
How We Fared in the Cyber Grand Challenge
The Cyber Grand Challenge qualifying event was held on June 3rd, at exactly noon Eastern time. At that instant, our Cyber Reasoning System (CRS) was given 131 purposely built insecure programs. During the following 24 hour period, our CRS was able to identify vulnerabilities in 65 of those programs and rewrite 94 of them to eliminate bugs built in their code. This proves, without a doubt, that it is not only possible but achievable to automate the actions of a talented software auditor.
Despite the success of our CRS at finding and patching vulnerabilities, we did not qualify for the final event, to be held next year. There was a fatal flaw that lowered our overall score to 9th, below the 7th place threshold for qualification. In this blog post we’ll discuss how our CRS works, how it performed against competitor systems, what doomed its score, and what we are going to do next.
Cyber Grand Challenge Background
The goal of the Cyber Grand Challenge (CGC) is to combine the speed and scale of automation with the reasoning capabilities of human experts. Multiple teams create Cyber Reasoning Systems (CRSs) that autonomously reason about arbitrary networked programs, prove the existence of flaws in those programs, and automatically formulate effective defenses against those flaws. How well these systems work is evaluated through head-to-head tournament-style competition.
The competition has two main events: the qualifying event and the final event. The qualifying event was held on June 3, 2015. The final event is set to take place during August 2016. Only the top 7 competitors from the qualifying event proceed to the final event.
During the qualifying event, each competitor was given the same 131 challenges, or purposely built vulnerable programs, each of which contained at least one intentional vulnerability. For 24 hours, the competing CRSes faced off against each other and were scored according to four criteria. The full details are in the CGC Rules, but here’s a quick summary:
- The CRS had to work without human intervention. Any teams found to use human assistance were disqualified.
- The CRS had to patch bugs in challenges. Points were gained for every bug successfully patched. Challenges with no patched bugs received zero points.
- The CRS could prove bugs exist in challenges. The points from patched challenges were doubled if the CRS could generate an input that crashed the challenge.
- The patched challenges had to function and perform almost as well as the originals. Points were lost based on performance and functionality loss in the patched challenges.
A spreadsheet with all the qualifying event scores and other data used to make the graphs in this post is available from DARPA (Trail of Bits is the ninth place team). With the scoring in mind, let’s review the Trail of Bits CRS architecture and the design decisions we made.
Preparation
We’re a small company with a distributed workforce, so we couldn’t physically host a lot of servers. Naturally, we went with cloud computing to do processing; specifically, Amazon EC2. Those who saw our tweets know we used a lot of EC2 time. Most of that usage was purely out of caution.
We didn’t know how many challenges would be in the qualifying event — just that it would be “more than 100.” We prepared for a thousand, with each accompanied by multi-gigabyte network traffic captures. We were also terrified of an EC2 region-wide failure, so we provisioned three different CRS instances, one in each US-based EC2 region, affectionately named Biggie (us-east-1), Tupac (us-west-2), and Dre (us-west-1).
It turns out that there were only 131 challenges and no gigantic network captures in the qualifying event. During the qualifying event, all EC2 regions worked normally. We could have comfortably done the qualifying event with 17 c4.8xlarge EC2 instances, but instead we used 297. Out of our abundance of caution, we over-provisioned by a factor of ~17x.
