninja. It has many benefits over Binary Ninja, including better access to debug and type information, being free, having a more mature codebase, and always-perfect analysis of calling conventions. Its downside is that it needs the source code or LLVM IR of what you are analyzing.
Three LLVM passes are available in the KRFAnalysis repository to run static analysis: one detecting race conditions caused by checking the state of a system before use (i.e. time-of-check, time-of-use or TOC/TOU), another detecting unchecked errors from standard library calls, and a third reimplementing reverse taint analysis.
My summer: A small price to pay for salvation
I am incredibly grateful to everyone at Trail of Bits for my internship. I gained some amazing technical experience and got the chance to work with the Linux Kernel, FreeBSD Kernel, and LLVM—codebases I had previously considered to be mystical.
Some of my highlights
- I ported KRF to FreeBSD
- Added the ability for KRF to target processes by PID, GID, UID, or if it had a specific file open
- Wrote LLVM passes for static analysis
- Upstreamed LLVM changes
- Learned how to use Binary Ninja and its API
- Picked up good coding practices
- Gained a sense of the security industry
I also met some incredible people. I would like to give special thanks to my mentor Will Woodruff (@8x5clPW2), who was always willing to talk over an implementation, idea, or review my pull requests. I can’t wait to apply what I’ve learned at Trail of Bits as I move forward in my career.