
Breaking Down Binary Ninja’s Low Level IL
Hi, I’m Josh. I recently joined the team at Trail of Bits, and I’ve been an evangelist and plugin writer for the Binary Ninja reversing platform for a while now. I’ve developed plugins that make reversing easier and extended Binary Ninja’s architecture support to assist in playing the microcorruption CTF. One of my favorite features of Binary Ninja is the Low Level IL (LLIL), which enables development of powerful program analysis tools. At Trail of Bits, we have used the LLIL to automate processing of a large number of CTF binaries, as well as automate identifying memory corruptions.
I often get asked how the LLIL works. In this blog post, I answer common questions about the basics of LLIL and demonstrate how to use the Python API to write a simple function that operates on the LLIL. In a future post, I will demonstrate how to use the API to write plugins that use both the LLIL and Binary Ninja’s own dataflow analysis.
What is the Low Level IL?
Compilers use an intermediate representation (IR) to analyze and optimize the code being compiled. This IR is generated by translating the source language to a single standard language understood by the components of the toolchain. The toolchain components can then perform generic tasks on a variety of architectures without having to implement those tasks individually.
Similarly, Binary Ninja not only disassembles binary code, but also leverages the power of its own IR, called Low Level IL, in order to perform dataflow analysis. The dataflow analysis makes it possible for users to query register values and stack contents at arbitrary instructions. This analysis is architecture-agnostic because it is performed on the LLIL, not the assembly. In fact, I automatically got this dataflow analysis for free when I wrote the lifter for the MSP430 architecture.
Let’s jump right in and see how the Low Level IL works.
Viewing the Low Level IL