Bug Finding
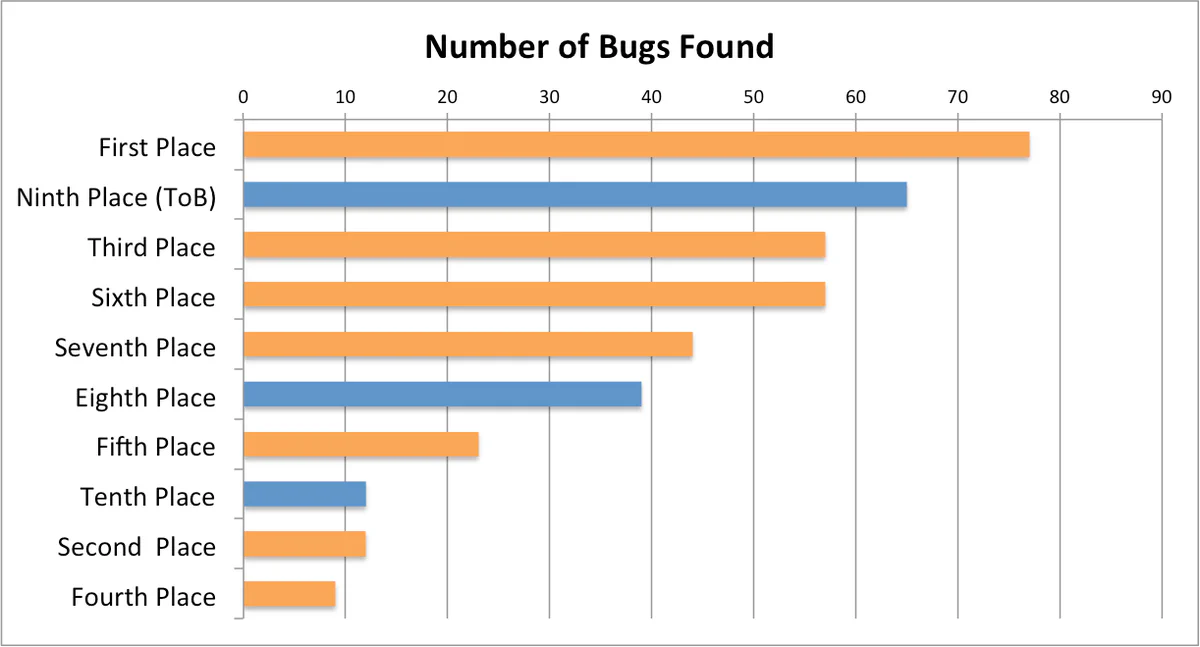
The Trail of Bits CRS was ranked second by the number of verified bugs found (Figure 1). This result is impressive considering that we started with nothing while several other teams already had existing bug finding systems prior to CGC.
Our CRS used a multi-pronged strategy to find bugs (Figure 2). First, there was fuzzing. Our fuzzer is implemented with a custom dynamic binary translator (DBT) capable of running several 32-bit challenges in a single 64-bit address space. This is ideal for challenges that feature multiple binaries communicating with one another. The fuzzer’s instrumentation and mutation are separated, allowing for pluggable mutation strategies. The DBT framework can also snapshot binaries at any point during execution. This greatly improves fuzzing speed, since it’s possible to avoid replaying previous inputs when exploring new input space.
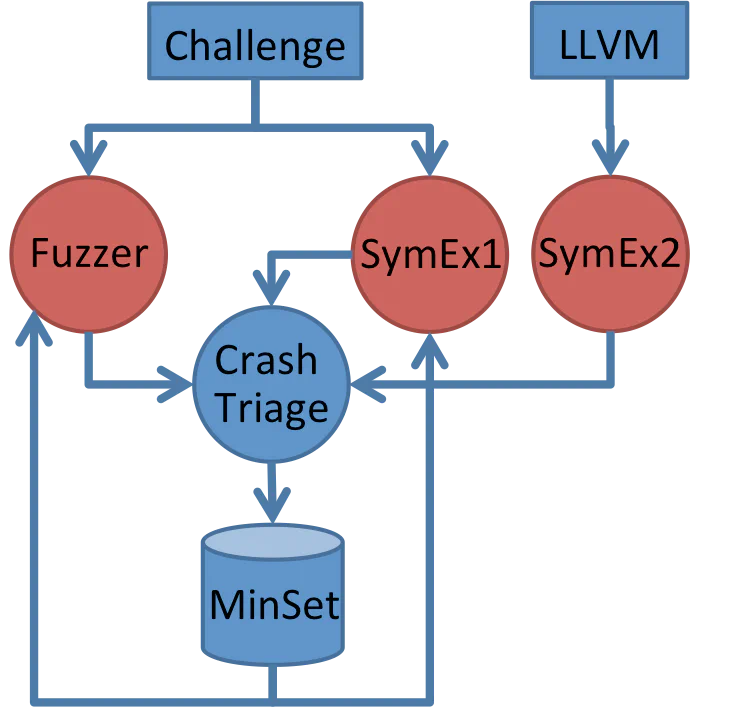
In addition to fuzzing, we had not one but two symbolic execution engines. The first operated on the original unmodified binaries, and the second operated on the translated LLVM from mcsema. Each symbolic execution engine had its own strengths, and both contributed to bug finding.
The fuzzer and symbolic execution engines operate in a feedback loop mediated by a system we call MinSet. The MinSet uses branch coverage to maintain a minimum set of maximal coverage inputs. The inputs come from any source capable of generating them: PCAPs, fuzzing, symbolic execution, etc. Every tool gets original inputs from MinSet, and feeds any newly generated inputs into MinSet. This feedback loop lets us explore the possible input state with both fuzzers and symbolic execution in parallel. In practice this is very effective. We log the provenance of our crashes, and most of them look something like:
Network Capture ⇒ Fuzzer ⇒ SymEx1 ⇒ Fuzzer ⇒ Crash
Some bugs can only be triggered when the input replays a previous nonce, which would be different on every execution of the challenge. Our bug finding system can produce inputs that contain variables based on program outputs, enabling our CRS to handle such cases.
