
On LibraBFT’s use of broadcasts
LibraBFT is the Byzantine Fault Tolerant (BFT) consensus algorithm used by the recently released Libra cryptocurrency. LibraBFT is based on another BFT consensus algorithm called HotStuff. While some have noted the similarities between the two algorithms, they differ in some crucial respects. In this post we highlight one such difference: in LibraBFT, non-leaders perform broadcasts. This has implications on liveness analysis, communication complexity, and leader election. We delve into each of these topics following a brief review of what BFT consensus algorithms are and why they are useful.
A brief history of BFT consensus algorithms
The term Byzantine Fault Tolerant (BFT) originates from a paper by Lamport, Shostak, and Pease. In that paper, the authors consider a fictional scenario in which a group of Byzantine generals are considering whether to attack a city. The problem is that some of the generals are traitors. The question is, if the traitors spread misinformation, then under what conditions can the group agree to attack or retreat from the city? Note that neither attacking nor retreating is considered more favorable than the other: the problem is simply to agree on one action!
This scenario is a metaphor for one that commonly arises in distributed systems: the generals are nodes in a network, the traitors are faulty nodes, and attacking the city is, say, committing a transaction to a database.
The Lamport et al. paper proposes a solution to this problem. However, the solution implicitly assumes a synchronous network, which means that messages between nodes are delivered within a fixed, known time bound. Compare this to an asynchronous network, where messages can be arbitrarily delayed and even reordered.
Dwork, Lynch, and Stockmeyer were the first to propose deterministic algorithms that solve the Byzantine generals problem for “partially synchronous” networks. (Earlier, Rabin and Ben-Or had proposed randomized algorithms.) Dwork et al.’s analysis of what it means for a network to be “partially synchronous” was a significant contribution to the study of BFT algorithms. However, the purpose of Dwork et al.’s algorithms appears to have been to establish the existence of such solutions. Thus, their algorithms are of more theoretical than practical interest.
Toward the end of the century, Castro and Liskov proposed a solution on which many contemporary algorithms have been based (e.g., Tendermint, described below). Castro and Liskov’s algorithm, called Practical Byzantine Fault Tolerance (PBFT) works as follows. Each round has a designated leader chosen from among the nodes, and each round is composed of three phases. Roughly, in the first phase, the leader proposes a command for all nodes to execute; in the second phase, the nodes vote on the command; and in the third phase, the nodes acknowledge receipt of each others’ votes and execute the command. When a node believes that a round has gone on for too long, it sends a timeout message to all other nodes. Nodes must agree that a round should timeout. The process is somewhat complicated. PBFT, as a whole, works up to when ⌊(n-1)/3⌋ of the n nodes are faulty, which is the best that one can do.
In order to circumvent a classic impossibility result of Fischer, Lynch, and Paterson, PBFT prioritizes safety over liveness. This means that, say, a leader could propose a command and that command could fail to be executed, e.g., because of network problems. However, the algorithm is safe in the sense that if two non-faulty nodes execute some sequence of commands, then one is necessarily a prefix of the other.
It is interesting to note how PBFT uses broadcasts. During the first phase of each round, the leader broadcasts to all nodes. But, during the second and third phases, all nodes (not just the leader) broadcast to one another.

Many variants of PBFT have been proposed. One notable example is Tendermint. Like PBFT, Tendermint proceeds in rounds, each round is divided into three phases, and the use of broadcasts in each phase is similar. However, whereas timeouts in PBFT occur with respect to entire rounds, timeouts in Tendermint occur with respect to individual phases, which many regard as a simpler strategy. (See Dahlia Malkhi’s discussion of Tendermint for additional discussion.) Also, Tendermint has a well-tested implementation that is actively developed. For this reason, if none other, Tendermint has seen widespread use.
HotStuff may also be regarded as a variant of PBFT. The HotStuff algorithm is “pipelined” so that timing out in a round is essentially no different than timing out in a phase. But perhaps HotStuff’s most notable improvement over PBFT is its reduced “authenticator complexity.” As defined in the HotStuff paper, “an authenticator is either a partial signature or a signature” (page 4). The paper argues that “Authenticator complexity is a useful measure of communication complexity… it hides unnecessary details about the transmission topology… n messages carrying one authenticator count the same as one message carrying n authenticators.”
HotStuff achieves reduced authenticator complexity, in part, by using threshold signatures. This allows non-leaders to send their messages to only the leader and not to one another. For example, when voting on a command, nodes in HotStuff send their “share” of a signature to the leader. Once the leader has accumulated 2⌊(n-1)/3⌋ + 1 such shares, it broadcasts the combined signature to all other nodes. The other phases of the HotStuff algorithm are similar. In this way, HotStuff achieves linear authenticator complexity.
