
Optimizing Lifted Bitcode with Dead Store Elimination
Tim Alberdingk Thijm
As part of my Springternship at Trail of Bits, I created a series of data-flow-based optimizations that eliminate most “dead” stores that emulate writes to machine code registers in McSema-lifted programs. For example, applying my dead-store-elimination (DSE) passes to Apache httpd eliminated 117,059 stores, or 50% of the store operations to Remill’s register State structure. If you’re a regular McSema user, then pull the latest code to reap the benefits. DSE is now enabled by default.
Now, you might be thinking, “Back it up, Tim, isn’t DSE a fundamental optimization that’s already part of LLVM?” You would be right to ask this (and the answer is yes), because if you’ve used LLVM then you know that it has an excellent optimizer. However, despite LLVM’s excellence, the truth is that, like any optimizer, LLVM can only cut instructions it knows to be unnecessary. The Remill dead code eliminator has the advantage of possessing more higher-level information about the nature of lifted bitcode, which lets it be more aggressive than LLVM in performing its optimizations.
But every question answered just raises more questions! You might now be thinking, “LLVM only does safe optimizations. This DSE is more aggressive… How do we know it didn’t break the lifted httpd program?” Fear not! The dead store elimination tool is specifically designed to perform a whole-program analysis on lifted bitcode that has already been optimized. This ensures that it can find dead instructions with the maximum possible context, avoiding mistakes where the program assumes some code won’t be used. The output is a fully-functioning httpd executable, minus a mountain of useless computation.
What Happens When We Lift
The backbone of Remill/McSema’s lifted bitcode is the State structure, which models the machine’s register state. Remill emulates reads and writes to registers by using LLVM load and store instructions that operate on pointers into the State structure. Here’s what Remill’s State structure might look like for a toy x86-like architecture with two registers: eax and ebx.
struct State {
uint32_t eax;
uint32_t ebx;
};This would be represented in LLVM as follows:
%struct.State = type { i32, i32 }Let’s say we’re looking at a few lines of machine code in this architecture:
mov eax, ebx
add eax, 10A heavily-simplified version of the LLVM IR for this code might look like this:

The first two lines derive pointers to the memory backing the emulated eax and ebx registers (%eax_addr and %ebx_addr, respectively) from a pointer to the state (%state). This derivation is performed using the getelementptr instruction, and is equivalent to the C code &(state->eax) and &(state->ebx). The next two lines represent the mov instruction, where the emulated ebx register is read (load), and the value read is then written to (store) the emulated eax register. Finally, the last three lines represent the add instruction.
We can see that %ebx_0 is stored to %eax_ptr and then %eax_0 is loaded from the %eax_ptr without any intervening stores to the %eax_ptr pointer. This means that the load into %eax_0 is redundant. We can simply use %ebx_0 anywhere that %eax_0 is used, i.e. forward the store to the load.
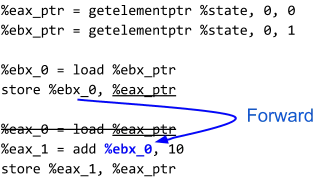
Next, we might also notice that the store %ebx_0, %eax_ptr instruction isn’t particularly useful either, since store %eax_1, %eax_ptr happens before %eax_ptr is read from again. In fact, this is a dead store. Eliminating these kinds of dead stores is what my optimization focuses on!

This process will go on in real bitcode until nothing more can be forwarded or killed.
So now that you have an understanding of how dead store elimination works, let’s explore how we could teach this technique to a computer.
As it turns out, each of the above steps are related to data-flow analyses. To build our eliminator, we’re going to want to figure out how to represent these decisions using data-flow techniques.
Building the Eliminator
With introductions out of the way, let’s get into how this dead code elimination is supposed to work.