Additionally, our symbolic executors are able to identify which inputs affect program state at the point of a crash. This is a key requirement for the success of any team competing in the final as it enables the CRS to create a more controlled crash.
Patching
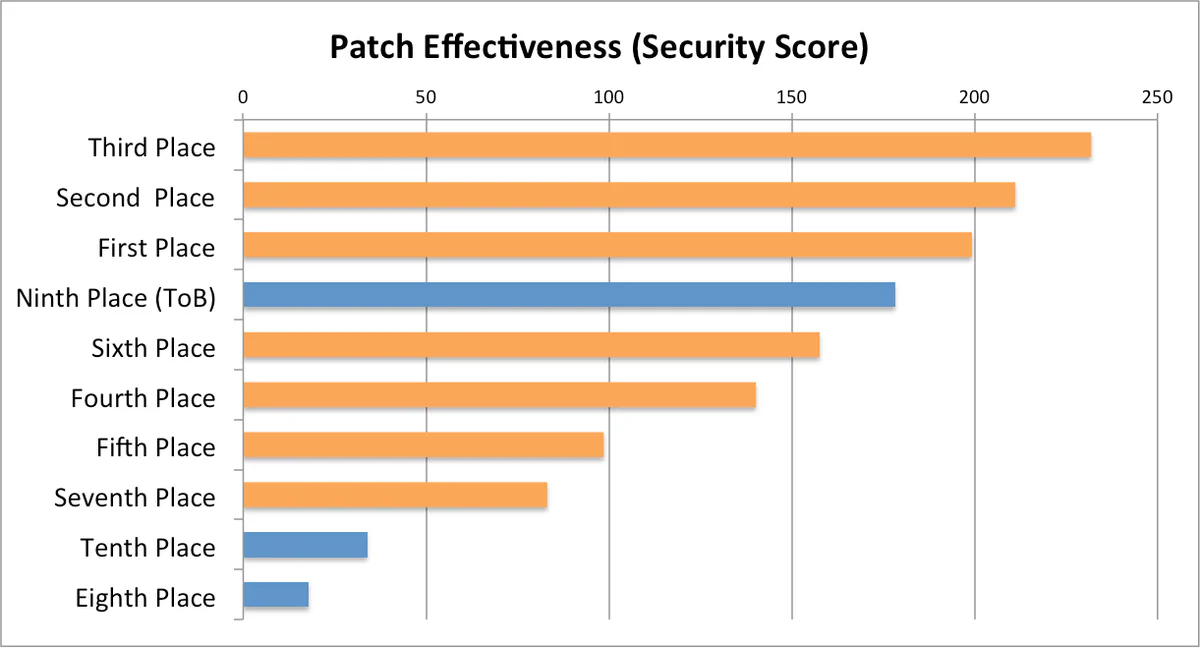
Our CRS’s patching effectiveness, as measured by the security score, ranks as fourth (Figure 3).
Our CRS patches bugs by translating challenges into LLVM bitcode with mcsema. Patches are applied to the LLVM bitcode, optimized, and then converted back into executable code. The actual patching works by gracefully terminating the challenge when invalid memory accesses are detected. Patching the LLVM bitcode representation of challenges provides us with enormous power and flexibility:
- We can easily validate any memory access and keep track of all memory allocations.
- Complex algorithms, such as dataflow tracking, dominator trees, dead store elimination, loop detection, etc., are very simple to implement using the LLVM compiler infrastructure.
- Our patching method can be used on real-world software, not just CGC challenges.
We created two main patching strategies: generic patching and bug-based patching. Generic patching is an exclusion-based strategy: it first assumes that every memory access must be verified, and then excludes accesses that are provably safe. The benefit of generic patching is that it patches all possible invalid memory accesses in a challenge. Bug-based patching is an inclusion-based strategy: it first assumes only one memory access (where the CRS found a bug) must be verified, and then includes nearby accesses that may be unsafe. Each patching strategy has multiple heuristics to determine which accesses should be included or excluded from verification.