LibraBFT
LibraBFT is the consensus algorithm used by the Libra cryptocurrency. LibraBFT is based on HotStuff. According to the Libra authors, there were “three reasons for selecting the HotStuff protocol as the basis for LibraBFT: (1) simplicity and modularity of the safety argument; (2) ability to easily integrate consensus with execution; and (3) promising performance in early experiments.”
LibraBFT and HotStuff are very similar. For example, LibraBFT retains HotStuff’s pipelined design. Furthermore, when voting on a command (or “block” to use LibraBFT’s terminology), nodes send their votes to only the leader and not to all other nodes.
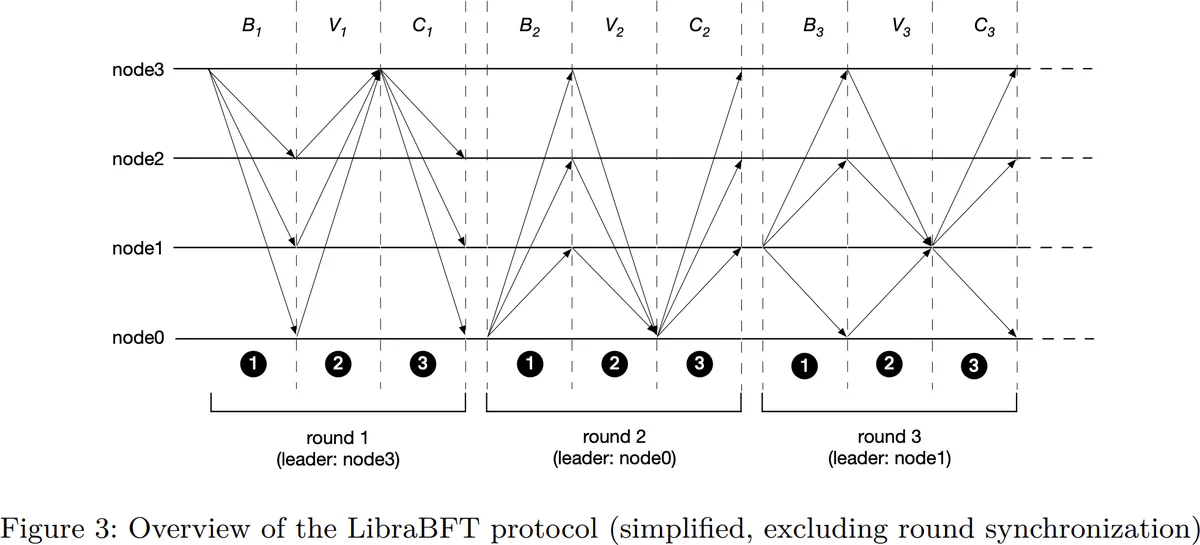
However, to achieve certain goals (explained below), LibraBFT uses broadcasts in ways that HotStuff does not. (In this way, LibraBFT resembles its distant ancestor, PBFT.) Specifically, LibraBFT requires non-leader nodes to perform broadcasts under the following circumstances:
- Nodes regularly synchronize their states using broadcasts.
- When a timeout is reached, e.g., because of network problems or a faulty leader, nodes send a timeout message to all other nodes.
The use of broadcasts for state synchronization makes it easier to establish a liveness result for LibraBFT. The reason for broadcasting timeouts is not given in the LibraBFT paper. However, as we explain below, we suspect it is to allow for the future use of an adaptive leader election mechanism. Despite these advantages, the additional broadcasts have the unfortunate side-effect of increasing the algorithm’s communication complexity. However, such an increase in communication complexity may be unavoidable. (Neither the state synchronization broadcasts nor the timeout broadcasts should affect the algorithm’s safety.)
Note: A recent blog post entitled “Libra: The Path Forward” makes clear that LibraBFT is a work-in-progress. Perhaps for this reason, there are discrepancies between LibraBFT as defined in the LibraBFT paper and as implemented in the Libra source code. For the remainder of this blog post, we focus on the former. We point out a couple of the differences between the LibraBFT specification and the Libra source code below. (Also note that, while the LibraBFT paper does contain code, that code is not part of Libra itself, but of a simulator. The LibraBFT authors “intend to share the code for this simulator and provide experimental results in a subsequent version of the report” (page 4). That version of the report has not yet been released.)