Playing the Slots
The DSE pass needs to recognize loads/stores through %eax_ptr and %ebx_ptr as being different. The DSE pass does this by chopping up the State structure into “slots”, which roughly represent registers, with some small distinctions for cases where we bundle sequence types like arrays and vectors as one logical object. The slots for our simplified State structure are:

After chopping up the State structure, the DSE pass tries to label instructions with the slot to which that instruction might refer. But how do we even do this labelling? I mentioned earlier that we have deeper knowledge about the nature of lifted bitcode, and here’s where we get to use it. In lifted bitcode, the State structure is passed into every lifted function as an argument. Every load or store to an emulated register is therefore derived from this State pointer (e.g. via getelementptr, bitcast, etc.). Each such derivation results in a new pointer that is possibly offsetted from its base. Therefore, to determine the slot referenced by any given pointer, we need to calculate that pointer’s offset, and map the offset back to the slot. If it’s a derived pointer, then we need to calculate the base pointer’s offset. And if the base pointer is derived then… really, it’s just offsets all the way down.
And They Were Slot-mates
The case that interests us most is when two instructions get friendly and alias to the same slot. That’s all it takes for one instruction to kill another: in Remill, it’s the law of the jungle.
To identify instructions which alias, we use a ForwardAliasVisitor (FAV). The FAV keeps track of all the pointers to offsets to the state structure and all the instructions involving accesses to the state structure in two respective maps. As the name implies, it iterates forward through the instructions it’s given, keeping a tally if it notices that one of the addresses it’s tracking has been modified or used.
Here’s how this information is built up from our instructions:
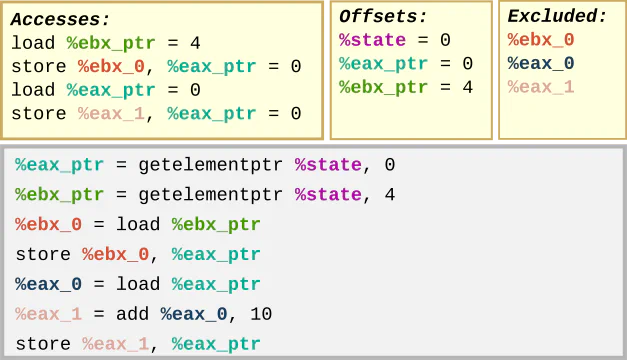
Each time the FAV visits an instruction, it checks if updates need to be made to its maps.
The accesses map stores the instructions which access state offsets. We’ll use this map later to determine which load and store instructions could potentially alias. You can already see here that the offsets of three instructions are all the same: a clear sign that we can eliminate instructions later!
The offsets map ensures the accesses map can get the right information. Starting with the base %state pointer, the offsets map accumulates any pointers that may be referenced as the program runs. You can think of it as the address book which the loads and stores use to make calls to different parts of the state structure.
The third data structure shown here is the exclude set. This keeps track of all the other values instructions might refer to that we know shouldn’t contact the state structure. These would be the values read by load instructions, or pointers to alloca’d memory. In this example, you can also see that if a value is already in the offsets map or exclude set, any value produced from one such value will remain in the same set (e.g. %eax_1 is excluded since %eax_0 already was). You can think of the exclude set as the Do-Not-Call list to the offset map’s address book.
The FAV picks through the code and ensures that it’s able to visit every instruction of every function. Once it’s done, we can associate the relevant state slot to each load and store as LLVM metadata, and move on to the violent crescendo of the dead code eliminator: eliminating the dead instructions!
You’ll Be Stone Dead In a Moment
Now it’s time for us to pick through the aliasing instructions and see if any of them can be eliminated. We have a few techniques available to us, following a similar pattern as before. We’ll look through the instructions and determine their viability for elimination as a data-flow.
Sequentially, we run the ForwardingBlockVisitor to forward unnecessary loads and stores and then use the LiveSetBlockVisitor to choose which ones to eliminate. For the purpose of this post, however, we’ll cover these steps in reverse order to get a better sense of why they’re useful.
Live and Set Live
The LiveSetBlockVisitor (LSBV) has the illustrious job of inspecting each basic block of a module’s functions to determine the overall liveness of slots in the State. Briefly, live variable analysis allows the DSE to check if a store will be overwritten (“killed”) before a load accesses (“revives”) the slot. The LiveSet of LSBV is a bitset representing the liveness of each slot in the State structure: if a slot is live, the bit in the LiveSet corresponding to the slot’s index is set to 1.