The inclusion and exclusion heuristics generate patched challenges with different security/performance tradeoffs. The patched challenges generated by these heuristics were tested for performance and security to determine which heuristic performed best while still fixing the bug. For the qualifying event, we evaluated both generic and bug-based patching, but ultimately chose a generic-only patching strategy. Bug-based patching was slightly more performant, but generic patching was more comprehensive and it patched bugs that our CRS couldn’t find.
Functionality and Performance
Functionality and performance scores combine to create an availability score. The availability score is used as a scaling factor for points gained by patching and bug finding. This scaling factor only matters for successfully patched challenges, since those are the only challenges that can score points. The following graphs only consider functionality and performance of successfully patched challenges.
Functionality
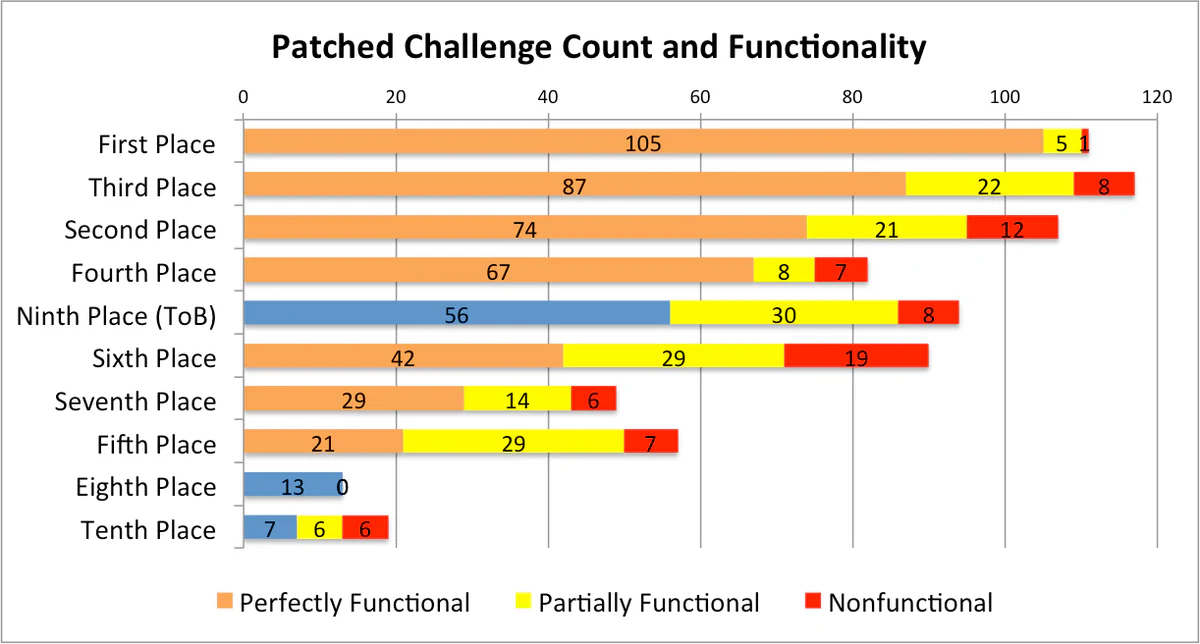
Out of the 94 challenges that our CRS successfully patched, 56 retained full functionality, 30 retained partial functionality, and 8 were nonfunctional. Of the top 10 teams in the qualifying event, our CRS ranks 5th in terms of fully functional patched challenges (Figure 4). We suspect our patched challenges lost functionality due to problems in mcsema, our x86 to LLVM translator. We hope to verify and address these issues once DARPA open-sources the qualifying event challenges.
Performance
The performance of patched challenges is how our CRS snatched defeat from the jaws of victory. Of the top ten teams in the qualifying event, our CRS placed last in terms of patched challenge performance (Figure 5).