Within the UI, the Low Level IL is viewable only in Graph View. It can be accessed either through the “Options” menu in the bottom right corner, or via the i hotkey. The difference between IL View and Graph View is noticeable; the IL View looks much closer to a high level language with its use of infix notation. This, combined with the fact that the IL is a standardized set of instructions that all architectures are translated to, makes working with an unfamiliar language easy.
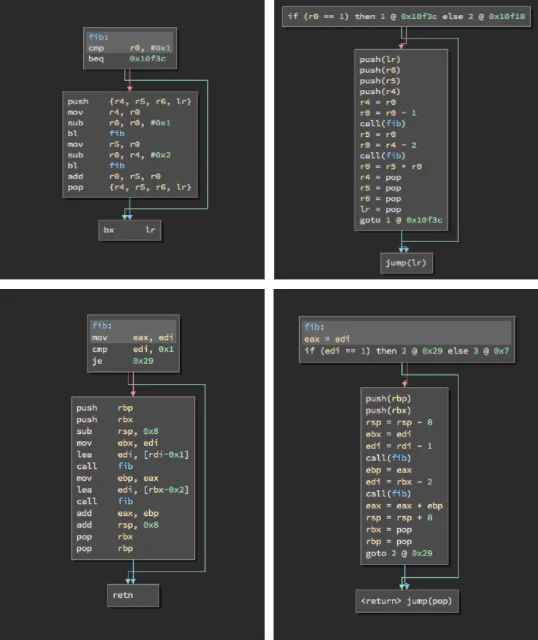
If you aren’t familiar with this particular architecture, then you might not easily understand the semantics of the assembly code. However, the meaning of the LLIL is clear. You might also notice that there are often more LLIL instructions than there are assembly instructions. The translation of assembly to LLIL is actually a one-to-many rather than one-to-one translation because the LLIL is a simplified representation of an instruction set. For example, the x86 repne cmpsb instruction will even generate branches and loops in the LLIL:
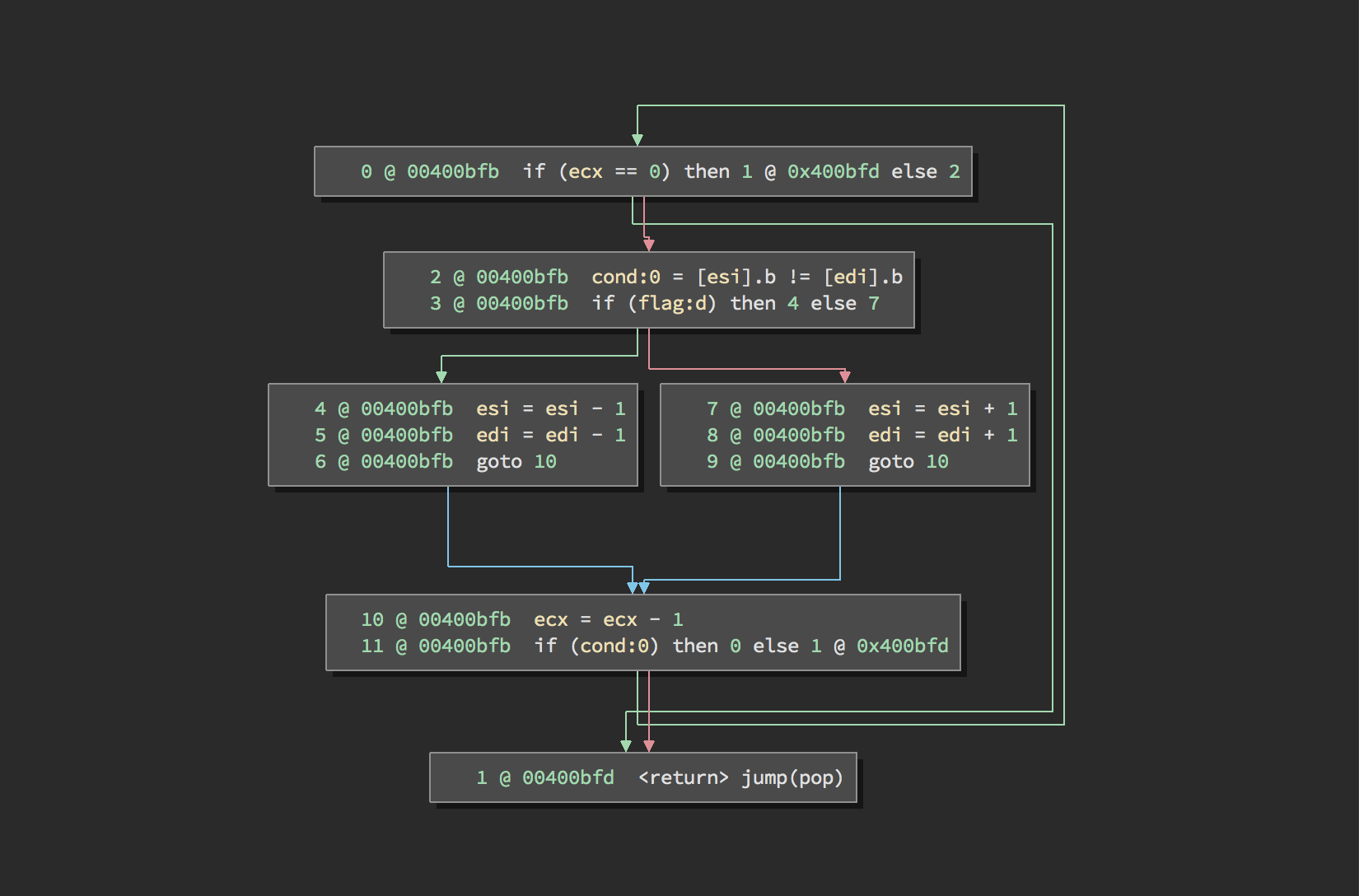
repne cmpsbHow is analysis performed on the LLIL? To figure that out, we’ll first dive into how the LLIL is structured.
Low Level IL Structure
According to the API documentation, LLIL instructions have a tree-based structure. The root of an LLIL instruction tree is an expression consisting of an operation and zero to four operands as child nodes. The child nodes may be integers, strings, arrays of integers, or another expression. As each child expression can have its own child expressions, an instruction tree of arbitrary order and complexity can be built. Below are some example expressions and their operands:
| Operation | Operand 1 | Operand 2 | Operand 3 | Operand 4 |
|---|---|---|---|---|
LLIL_NOP | ||||
LLIL_SET_REG | dest: string or integer | src: expression | ||
LLIL_LOAD | src: expression | |||
LLIL_CONST | constant: integer | |||
LLIL_IF | condition: expression | true: integer | false: integer | |
LLIL_JUMP_TO | dest: expression | targets: array of integers |
Let’s look at a couple examples of lifted x86, to get a better understanding of how these trees are generated when lifting an instruction: first, a simple mov instruction, and then a more complex lea instruction.
