
Shin GRR: Make Fuzzing Fast Again
Page content

We’ve mentioned GRR before – it’s our high-speed, full-system emulator used to fuzz program binaries. We developed GRR for DARPA’s Cyber Grand Challenge (CGC), and now we’re releasing it as an open-source project! Go check it out.
Fear GRR
Bugs aren’t afraid of slow fuzzers, and that’s why GRR was designed with unique and innovative features that make it tread scarily fast.
- GRR emulates x86 binaries within a 64-bit address space using dynamic binary translation (DBT). As a 64-bit program, GRR can use more hardware registers and memory than the original program. This enabled easy implementation of perfect isolation without complex register-rescheduling or memory remapping logic. The translated program never sees GRR coming.
- GRR is fast. Existing DBTs re-translate the same program on every execution. They specialize in translating long-running programs, where the translation cost is amortized over time, and “hot” code is reorganized to improve performance. Fuzzing campaigns execute the same program over and over again, so all code is hot, and re-translating the same code is wasteful. GRR’s avoids re-translating code by caching it to disk, and it optimizes its the cached code over the lifetime of the fuzzing campaign.
- GRR eats JIT compilers and self-modifying code for breakfast. GRR translates one basic block at a time, and indexes the translated blocks in its cache using “version numbers.” A block’s version number is a Merkle hash of the contents of executable memory. Modifying the contents of an executable page in memory invalidates its hash, thereby triggering re-translation of its code when next executed.
- GRR is efficient. GRR uses program snapshotting to skip over irrelevant setup code that executes before the first input byte is ever read. This saves a lot cycles in a fuzzing campaign with millions or billions of program executions. GRR also avoids kernel roundtrips by emulating system calls and performing all I/O within memory.
- GRR is extensible. GRR supports pluggable input mutators, including Radamsa, and code coverage metrics, which allows you to tune GRR’s behavior to the program being fuzzed. In the CGC, we didn’t know ahead of time what binaries we would get. There is no one-size fits all way of measuring code coverage. GRR’s flexibility let us change how code coverage was measured over time. This made our fuzzer more resilient to different types of programs.
Two fists in the air
Take a look at GRR demolishing this CGC challenge that has six binaries communicating over IPC. GRR detects the crash in the 3rd binary.
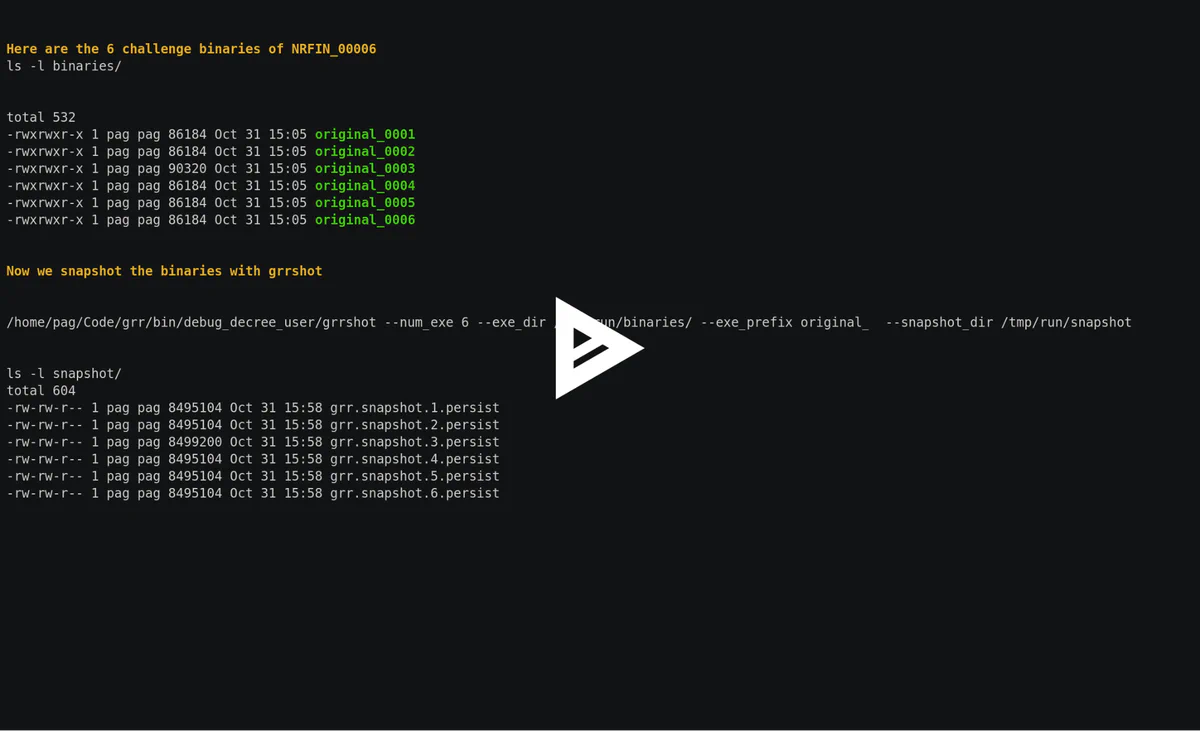
This demo shows off two nifty features of GRR:
- GRR can print out the trace of system calls performed by the translated binary.
- GRR can print out the register state on entry to every basic block executed. Instruction-granularity register traces are available when the maximum basic block size is set to a one instruction.
Dig deeper
I like to think of GRR as an excavator for bugs. It’s a lean, mean, bug-finding machine. It’s also now open-source, and permissively licensed. You should check it out and we welcome contributions.