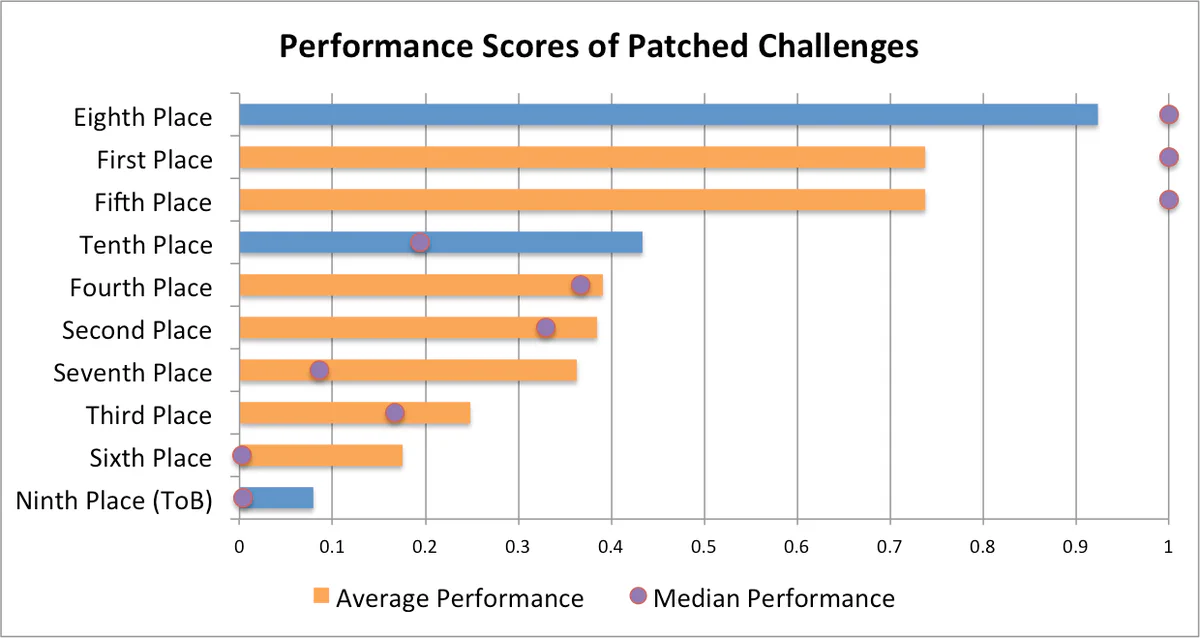
Our CRS produces slow binaries for two reasons: technical and operational. The technical reason is that performance of our patched challenges is an artifact of our patching process, which translates challenges into LLVM bitcode and then re-emits them as executable binaries. The operational reason is that our patching was developed late and optimized for the wrong performance measurements.
So, why did we optimize for the wrong performance measurements? The official CGC performance measurement tools were kept secret, because the organizers wanted to ensure that no one could cheat by gaming the performance measurements. Therefore, we had to measure performance ourselves, and our metrics showed that CPU overhead of our patched challenges was usually negligible. The main flaw that we observed was that our patched challenges used too much memory. Because of this, we spent time and effort optimizing our patching to use less memory in favor of using more CPU time.
It turns out we optimized for the wrong thing, because our self-measurement did not agree with the official measurement tools (Table 1). When self-measuring, our worst-performing patching method had a median CPU overhead of 33% and a median memory overhead of 69%. The official qualifying event measured us at 76% CPU overhead and 28% memory overhead. Clearly, our self-measurements were considerably different from official measurements.
| Measurement | Median CPU Overhead | Median Memory Overhead |
|---|---|---|
| Worst Self-Measured Patching Method | 33% | 69% |
| Official Qualifying Event | 76% | 28% |
Table 1: Self measured CPU and memory overhead and the official qualifying event CPU and memory overhead.
Our CRS measured its overall score with our own performance metrics. The self-measured score of our CRS was 106, which would have put us in second place. The real overall score was 21.36, putting us in ninth.
An important aspect of software development is choosing where to focus your efforts, and we chose poorly. CGC participants had access to the official measuring system during two scored events held during the year, one in December 2014 and one in April 2015. We should have evaluated our patching system thoroughly during both scored events. Unfortunately, our patching wasn’t fully operational until after the second scored event, so we had no way to verify the accuracy of our self-measurement. The performance penalty of our patching isn’t a fundamental issue. Had we known how bad it was, we would have fixed it. However, according to our own measurements the patching was acceptable so we focused efforts elsewhere.
What’s Next?
According to the CGC FAQ (Question 46), teams are allowed to combine after the qualifying event. We hope to join forces with another team that qualified for the CGC final event, and use the best of both our technologies to win. The technology behind our CRS will provide a significant advantage to any team that partners with us. If you would like to discuss a potential partnership for the CGC final, please contact us at [email protected].
If we cannot find a partner for the CGC final, we will focus our efforts on adapting our CRS to automatically find and patch vulnerabilities in real software. Our system is up to the task: it has already proven that it can find bugs, and all of its core components were derived from software that works on real Linux binaries. Several components even have Windows and 64-bit support, and adding support for other platforms is a possibility. If you are interested in commercial applications of our technology, please get in touch with us at [email protected].
Finally, we plan to contribute back fixes and updates to the open source projects utilized in our CRS. We used numerous open source projects during development, and have made several custom fixes and modifications. We look forward to contributing these back to the community so that everyone benefits from our improvements.