Liveness analysis
In LibraBFT, “nodes broadcast their states at least once per period of time [the minimum broadcast interval] 𝐼 > 0” (page 22). No similar notion exists in HotStuff. Unsurprisingly, this makes it easier to establish a liveness result for LibraBFT. However, liveness analysis of the two algorithms differ in other ways, as we now explain.
HotStuff’s liveness theorem asserts that, under certain technical conditions including that the round leader is non-faulty, there exists a time bound within which all non-faulty nodes execute a command and move on to the next round. The liveness theorem is parameterized by two functions: Leader and NextView. Leader is a function of the round number and determines the leader of that round. The arguments of NextView are not given specifically, but include at least the round number. NextView determines when round timeout “interrupts” are generated.
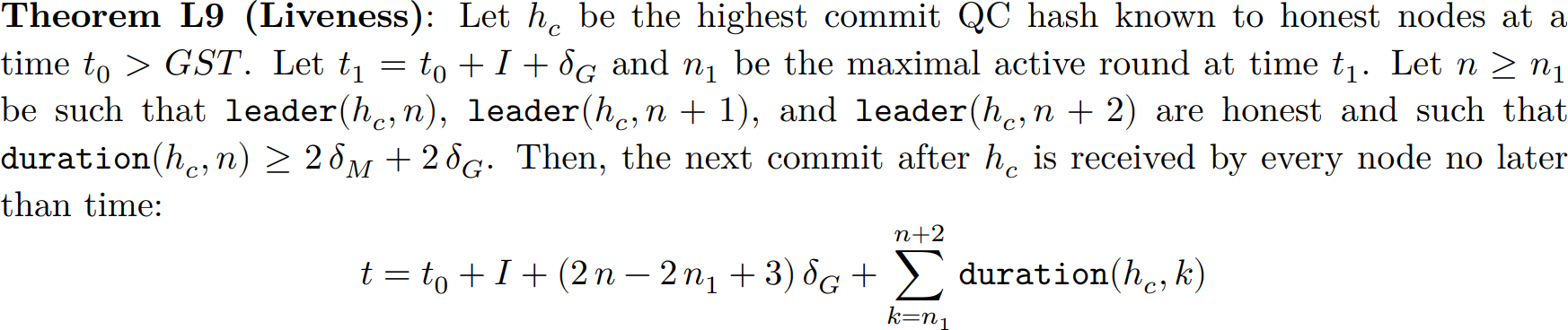
LibraBFT’s liveness theorem has a similar form. However, there are two significant differences. First, LibraBFT’s analogs of the Leader and NextView functions are not left as parameters, but are given explicitly. Second, the time bound within which a command is executed is not merely to asserted to exist, but is also given explicitly.
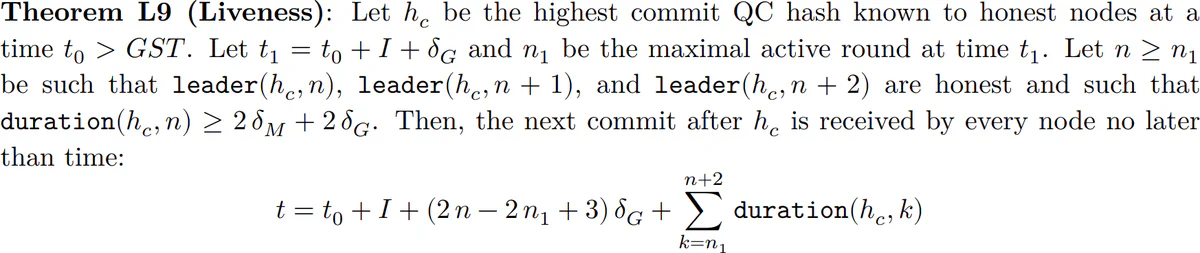
Of note is the fact that LibraBFT’s explicit time bound features 𝐼, the minimum broadcast interval, mentioned above. The appearance of 𝐼 demonstrates that LibraBFT’s liveness analysis differs fundamentally from that of HotStuff, and is not merely a byproduct of explicitly given Leader and NextView mechanisms.
We would also point out that this is a place where LibraBFT specification and the Libra source code do not exactly match. In LibraBFT, nodes broadcast their states to one another using DataSyncNotification messages (defined in Appendix A.3 of the LibraBFT paper). Nothing analogous to a DataSyncNotification message seems to exist within the Libra source code. For example, if one looks at the start_event_processing function from Libra’s chained_bft module, one can see calls to functions that process proposals, votes, etc. However, there is no call that would seem to process something resembling a DataSyncNotification message.
fn start_event_processing(
&self,
event_processor: ConcurrentEventProcessor,
executor: TaskExecutor,
...