The LSBV proceeds from the terminating blocks (blocks ending with ret instructions) of the function back to the entry block, keeping track of a live set for each block. This allows it to determine the live set of preceding blocks based on the liveness of their successors.
Here’s an example of how an LSBV pass proceeds. Starting from the terminating blocks, we iterate through the block’s instructions backwards and update its live set as we do. Once we’re finished, we add the block’s predecessors to our worklist and continue with them. After analyzing the entry block, we finish the pass. Any stores visited while a slot was already dead can be declared dead stores, which we can then remove.
In order to avoid any undefined behaviour, the LSBV had a few generalizations in place. Some instructions, like resume or indirectbr, that could cause uncertain changes to the block’s live set conservatively mark all slots as live. This provides a simple way of avoiding dangerous eliminations and an opportunity for future improvements.
Not To Be Forward, But…
Our work could end here with the LSBV, but there are still potential improvements we can make to the DSE. As mentioned earlier, we can “forward” some instructions by replacing unnecessary sequences of storing a value, loading that value and using that value with direct use of the value prior to the store. This is handled by the ForwardingBlockVisitor, another backward block visitor. Using the aliases gathered by the FAV, it can iterate through the instructions of the block from back to front, keeping track of the upcoming loads to each slot of the State. If we find an operation occurs earlier that accesses the same slot, we can forward it to cut down on the number of operations, as shown in the earlier elimination example.
Doing this step before the LSBV pass allows the LSBV to identify more dead instructions than before. Looking again at our example, we’ve now set up another store to be killed by the LSBV pass. This type of procedure allows us to remove more instructions than before by better exploiting our knowledge of when slots will be used next. Cascading eliminations this way is part of what allows DSE to remove so many instructions: if a store is removed, there may be more instructions rendered useless that can also be eliminated.
A DSE Diet Testimonial
Thanks to the slimming power of dead store elimination, we can make some impressive cuts to the number of instructions in our lifted code.
For an amd64 Apache httpd, we were able to generate the following report:
Candidate stores: 210,855
Dead stores: 117,059
Instructions removed from DSE: 273,322
Forwarded loads: 840
Forwarded stores: 2,222
Perfectly forwarded: 2,836
Forwarded by truncation: 215
Forwarded by casting: 11
Forwarded by reordering: 61
Could not forward: 1,558
Unanalyzed functions: 0
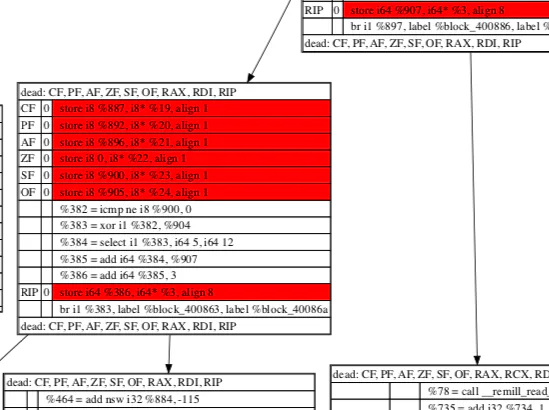
An additional feature of the DSE is the ability to generate DOT diagrams of the instructions removed. Currently, the DSE will produce three diagrams for each function visited, showing the offsets identified, the stores marked for removal, and the post-removal instructions.
Still Hungry for Optimizations?
While this may be the end of Tim’s work on the DSE for the time being, future improvements are already in the pipeline to make Remill/McSema’s lifted bitcode even leaner. Work will continue to handle cases that the DSE is currently not brave enough to take on, like sinking store instructions when a slot is only live down one branch, handling calls to other functions more precisely, and lifting live regions to allocas to benefit from LLVM’s mem2reg pass.
Think what Tim did was cool? Check out the “intern project” GitHub issue tags on McSema and Remill to get involved, talk to us on #binary-lifting channel of the Empire Hacking Slack, or reach out to us via our careers page.
Tim is starting a PhD in programming language theory this September at Princeton University, where he will try his hand at following instructions, instead of eliminating them.