Example: mov eax, 2
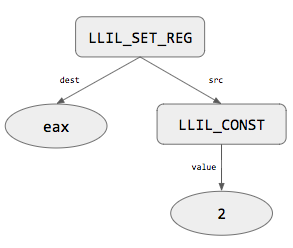
mov eax, 2This instruction has a single operation, mov, which is translated to the LLIL expression LLIL_SET_REG. The LLIL_SET_REG instruction has two child nodes: dest and src. dest is a reg node, which is just a string representing the register that will be set. src is another expression representing how the dest register will be set.
In our x86 instruction, the destination register is eax, so the dest child is just eax; easy enough. What is the source expression? Well, 2 is a constant value, so it will be translated into an LLIL_CONST expression. An LLIL_CONST expression has a single child node, constant, which is an integer. No other nodes in the tree have children, so the instruction is complete. Putting it all together, we get the tree above.
Example: lea eax, [edx+ecx*4]
![LLIL tree for lea eax, [edx+ecx*4]](96674a7c55f1454bfa163265161f38ff.png)
lea eax, [edx+ecx*4]The end result of this instruction is also to set the value of a register. The root of this tree will also be an LLIL_SET_REG, and its dest will be eax. The src expression is a mathematical expression consisting of an addition and multiplication…or is it?
If we add parenthesis to explicitly define the order of operations, we get (edx + (ecx * 4)); thus, the root of the src sub-tree will be an LLIL_ADD expression, which has two child nodes: left and right, both of which are expressions. The left side of the addition is a register, so the left expression in our tree will be an LLIL_REG expression. This expression only has a single child. The right side of the addition is our multiplication, but the multiplier in an lea instruction has to be a power of 2, which can be translated to a left-shift operation, and that’s exactly what the lifter does: ecx * 4 becomes ecx << 2. So, the right expression in the tree is actually an LLIL_LSL expression (Logical Shift Left).
The LLIL_LSL expression also has left and right child expression nodes. For our left-shift operation, the left side is the ecx register, and the right side is the constant 2. We already know that both LLIL_REG and LLIL_CONST terminate with a string and integer, respectively. With the tree complete, we arrive at the tree presented above.
Now that we have an understanding of the structure of the LLIL, we are ready to dive into using the Python API. After reviewing features of the API, I will demonstrate a simple Python function to traverse an LLIL instruction and examine its tree structure.
Using the Python API
There are a few important classes related to the LLIL in the Python API: LowLevelILFunction, LowLevelILBasicBlock, and LowLevelILInstruction. There are a few others, like LowLevelILExpr and LowLevelILLabel, but those are more for writing a lifter rather than consuming IL.
Accessing Instructions
To begin playing with the IL, the first step is to get a reference to a function’s LLIL. This is accomplished through the low_level_il property of a Function object. If you’re in the GUI, you can get the LowLevelILFunction object for the currently displayed function using current_function.low_level_il or current_llil.
The LowLevelILFunction class has a lot of methods, but they’re basically all for implementing a lifter, not performing analysis. In fact, this class is really only useful for retrieving or enumerating basic blocks and instructions. The __iter__ method is implemented and iterates over the basic blocks of the LLIL function, and the __getitem__ method is implemented and retrieves an LLIL instruction based on its index. The LowLevelILBasicBlock class also implements __iter__, which iterates over the individual LowLevelILInstruction objects belonging to that basic block. Therefore, it is possible to iterate over the instructions of a LowLevelILFunction two different ways, depending on your needs:
# iterate over instructions using basic blocks
for bb in current_llil.basic_blocks:
for instruction in bb:
print instruction
# iterate over instructions directly
for index in range(len(current_llil)):
instruction = current_llil[index]
print instructionDirectly accessing an instruction is currently cumbersome. In Python, this is accomplished with function.get_low_level_il_at(function.arch, address). It should be noted that the Function.get_low_level_il_at() method returns a LowLevelILInstruction object for the first LLIL instruction at a given address; in the case of an instruction like repne cmpsb, you’ll have to increment the instruction index to access the other LLIL instructions.