) {
executor.spawn(Self::process_new_round_events(...)...);
executor.spawn(Self::process_proposals(...)...);
executor.spawn(Self::process_winning_proposals(...)...);
executor.spawn(Self::process_block_retrievals(...)...);
executor.spawn(Self::process_chunk_retrievals(...)...);
executor.spawn(Self::process_votes(...)...);
executor.spawn(Self::process_new_round_msg(...)...);
executor.spawn(Self::process_outgoing_pacemaker_timeouts(...)...);
}start_event_processing function from Libra’s chained_bft module. Note that none of the calls seem to process something resembling a LibraBFT DataSyncNotification message.The bottom line is that the LibraBFT liveness analysis does not directly apply to the LibraBFT source code in its present form. However, as mentioned above, LibraBFT is a work-in-progress. So, the existence of some discrepancies between the LibraBFT specification and the Libra source code is not surprising.
Communication complexity
As mentioned above in the description of HotStuff, HotStuff achieves linear authenticator complexity, where “an authenticator is either a partial signature or a signature” sent in a network message in a single round. What is LibraBFT’s authenticator complexity? It is unclear and somewhat ambiguous.
The LibraBFT paper does not mention “authenticator complexity” specifically, though it does claim that “LibraBFT has two desirable properties that BFT consensus protocols preceding HotStuff were not able to simultaneously support — linearity and responsiveness. … Informally, linearity guarantees that driving transaction commits incurs only linear communication…” (page 2). The claim is not addressed later in the paper. As we argue, LibraBFT’s authenticator complexity is at least O(n2), where n is the number of nodes. So, either the authors were not referring to authenticator complexity, or the claim is some sort of an oversight.
When a LibraBFT node believes that a round has gone on for too long, it broadcasts a timeout message to all other nodes. These timeout messages are signed. Therefore, LibraBFT’s authenticator complexity is at least O(n2).
How does LibraBFT’s use of broadcasts in state synchronization affect authenticator complexity?
State synchronization is parameterized by the minimum broadcast interval, 𝐼, mentioned above in the discussion of liveness analysis. The LibraBFT paper states that “nodes broadcast their states at least once per period of time 𝐼 > 0” (page 22). Taking this into account, the authenticator complexity of LibraBFT should be not just a function of n, but also of 𝐼.
However, the paper’s Appendix A.3 states “we have assumed that [data-synchronization messages] are transmitted over authenticated channels and omitted message signatures” (page 36). One could use this fact to argue that data synchronization does not affect authenticator complexity (though, that would feel a lot like cheating).
So, LibraBFT’s authenticator complexity is at least O(n2) due to its use of timeout broadcasts. It could be more, depending upon one’s assumptions about the network.
To be clear, this is a worst case analysis. In the common case, timeouts will not occur. Thus, if 𝐼 is large, say, many multiples of the typical round duration, then LibraBFT’s performance will be close to linear.
One final point is worth mentioning. HotStuff uses a predictable leader election strategy. As explained in the next section, the Libra authors are trying to avoid using such a strategy. To the best of our knowledge, no sub-quadratic adaptive leader election strategy currently exists. Thus, in comparing the communication complexity of HotStuff and LibraBFT, some increase may be unavoidable.
Leader election
At the time of this writing, the Libra source code’s leader election strategy is round-robin. However, the LibraBFT authors note that this strategy makes round leaders predictable, which facilitates denial-of-service attacks. In considering alternatives, the authors note that depending on hashes in a naive way could facilitate “grinding attacks,” e.g., where an attacker influences the hash in such a way as to increase the likelihood of a particular node being selected the leader.
To address the former problem and circumvent the latter, the authors state, “we intend to use a verifiable random function (VRF) in the future.” (In fact, a VRF is already implemented in the Libra source code, though it does not yet seem to be used.) In the next two paragraphs, we explain what VRFs are. Then, following a brief explanation of what it means for a LibraBFT block to be “committed,” we explain how LibraBFT’s proposed use of VRFs in leader elections is enabled by its use of broadcasts.
Intuitively, a VRF is a function that, given some input, produces two outputs: a random-looking value, and a proof that the value was derived from the input. The function is expected to have two properties. First, it should not be obvious how the random-looking value was derived from the input. Second, it should be possible to convince an observer that the random-looking value was derived from the input, even though that fact is not obvious. This latter property is made possible via the proof.
