
An extra bit of analysis for Clemency
This year’s DEF CON CTF used a unique hardware architecture, cLEMENCy, and only released a specification and reference tooling for it 24 hours before the final event began. cLEMENCy was purposefully designed to break existing tools and make writing new ones harder. This presented a formidable challenge given the timeboxed competition occurs over a single weekend.
Dozens of hackers around the internet are writing new shellcode today https://t.co/CQHbCQO8XW
— Jay Little (@computerality) July 27, 2017
Ryan, Sophia, and I wrote and used a Binary Ninja processor module for cLEMENCy during the event. This helped our team analyze challenges with Binary Ninja’s graph view and dataflow analyses faster than if we’d relied on the limited disassembler and debugger provided by the organizers. We are releasing this processor module today in the interest of helping others who want to try out the challenges on their own.
cLEMENCy creates a more equitable playing field in CTFs by degrading the ability to use advanced tools, like Manticore or a Cyber Reasoning System. It accomplishes this with architectural features such as:
- 9-bit bytes instead of 8-bits. This makes parsing the binary difficult. The byte length of the architecture of the system parsing a challenge does not match that in cLEMENCy. The start of a byte on both systems would only match every 9th byte.
- It’s Middle Endian. Every other architecture stores values in memory in one of two ways: from most significant byte to least significant (Big Endian), or least significant to most significant (Little Endian). Rather than storing a value like 0x123456 as 12 34 56 or 56 34 12, Middle Endian stores it as 34 56 12.
- Instructions have variable length opcodes. Instructions were anywhere from 18 to 54 bits, with opcodes being anywhere from 4 bits to 18 bits.
Someone started a defcon memes channel in the CTF slack. I love my team. #defconmemes @LegitBS_CTF pic.twitter.com/XO6bn3qK0K
— Evan (@WontonSlim) July 28, 2017
This required creativity in a short timespan. With only 24 hours’ head start, we needed to work fast if we wanted something usable before the end of the four-day competition. This would have been hard to do even with an amenable architecture. Here’s how we solved these problems to write and use a disassembler during the CTF:
- We expanded each 9-bit byte to a 16-bit short. Originally, I wrote some fancy bit masking and shifting to accomplish this, but then Ryan dropped a very simple script that did the same thing using the bitstream module. This had the side effect of doubling all memory offsets but that was trivial to correct.
- We made liberal use of slicing in Python. Our disassembler first converted the bytes to a string of bits, then rearranged them to match the representation in the reference document. After that, we took the path of speed of implementation rather than brevity to compare the exact number of bits per opcode to identify and parse them.
- We made instructions more verbose. The Load and Store instructions iterated over a specified number of registers from a starting point, copying each from or into a memory location. Rather than displaying the starting register and count alone, we expanded the entire list, making it much easier to understand the effects of the instruction in the disassembly at a glance.
With an implemented processor module, we could view and interact with the challenges, define functions with automated analyses, and control how assembly instructions were represented.
We also tried to write an LLIL lifter. This was not possible. You could either have consistent register math or consistent memory addresses, but not both. The weird three-byte register widths and the doubled memory addresses were incompatible. All was not lost, since enough instructions were liftable to locate strings with the dataflow analysis.
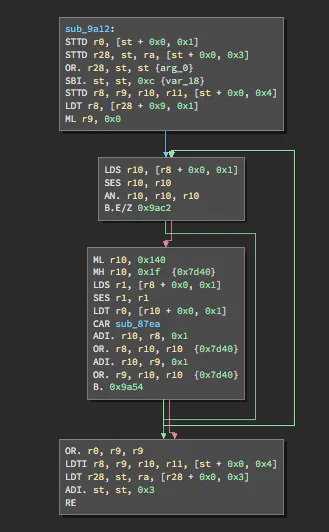
If you’d like to get started with our Binja module, you can find our Architecture and BinaryView plugins, as well as a script to pack and unpack the challenges, on our Github.
LegitBS has open-sourced their cLEMENCy tools. The challenges will be available shortly. We look forward to seeing how other teams dealt with cLEMENCy!
UPDATE: The challenges are now available. PPP, Chris Eagle, and Lab RATS released their processor modules for cLEMENCy.