
What are the current pain points of osquery?
You’re reading the second post in our four-part series about osquery. Read post number one for a snapshot of the tool’s current use, the reasons for its growing popularity among enterprise security teams, and how it stacks up against commercial alternatives.
osquery shows considerable potential to revolutionize the endpoint monitoring market. (For example, it greatly simplifies the detection of signed malware with Windows executable code signature verification.) However, the teams at five major tech firms and osquery developers whom we interviewed for this series say that the open source tool has room for improvement.
Some of these qualms relate to true limitations. However, we’ve also heard some recent grumbling among prospective users and industry competitors that doesn’t align with osquery’s actual shortcomings.
As with many rapidly improving open source projects, documentation updates lagging behind a blistering development schedule may be to blame for these misconceptions. So, before diving into what true pain points the osquery community should tackle next, let’s shed light on some current myths about osquery’s limitations.
Mythical limitations of osquery
“osquery has no support for containers”
Oh, but it does! Teams like Uptycs have poured significant development support into this much-requested feature within the past year. Currently, osquery can perform container introspection at the management host layer (more efficient) or it can operate in each container (more granularity) without dominating CPU.
“osquery cannot operate in real time”
osquery handles file integrity and process auditing for MacOS and Linux. It can also monitor user access, hardware events, and socket events in select operating systems. It performs these tasks through interaction with the audit kernel API. Unlike its other pull-based queries, these monitoring services create event-based logs in real time and ensure that osquery doesn’t miss important events between queries. These features are essential to osquery’s power in incident detection.
“osquery is high overhead”
osquery is a lightweight solution when correctly deployed and managed. As we’ll touch on later in the post, the leading causes of performance issues come from misconfiguration: scheduling runaway queries, performing event-based queries on high-traffic file paths, or running osquery in a resource-constrained environment without implementing CPU controls. In fact, respondents who implemented safeguards such as Cgroups were so confident in osquery’s performance that they deployed the tool on every endpoint, including production servers.
Current limitations of osquery; the facts
Demand for user support outstrips supply
For an open-source project, osquery offers a lot of user support; a website, an active slack channel, extensive documentation, and lots of blogs (like this one!). That said, the community can do better.
- Documentation updates have not matched pace with the growing list of project feature updates, leaving users unaware of new functionality or confused about how to use it.
- Confused users flocking to the osquery slack channel ask similar questions. Experts try to help these individuals instead of creating FAQs, writing comprehensive query packs, and making tutorials.
Users test feature integrity
Facebook has done an excellent job at thoroughly reviewing new code and hosting productive debates about how best to build new features. However, there has been a lack of oversight into the efficacy of new features. So far, this has been the job of users who report edge cases and unexpected behavior to the slack channel or github repo.
A recent example of this issue: Developers and users saw false negatives in file integrity monitoring for osquery. The audit backend contained multiple bugs that caused inaccurate logs. This has persisted unchecked since FIM was first enabled in 2015. Thankfully, our own Alessandro Gario is implementing a fix.
Issues with extensions
This crucial component of osquery has been causing problems for users. The issues stem from insufficient support during their development. osquery’s current SDK only provides the bare minimum needed to integrate with osquery. The documentation and APIs are also limited. Because of these factors, many extensions aren’t well-built or well-maintained, and therefore, introduce unreliable results.
Fortunately, the community has started to resolve the issues. Kolide’s osquery-go provides a rich SDK for developers to create osquery extensions with Go. Last week, we explained how to write an extension for osquery. We also released a repository of our own well-maintained osquery extensions that users can pull from (there’s only one in there right now but more to come, soon!). We intend to help the community navigate the extension-building process and to create a reliable source of updated extensions.
Limited platform support beyond Linux and macOS
Users are eager for osquery to support more platforms and provide better introspection on all endpoints. osquery’s current limit to just a subset of endpoints leaves holes in users’ monitoring capacity. Further, they noted that some supported platforms lacked important features.
For example, macOS and Linux platforms can collect usable real-time data about a variety of event types. Real-time data in osquery for Windows is limited to the Windows Event Log, which only exposes a stream of difficult-to-parse system data. No users whom we interviewed had successfully implemented or parsed these logs in their deployments.
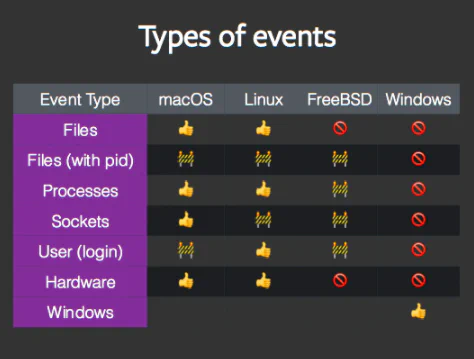
Readable real-time monitoring underpins osquery’s incident-detection capabilities. While scheduled queries can miss system events between queries, real-time event-based monitoring is less prone to false negatives. The absence of this feature in the Windows port greatly degrades osquery’s incident-detection utility for users running Windows machines in their fleets.
Runaway queries and guidance
Respondents reserved some of their harshest criticism for the lack of safeguards against bad queries, especially those that unexpectedly pulled an excessive amount of data. Sometimes, these runaway queries caused major issues for the larger fleet such as degraded endpoint system performance and clogged memory. In addition, malformed queries could flood data logs and rewrite over other data collected, causing other events to pass by undetected.
osquery’s watchdog feature does prevent some performance issues by killing any processes that consume too much CPU or memory. However, this is done without consideration of what’s running at the time. Well-formed audit-based queries often exceed the default quotas, killing processes unnecessarily. As a result, users turned off the feature to avoid missing essential data. A better solution would understand the scale of a user’s query and ask for confirmation.
Users also wanted smarter queries. One interviewee wanted guidance on the right query intervals for different types of system data. He also wanted to save wasted storage from overlapping data within different query packs. Though the issue is relatively cheap, it would be helpful if osquery could de-duplicate this data.
Insufficient debugging/diagnostics at scale
Users struggled with large-scale deployment of osquery, primarily because of difficulty debugging and diagnosing query issues in their fleets. One company reported that roughly 15% of nodes queried persist as pending for unknown reasons. Another reported that certain endpoints would occasionally “fall off the internet” without any apparent cause. Though users can restart osquery with the verbose setting to print information about every action performed, this option is primarily a tool for developers and is not user-friendly.
Deployment and maintenance issues
Every company implementing osquery tackles this ongoing struggle in a different way. We went into great detail in our previous post about the variety of tools and techniques they used to manage this problem. Despite support and documentation improvements, issues persist. One user reported ongoing troubles implementing osquery version updates on endpoints for which employees are admins.
Conclusion
After reading about all of these pain points, you might be wondering why osquery won multiple product awards this year, and why over 1,100 users have engaged with the development community’s Slack channel and GitHub repo. You might be wondering why the five top tech company teams we surveyed for this series reported that they liked osquery better than commercial fleet management tools
It’s simple. The tool has attracted a vibrant development community invested in its success. Every new development brings osquery closer to feature-parity with the equivalent components of competitors’ fully integrated – and higher-priced – security suites. As users commission companies like Trail of Bits to make those improvements, the entire community benefits.
That will be the topic of the third post in this series: osquery’s development requests. If you use osquery today and have requests you’d like to add to our research, please let us know! We’d love to hear from you.
How does your experience with osquery compare to the pains mentioned in this post? Do you have other complaints or issues that you’d like to see addressed in future releases? Tell us! Help us lead the way in improving osquery’s development and implementation.