A simple example of a VRF is given in Section 4 of Goldberg, Reyzin, Papadopoulos, and Vcelak’s draft RFC. In that example, the random-looking value is an RSA signature computed over the hash of the input, and the proof is the hash. An observer can verify the proof by checking that the input has the hash, and that the signature corresponds to the hash. (Note: for production code, we recommend using the elliptic-curve-based VRF of Section 5 of the RFC, and not the RSA-based VRF of Section 4.)
We now briefly explain what it means for a LibraBFT block to be “committed.” In LibraBFT, blocks and quorum certificates alternate to form a chain:
B0 ← C0 ← B1 ← C1 ← B2 ← C2 ← ⋯
These blocks (certificates) need not be proposed (assembled) in contiguous rounds; there could be arbitrarily large gaps between them. A block is said to be “committed” when: (1) it appears below two other blocks, (2) all three blocks have associated quorum certificates, and (3) the blocks were proposed in contiguous rounds.
The reason for this rule is a bit technical. But, intuitively, a “committed” block is considered permanent by all non-faulty nodes. In contrast, a block that appears below fewer than two certified blocks is considered impermanent, and may have to be abandoned in favor of another block.
The LibraBFT authors intend to use VRFs in leader elections as follows. Each node will have its own instance of some VRF (e.g., a VRF instantiated with a private key belonging to the node). The leader for round i will be determined using the VRF instance of the round leader for the most recently committed block. That VRF instance will determine a seed for a pseudo-random function (PRF). The resulting PRF instance will then determine the leader for round i and each subsequent round until a new block becomes committed. The reason for using two functions like this is (we believe) so that round leaders can be determined even if the proposer of the most recently committed block goes offline.
We now explain how LibraBFT’s proposed use of VRFs in leader elections is enabled by its use of broadcasts. Or, more specifically, we explain why LibraBFT’s proposed use of VRFs would not work if a node could send a timeout message to just one other node, as is the case in HotStuff. The purpose of a timeout message is to tell the next round leader to start the next round. But, as we show in the next several paragraphs, who that next leader is can depend upon the cause of the timeout.
Suppose that in contiguous rounds i-2, i-1, and i, blocks Bm-2, Bm-1, and Bm are proposed. Further suppose that the leader for round i assembles a quorum certificate Cm and broadcasts it to all other nodes. Thus, at the start of round i+1, the most recently committed block is Bm-2:
B0 ← C0 ← ⋯ ← Bm-2 ← Cm-2 ← Bm-1 ← Cm-1 ← Bm ← Cm
But suppose that the leader for round i does not receive a block proposal for round i+1 within a reasonable timeframe. If the leader for round i could send a timeout message to just one other node, to whom should she send it? (Note that the leader for round i plays no special role in detecting or announcing the timeout of round i+1.)
Consider the following two explanations for why the leader for round i does not receive a block proposal for round i+1.
- Case 1: The leader for round i+1 is faulty and never proposed a block. In this case, the most recently committed block at round i+2 is still Bm-2. Thus, the leader for round i+2 should be determined by the same PRF instance that determined the leader for round i+1. If the leader for round i could send a timeout message to just one other node, she should send it to the leader determined by this existing PRF instance.
- Case 2: There is a network delay. The leader for round i+1 proposed a block and assembled a quorum certificate, but the leader for round i did not receive them in time. In this case, the most recently committed block at round i+2 is Bm-1. Thus, the leader for round i+2 should be determined by a new PRF instance, one seeded by the VRF instance belonging to the proposer of Bm-1. If the leader for round i could send a timeout message to just one other node, she should send it to the leader determined by this new PRF instance.
This ambiguity is resolved by having the leader for round i send its timeout message to all other nodes. We would not be surprised if the LibraBFT authors introduced timeout broadcasts to address this type of scenario specifically.
Finally, note that a similar problem does not exist in HotStuff. In HotStuff, the round leader is determined by “some deterministic mapping from view number to a replica, eventually rotating through all replicas,” and does not depend on the most recently committed block. On the other hand, the predictability of round leaders makes HotStuff susceptible to denial-of-service attacks, which the LibraBFT authors are trying to avoid.
LibraBFT and HotStuff are distinct algorithms
LibraBFT and HotStuff are very similar, but the two algorithms differ in some crucial respects. In LibraBFT, non-leaders perform broadcasts. The use of broadcasts in state synchronization makes it easier to establish a liveness result for LibraBFT. We suspect that timeout broadcasts were introduced to allow for the future use of an adaptive leader election mechanism, e.g., one based on VRFs. Despite these advantages, the additional broadcasts increase the algorithm’s communication complexity. However, this increase in communication complexity may be unavoidable.
We intend to keep a close eye on Libra. If you are developing a Libra application, please consider us for your security review.
Updated July 16, 2019.