
The Problem with Dynamic Program Analysis
Developers have access to tools like AddressSanitizer and Valgrind that will tell them when the code that they’re running accesses uninitialized memory, leaks memory, or uses memory after it’s been freed. Despite the availability of these excellent tools, memory bugs still persist, still get shipped to users, and still get exploited in the wild.
Most of today’s bug-finding finding tools are dynamic: they identify bugs in programs while those programs are running. This is great because all programs have massive test suites that exercise every line of code… right? Wrong. Large test suites are the exception, not the rule. Test suites definitely help find and reduce bugs, but bugs still get through.
Perhaps the solution is to pay to have your code audited by professionals. More eyes on your code is a good thing™, but the underlying issue remains. Analyses run inside the heads of experts are still “dynamic”: thinking through every code path is just not tractable.
So dynamic analyses can miss bugs because they can’t check every possible program path. What can check every possible program path?
Finding use-after-frees in millions of lines of code
My stock advice for 2016: SELL integer overflow, BUY use-after-free, and HOLD type confusion pic.twitter.com/UVaxHXA99U
— John Lambert (@JohnLaTwC) January 6, 2016
We use static analysis to analyze millions of lines of code, without ever running the code. The analysis technique, called data-flow tracking, enables us to analyze and summarize properties about every possible program path. This solves the aforementioned problem of missing bugs that occur when certain program paths are not exercised.
How does an analysis that sees everything actually work? Below we describe the 1-2-3 of an actual whole-program static analysis tool that we developed and regularly use. The tool, PointsTo, finds and reports on potential use-after-free bugs in large codebases.
Step 1: Convert to LLVM bitcode
PointsTo operates on the LLVM bitcode representation of a program. We chose LLVM bitcode because it is a convenient intermediate representation for performing program analyses. Unsurprisingly, the first stage of our analysis pipeline converts a program’s source code into an LLVM bitcode database. We use an internal tool named CompInfo to produce these databases. An alternative, open-source tool for doing something similar is whole-program-llvm.
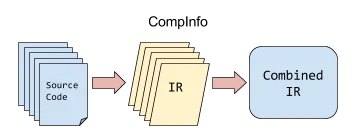
Step 2: Create the data-flow graph
The key idea behind PointsTo is to analyze how pointers to allocated objects flow through the program. What we care about are assignments to and copies of pointers, pointer dereferences, and frees of pointers. These operations on pointers are represented using a data-flow graph.

The most interesting step in the process is the why and how of transforming allocations and frees into special assignments. The “why” is that this transformation lets us repurpose an existing program analysis to find paths from FREE definitions to pointer dereferences. The how is more subtle: how does PointsTo know that it should change “new A” into an ALLOC and “delete a” into a FREE?
Imagine a hypothetical embedded system where programs are starved for memory and so the natural choice is to use a custom memory allocator called ration_memory. We created a Python modelling language to feed PointsTo information about higher-level function behaviors. Our modelling scripts tell PointsTo that “new A” returns a new object, and so we can use it to say the same thing about ration_memory.
Segue: Hidden data flows
The transformation from source code into a data flow graph looked pretty simple, but that was because the source code we started with was simple. It had no function calls, and more importantly, it had no function pointers or method calls! What happens if callback below is a function pointer? What happens if callback frees x?
int *x = malloc(4);
callback(x);
*x += 1;This is the secret sauce and namesake of PointsTo: we perform a context- and path-sensitive pointer analysis that tells us which function pointers point to which functions and when. Altogether, we can produce an error report that follows x through callback and back again.
Step 3: Dénouement
It’s time to report potential errors for expert analysis. PointsTo searches through the data-flow graph, looking for flows from assignments to FREE down to dereferences. These flows are converted into a program slice of the source code lines, showing the path that execution needs to follow in order to produce a use-after-free. Here’s an example program slice of a real bug:

When describing this system to compiler folks, the usual first question is: but what about false-positives? What if we get a report about a use-after-free and it isn’t one? Here is where the priorities of program analysis for compilers and for vulnerabilities diverge.
False-positives in a compiler analysis can introduce bugs, and so compilers are usually conservative. That is, they trade false-positives for false-negatives. They might miss some optimization opportunities because they can’t prove something, but at least the program will be compiled correctly *cough*.
For vulnerability analysis, this is a bad trade. False-positives in a vulnerability analysis are inconvenient, but they’re a drop in the ocean when millions of lines of code need to be looked at. False-negatives, however, are unacceptable. A false-negative is a bug that is missed and might make it to production. A tool that always finds the bug and sometimes warns you about sketchy but correct code is an investment that saves time and money during code audits.
In summary, we conclude
Analyzing programs for bugs is hard. Industry best-practices like having extensive test suites should be followed. Developers should regularly run their programs through dynamic analysis tools to pick the low-hanging fruit. But more importantly, developers should understand that test suites and dynamic analyses are not a panacea. Bugs have a nasty habit of hiding behind rarely executed code paths. That’s why all paths need to be looked at. That’s why we made PointsTo.
PointsTo was a topic of discussion at a recent Empire Hacking, a bi-monthly meetup in NYC. The talk I gave there includes more information about the design and implementation of PointsTo and, for curious readers, the slides and video are reproduced below. We hope to release more videos from Empire Hacking in the future.
PointsTo was originally produced for Cyber Fast Track and we would like to thank DARPA for funding our work. Consultants at Trail of Bits use PointsTo and other internal tools for application security reviews. Contact us if you’re interested in a detailed audit of your code supported by tools like PointsTo and our CRS.