
A Preview of McSema
On June 28th Artem Dinaburg and Andrew Ruef will be speaking at REcon 2014 about a project named McSema. McSema is a framework for translating x86 binaries into LLVM bitcode. This translation is the opposite of what happens inside a compiler. A compiler translates LLVM bitcode to x86 machine code. McSema translates x86 machine code into LLVM bitcode.
Why would we do such a crazy thing?
Because we wanted to analyze existing binary applications, and reasoning about LLVM bitcode is much easier than reasoning about x86 instructions. Not only is it easier to reason about LLVM bitcode, but it is easier to manipulate and re-target bitcode to a different architecture. There are many program analysis tools (e.g. KLEE, PAGAI, LLBMC) written to work on LLVM bitcode that can now be used on existing applications. Additionally it becomes much simpler to transform applications in complex ways while maintaining original application functionality.
McSema brings the world of LLVM program analysis and manipulation tools to binary executables. There are other x86 to LLVM bitcode translators, but McSema has several advantages:
- McSema separates control flow recovery from translation, permitting the use of custom control flow recovery front-ends.
- McSema supports FPU instructions.
- McSema is open source and licensed under a permissive license.
- McSema is documented, works, and will be available soon after our REcon talk.
This blog post will be a preview of McSema and will examine the challenges of translating a simple function that uses floating point arithmetic from x86 instructions to LLVM bitcode. The function we will translate is called timespi. It it takes one argument, k and returns the value of k * PI. Source code for timespi is below.
long double timespi(long double k) {
long double pi = 3.14159265358979323846;
return k*pi;
}When compiled with Microsoft Visual Studio 2010, the assembly looks like the IDA Pro screenshot below.
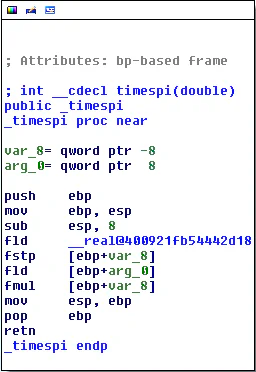
After translating to LLVM bitcode with McSema and then re-emitting the bitcode as an x86 binary, the assembly looks much different.
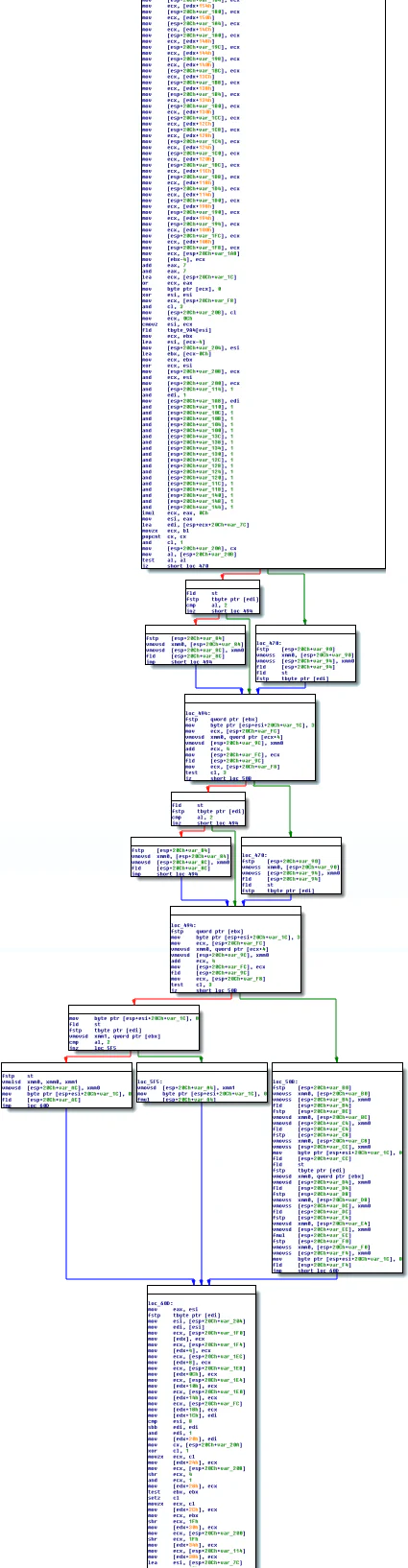
You may be saying to yourself: “Wow, that much code bloat for such a small function? What are these guys doing?”