Parsing Instructions
The real meat of the LLIL is exposed in LowLevelILInstruction objects. The common members shared by all instructions allow you to determine:
- The containing
functionof the LLIL instruction - The
addressof the assembly instruction lifted to LLIL - The
operationof the LLIL instruction - The
sizeof the operation (i.e. is this instruction manipulating abyte/short/long/long long)
As we saw in the table above, the operands vary by instruction. These can be accessed sequentially, via the operands member, or directly accessed by operand name (e.g. dest, left, etc). When accessing operands of an instruction that has a destination operand, the dest operand will always be the first element of the list.
Example: A Simple Recursive Traversal Function
A very simple example of consuming information from the LLIL is a recursive traversal of a LowLevelILInstruction. In the example below, the operation of the expression of an LLIL instruction is output to the console, as well as its operands. If an operand is also an expression, then the function traverses that expression as well, outputting its operation and operands in turn.
def traverse_IL(il, indent):
if isinstance(il, LowLevelILInstruction):
print '\t'*indent + il.operation.name
for o in il.operands:
traverse_IL(o, indent+1)
else:
print '\t'*indent + str(il)After copy-pasting this into the Binary Ninja console, select any instruction you wish to output the tree for. You can then use bv, current_function, and here to access the current BinaryView, the currently displayed function’s Function object, and the currently selected address, respectively. In the following example, I selected the ARM instruction ldr r3, [r11, #-0x8]:
![ARM instruction ldr r3, [r11, #-0x8] traversed in the Binary Ninja console](/2017/01/31/breaking-down-binary-ninjas-low-level-il/6995e603be1a1f6a0a03c448d84d739a_hu_ffab90442ecc3d68.webp)
Lifted IL vs Low Level IL
While reviewing the API, you might notice that there are function calls such as Function.get_lifted_il_at versus Function.get_low_level_il_at. This might make you unsure of which you should be processing for your analysis. The answer is fairly straight-forward: with almost no exceptions, you will always want to work with Low Level IL.
Lifted IL is what the lifter first generates when parsing the executable code; an optimized version is what is exposed as the Low Level IL to the user in the UI. To demonstrate this, try creating a new binary file, and fill it with a bunch of nop instructions, followed by a ret. After disassembling the function, and switching to IL view (by pressing i in Graph View), you will see that there is only a single IL instruction present: jump(pop). This is due to the nop instructions being optimized away.
It is possible to view the Lifted IL in the UI: check the box in Preferences for “Enable plugin development debugging mode.” Once checked, the “Options” tab at the bottom of the window will now present two options for viewing the IL. With the previous example, switching to Lifted IL view will now display a long list of nop instructions, in addition to the jump(pop).
In general, Lifted IL is not something you will need unless you’re developing an Architecture plugin.
Start Using the LLIL
In this blog post, I described the fundamentals of Binary Ninja’s Low Level IL, and how the Python API can be used to interact with it. Around the office, Ryan has used the LLIL and its data flow analysis to solve 2000 CTF challenge binaries by identifying a buffer to overflow and a canary value that had to remain intact in each. Sophia will present “Next-level Static Analysis for Vulnerability Research” using the Binary Ninja LLIL at INFILTRATE 2017, which everyone should definitely attend. I hope this guide makes it easier to write your own plugins with Binary Ninja!
In Part 2 of this blog post, I will demonstrate the power of the Low Level IL and its dataflow analysis with another simple example. We will develop a simple, platform-agnostic plugin to navigate to virtual functions by parsing the LLIL for an object’s virtual method table and calculating the offset of the called function pointer. This makes reversing the behavior of C++ binaries easier because instructions such as call [eax+0x10] can be resolved to a known function like object->isValid(). In the meantime, get yourself a copy of Binary Ninja and start using the LLIL.
Update (11 February 2017): A new version of Binary Ninja was released on 10 February 2017; this blog post has been updated to reflect changes to the API.