We specifically wanted to use this example because it shows floating point support — functionality that is unique to McSema, and because it showcases difficulties inherent in x86 to LLVM bitcode translation.
Translation Background
McSema models x86 instructions as operations on a register context. That is, there is a register context structure that contains all registers and flags and an instruction semantics are expressed as modifications of structure members. This concept is easiest to understand with a simplified pseudocode example. An operation such as ADD EAX, EBX would be translated to context[EAX] += context[EBX].
Translation Difficulties
Now let’s examine why a small function like timespi presents serious translation challenges.
The value of PI is read from the data section
Control flow recovery must detect that the first FLD instruction references data and correctly identify the data size. McSema separates control flow recovery from translation, and hence can leverage IDA’s excellent CFG recovery via an IDAPython script.
The translation needs to support x86 FPU registers, FPU flags, and control bits
The FPU registers aren’t like integer registers. Integer registers (EAX, ECX, EBX, etc.) are named and independent. Instructions referencing EAX will always refer to the same place in a register context.
FPU registers are a stack of 8 data registers (ST(0) through ST(7)), indexed by the TOP flag. Instructions referencing ST(i) actually refer to st_registers[(TOP + i) % 8] in a register context.

Integer registers are defined solely by register contents. FPU registers are partially defined by register contents and partially by the FPU tag word. The FPU tag word is a bitmap that defines whether the contents of a floating point register are:
- Valid (that is, a normal floating point value)
- The value zero
- A special value such as NaN or Infinity
- Empty (the register is unused)
To determine the value of an FPU register, one must consult both the FPU tag word and the register contents.
The translation needs to support at least the FLD, FSTP, and FMUL instructions
The actual instruction operation such as loads, stores, and multiplication is fairly straightforward to support. The difficult part is implementing FPU execution semantics.
For instance, the FPU stores state about FPU instructions, like:
- Last Instruction Pointer: the location of the last executed FPU instruction
- Last Data Pointer: the address of the latest memory operand to an FPU instruction
- Opcode: The opcode of the last executed FPU instruction
Some of these concepts are easier to translate to LLVM bitcode than others. Storing the address of the last memory operand translates very well: if the translated instruction references memory, store the memory address in the last data pointer field of the register context. Other concepts simply don’t translate. As an example, what does the “last instruction pointer” mean when a single FPU instruction is translated into multiple LLVM operations?
Self-referencing state isn’t the end of translation difficulties. FPU flags like the precision control and rounding control flags affect instruction operation. The precision control flag affects arithmetic operation, not the precision of stored registers. So one can load a double extended precision values in ST(0) and ST(1) via FLD, but FMUL may store a single precision result in ST(0).
Translation Steps
Now that we’ve explored the difficulties of translation, let’s look at the steps needed to translate just the core of timespi, the FMUL instruction. The IA-32 Software Development Manual manual defines this instance of FMUL as “Multiply ST(0) by m64fp and store result in ST(0).” Below are just some of the steps required to translate FMUL to LLVM bitcode.
- Check the FPU tag word for
ST(0), make sure its not empty. - Read the
TOPflag. - Read the value from
st_registers[TOP]. Unless the FPU tag word said the value is zero, in which case just read a zero. - Load the value pointed to by
m64fp. - Do the multiplication.
- Check the precision control flag. Adjust the result precision of the result as needed.
- Write the adjusted result into
st_registers[TOP]. - Update the FPU tag word for
ST(0)to match the result. Maybe we multiplied by zero? - Update FPU status flags in the register context. For
FMUL, this is just theC1flag. - Update the last FPU opcode field
- Did our instruction reference data? Sure did! Update the last FPU data field to
m64fp. - Skip updating the last FPU instruction field since it doesn’t really map to LLVM bitcode… for now
Thats a lot of work for a single instruction, and the list isn’t even complete. In addition to the work of translating raw instructions, there are additional steps that must be taken on function entry and exit points, for external calls and for functions that have their address taken. Those additional details will be covered during the REcon talk.
Conclusion
Translating floating point operations is a tricky, difficult business. Seemingly simple floating point instructions hide numerous operations and translate to a large amount of LLVM bitcode. The translated code is large because McSema exposes the hidden complexity of floating point operations. Considering that there have been no attempts to optimize instruction translation, we think the current output is pretty good.
For a more detailed look at McSema, attend Artem and Andrew’s talk at REcon and keep following the Trail of Bits blog for more announcements.
EDIT: McSema is now open-source. See our announcement for more information.